 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Normalization for Bi-directional Amharic-English Neural Machine Translation
Paper and Code


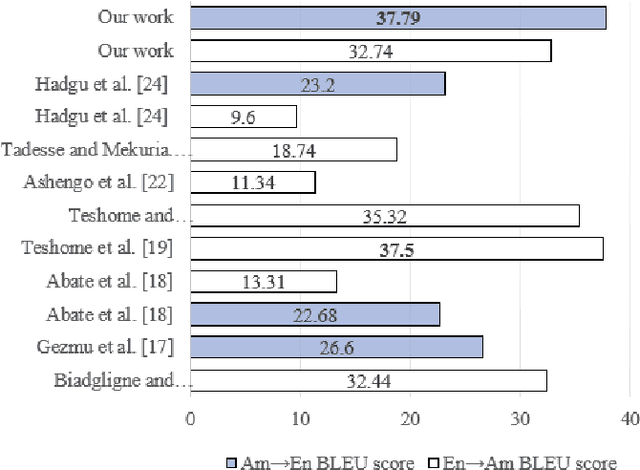

Machine translation (MT) is one of the main tasks in natural language processing whose objective is to translate texts automatically from one natural language to another. Nowadays, using deep neural networks for MT tasks has received great attention. These networks require lots of data to learn abstract representations of the input and store it in continuous vectors. This paper presents the first relatively large-scale Amharic-English parallel sentence dataset. Using these compiled data, we build bi-directional Amharic-English translation models by fine-tuning the existing Facebook M2M100 pre-trained model achieving a BLEU score of 37.79 in Amharic-English 32.74 in English-Amharic translation. Additionally, we explore the effects of Amharic homophone normalization on the machine translation task. The results show that the normalization of Amharic homophone characters increases the performance of Amharic-English machine translation in both directions.