 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfriNLLB: Efficient Translation Models for African Languages
Feb 10, 2026In this work, we present AfriNLLB, a series of lightweight models for efficient translation from and into African languages. AfriNLLB supports 15 language pairs (30 translation directions), including Swahili, Hausa, Yoruba, Amharic, Somali, Zulu, Lingala, Afrikaans, Wolof, and Egyptian Arabic, as well as other African Union official languages such as Arabic (MSA), French, Portuguese, and Spanish. Our training data covers bidirectional translation between English and 13 languages, and between French and two languages (Lingala and Wolof). AfriNLLB models are based on NLLB-200 600M, which we compress using iterative layer pruning and quantization. We fine-tune the pruned models on parallel corpora we curated for African languages, employing knowledge distillation from a larger teacher model. Our work aims at enabling efficient deployment of translation models for African languages in resource-constrained settings. Our evaluation results demonstrate that AfriNLLB models achieve performance comparable to the baseline while being significantly faster. We release two versions of the AfriNLLB models, a Transformers version that allows further fine-tuning and a CTranslate2 version for efficient inference. Moreover, we release all the training data that we used for fine-tuning the baseline and pruned models to facilitate further research.
* Accepted at AfricaNLP 2026 (oral)
Bemba Speech Translation: Exploring a Low-Resource African Language
May 05, 2025



This paper describes our system submission to the International Conference on Spoken Language Translation (IWSLT 2025), low-resource languages track, namely for Bemba-to-English speech translation. We built cascaded speech translation systems based on Whisper and NLLB-200, and employed data augmentation techniques, such as back-translation. We investigate the effect of using synthetic data and discuss our experimental setup.
Domain-Specific Translation with Open-Source Large Language Models: Resource-Oriented Analysis
Dec 08, 2024



In this work, we compare the domain-specific translation performance of open-source autoregressive decoder-only large language models (LLMs) with task-oriented machine translation (MT) models. Our experiments focus on the medical domain and cover four language pairs with varied resource availability: English-to-French, English-to-Portuguese, English-to-Swahili, and Swahili-to-English. Despite recent advancements, LLMs exhibit a clear gap in specialized translation quality compared to multilingual encoder-decoder MT models such as NLLB-200. In three out of four language directions in our study, NLLB-200 3.3B outperforms all LLMs in the size range of 8B parameters in medical translation. While fine-tuning LLMs such as Mistral and Llama improves their performance at medical translation, these models still fall short compared to fine-tuned NLLB-200 3.3B models. Our findings highlight the ongoing need for specialized MT models to achieve higher-quality domain-specific translation, especially in medium-resource and low-resource settings. As larger LLMs outperform their 8B variants, this also encourages pre-training domain-specific medium-sized LMs to improve quality and efficiency in specialized translation tasks.
Enhancing Amharic-LLaMA: Integrating Task Specific and Generative Datasets
Feb 12, 2024Large language models (LLMs) have received a lot of attention in natural language processing (NLP) research because of their exceptional performance in understanding and generating human languages. However, low-resource languages are left behind due to the unavailability of resources. In this work, we focus on enhancing the LLaMA-2-Amharic model by integrating task-specific and generative datasets to improve language model performance for Amharic. We compile an Amharic instruction fine-tuning dataset and fine-tuned LLaMA-2-Amharic model. The fine-tuned model shows promising results in different NLP tasks. We open-source our dataset creation pipeline, instruction datasets, trained models, and evaluation outputs to promote language-specific studies on these models.
Machine Translation for Ge'ez Language
Nov 24, 2023
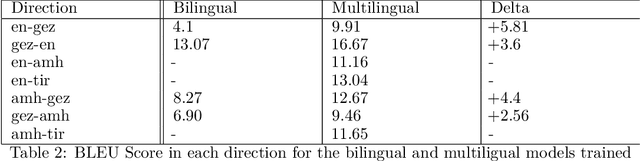
Machine translation (MT) for low-resource languages such as Ge'ez, an ancient language that is no longer spoken in daily life, faces challenges such as out-of-vocabulary words, domain mismatches, and lack of sufficient labeled training data. In this work, we explore various methods to improve Ge'ez MT, including transfer-learning from related languages, optimizing shared vocabulary and token segmentation approaches, finetuning large pre-trained models, and using large language models (LLMs) for few-shot translation with fuzzy matches. We develop a multilingual neural machine translation (MNMT) model based on languages relatedness, which brings an average performance improvement of about 4 BLEU compared to standard bilingual models. We also attempt to finetune the NLLB-200 model, one of the most advanced translation models available today, but find that it performs poorly with only 4k training samples for Ge'ez. Furthermore, we experiment with using GPT-3.5, a state-of-the-art LLM, for few-shot translation with fuzzy matches, which leverages embedding similarity-based retrieval to find context examples from a parallel corpus. We observe that GPT-3.5 achieves a remarkable BLEU score of 9.2 with no initial knowledge of Ge'ez, but still lower than the MNMT baseline of 15.2. Our work provides insights into the potential and limitations of different approaches for low-resource and ancient language MT.