 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Layer Pruning for Efficient Translation Inference
Oct 26, 2025Large language models (LLMs) have transformed many areas of natural language processing, including machine translation. However, efficient deployment of LLMs remains challenging due to their intensive computational requirements. In this paper, we address this challenge and present our submissions to the Model Compression track at the Conference on Machine Translation (WMT 2025). In our experiments, we investigate iterative layer pruning guided by layer importance analysis. We evaluate this method using the Aya-Expanse-8B model for translation from Czech to German, and from English to Egyptian Arabic. Our approach achieves substantial reductions in model size and inference time, while maintaining the translation quality of the baseline models.
* WMT 2025
Efficient Speech Translation through Model Compression and Knowledge Distillation
May 26, 2025Efficient deployment of large audio-language models for speech translation remains challenging due to their significant computational requirements. In this paper, we address this challenge through our system submissions to the "Model Compression" track at the International Conference on Spoken Language Translation (IWSLT 2025). We experiment with a combination of approaches including iterative layer pruning based on layer importance evaluation, low-rank adaptation with 4-bit quantization (QLoRA), and knowledge distillation. In our experiments, we use Qwen2-Audio-7B-Instruct for speech translation into German and Chinese. Our pruned (student) models achieve up to a 50% reduction in both model parameters and storage footprint, while retaining 97-100% of the translation quality of the in-domain (teacher) models.
Bemba Speech Translation: Exploring a Low-Resource African Language
May 05, 2025



This paper describes our system submission to the International Conference on Spoken Language Translation (IWSLT 2025), low-resource languages track, namely for Bemba-to-English speech translation. We built cascaded speech translation systems based on Whisper and NLLB-200, and employed data augmentation techniques, such as back-translation. We investigate the effect of using synthetic data and discuss our experimental setup.
SpeechT: Findings of the First Mentorship in Speech Translation
Feb 17, 2025This work presents the details and findings of the first mentorship in speech translation (SpeechT), which took place in December 2024 and January 2025. To fulfil the requirements of the mentorship, the participants engaged in key activities, including data preparation, modelling, and advanced research.
Domain-Specific Translation with Open-Source Large Language Models: Resource-Oriented Analysis
Dec 08, 2024



In this work, we compare the domain-specific translation performance of open-source autoregressive decoder-only large language models (LLMs) with task-oriented machine translation (MT) models. Our experiments focus on the medical domain and cover four language pairs with varied resource availability: English-to-French, English-to-Portuguese, English-to-Swahili, and Swahili-to-English. Despite recent advancements, LLMs exhibit a clear gap in specialized translation quality compared to multilingual encoder-decoder MT models such as NLLB-200. In three out of four language directions in our study, NLLB-200 3.3B outperforms all LLMs in the size range of 8B parameters in medical translation. While fine-tuning LLMs such as Mistral and Llama improves their performance at medical translation, these models still fall short compared to fine-tuned NLLB-200 3.3B models. Our findings highlight the ongoing need for specialized MT models to achieve higher-quality domain-specific translation, especially in medium-resource and low-resource settings. As larger LLMs outperform their 8B variants, this also encourages pre-training domain-specific medium-sized LMs to improve quality and efficiency in specialized translation tasks.
Leveraging Synthetic Audio Data for End-to-End Low-Resource Speech Translation
Jun 25, 2024This paper describes our system submission to the International Conference on Spoken Language Translation (IWSLT 2024) for Irish-to-English speech translation. We built end-to-end systems based on Whisper, and employed a number of data augmentation techniques, such as speech back-translation and noise augmentation. We investigate the effect of using synthetic audio data and discuss several methods for enriching signal diversity.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024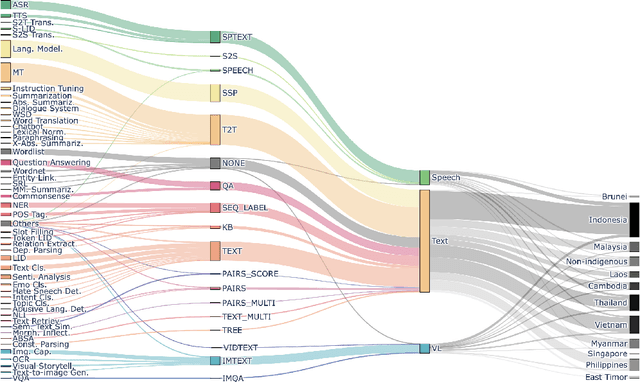
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
Language Modelling Approaches to Adaptive Machine Translation
Jan 25, 2024Consistency is a key requirement of high-quality translation. It is especially important to adhere to pre-approved terminology and adapt to corrected translations in domain-specific projects. Machine translation (MT) has achieved significant progress in the area of domain adaptation. However, in-domain data scarcity is common in translation settings, due to the lack of specialised datasets and terminology, or inconsistency and inaccuracy of available in-domain translations. In such scenarios where there is insufficient in-domain data to fine-tune MT models, producing translations that are consistent with the relevant context is challenging. While real-time adaptation can make use of smaller amounts of in-domain data to improve the translation on the fly, it remains challenging due to supported context limitations and efficiency constraints. Large language models (LLMs) have recently shown interesting capabilities of in-context learning, where they learn to replicate certain input-output text generation patterns, without further fine-tuning. Such capabilities have opened new horizons for domain-specific data augmentation and real-time adaptive MT. This work attempts to address two main relevant questions: 1) in scenarios involving human interaction and continuous feedback, can we employ language models to improve the quality of adaptive MT at inference time? and 2) in the absence of sufficient in-domain data, can we use pre-trained large-scale language models to improve the process of MT domain adaptation?
Fine-tuning Large Language Models for Adaptive Machine Translation
Dec 20, 2023This paper presents the outcomes of fine-tuning Mistral 7B, a general-purpose large language model (LLM), for adaptive machine translation (MT). The fine-tuning process involves utilising a combination of zero-shot and one-shot translation prompts within the medical domain. The primary objective is to enhance real-time adaptive MT capabilities of Mistral 7B, enabling it to adapt translations to the required domain at inference time. The results, particularly for Spanish-to-English MT, showcase the efficacy of the fine-tuned model, demonstrating quality improvements in both zero-shot and one-shot translation scenarios, surpassing Mistral 7B's baseline performance. Notably, the fine-tuned Mistral outperforms ChatGPT "gpt-3.5-turbo" in zero-shot translation while achieving comparable one-shot translation quality. Moreover, the zero-shot translation of the fine-tuned Mistral matches NLLB 3.3B's performance, and its one-shot translation quality surpasses that of NLLB 3.3B. These findings emphasise the significance of fine-tuning efficient LLMs like Mistral 7B to yield high-quality zero-shot translations comparable to task-oriented models like NLLB 3.3B. Additionally, the adaptive gains achieved in one-shot translation are comparable to those of commercial LLMs such as ChatGPT. Our experiments demonstrate that, with a relatively small dataset of 20,000 segments that incorporate a mix of zero-shot and one-shot prompts, fine-tuning significantly enhances Mistral's in-context learning ability, especially for real-time adaptive MT.
Domain Terminology Integration into Machine Translation: Leveraging Large Language Models
Oct 22, 2023This paper discusses the methods that we used for our submissions to the WMT 2023 Terminology Shared Task for German-to-English (DE-EN), English-to-Czech (EN-CS), and Chinese-to-English (ZH-EN) language pairs. The task aims to advance machine translation (MT) by challenging participants to develop systems that accurately translate technical terms, ultimately enhancing communication and understanding in specialised domains. To this end, we conduct experiments that utilise large language models (LLMs) for two purposes: generating synthetic bilingual terminology-based data, and post-editing translations generated by an MT model through incorporating pre-approved terms. Our system employs a four-step process: (i) using an LLM to generate bilingual synthetic data based on the provided terminology, (ii) fine-tuning a generic encoder-decoder MT model, with a mix of the terminology-based synthetic data generated in the first step and a randomly sampled portion of the original generic training data, (iii) generating translations with the fine-tuned MT model, and (iv) finally, leveraging an LLM for terminology-constrained automatic post-editing of the translations that do not include the required terms. The results demonstrate the effectiveness of our proposed approach in improving the integration of pre-approved terms into translations. The number of terms incorporated into the translations of the blind dataset increases from an average of 36.67% with the generic model to an average of 72.88% by the end of the process. In other words, successful utilisation of terms nearly doubles across the three language pairs.