 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Large Language Models for Adaptive Machine Translation
Dec 20, 2023This paper presents the outcomes of fine-tuning Mistral 7B, a general-purpose large language model (LLM), for adaptive machine translation (MT). The fine-tuning process involves utilising a combination of zero-shot and one-shot translation prompts within the medical domain. The primary objective is to enhance real-time adaptive MT capabilities of Mistral 7B, enabling it to adapt translations to the required domain at inference time. The results, particularly for Spanish-to-English MT, showcase the efficacy of the fine-tuned model, demonstrating quality improvements in both zero-shot and one-shot translation scenarios, surpassing Mistral 7B's baseline performance. Notably, the fine-tuned Mistral outperforms ChatGPT "gpt-3.5-turbo" in zero-shot translation while achieving comparable one-shot translation quality. Moreover, the zero-shot translation of the fine-tuned Mistral matches NLLB 3.3B's performance, and its one-shot translation quality surpasses that of NLLB 3.3B. These findings emphasise the significance of fine-tuning efficient LLMs like Mistral 7B to yield high-quality zero-shot translations comparable to task-oriented models like NLLB 3.3B. Additionally, the adaptive gains achieved in one-shot translation are comparable to those of commercial LLMs such as ChatGPT. Our experiments demonstrate that, with a relatively small dataset of 20,000 segments that incorporate a mix of zero-shot and one-shot prompts, fine-tuning significantly enhances Mistral's in-context learning ability, especially for real-time adaptive MT.
Domain Terminology Integration into Machine Translation: Leveraging Large Language Models
Oct 22, 2023This paper discusses the methods that we used for our submissions to the WMT 2023 Terminology Shared Task for German-to-English (DE-EN), English-to-Czech (EN-CS), and Chinese-to-English (ZH-EN) language pairs. The task aims to advance machine translation (MT) by challenging participants to develop systems that accurately translate technical terms, ultimately enhancing communication and understanding in specialised domains. To this end, we conduct experiments that utilise large language models (LLMs) for two purposes: generating synthetic bilingual terminology-based data, and post-editing translations generated by an MT model through incorporating pre-approved terms. Our system employs a four-step process: (i) using an LLM to generate bilingual synthetic data based on the provided terminology, (ii) fine-tuning a generic encoder-decoder MT model, with a mix of the terminology-based synthetic data generated in the first step and a randomly sampled portion of the original generic training data, (iii) generating translations with the fine-tuned MT model, and (iv) finally, leveraging an LLM for terminology-constrained automatic post-editing of the translations that do not include the required terms. The results demonstrate the effectiveness of our proposed approach in improving the integration of pre-approved terms into translations. The number of terms incorporated into the translations of the blind dataset increases from an average of 36.67% with the generic model to an average of 72.88% by the end of the process. In other words, successful utilisation of terms nearly doubles across the three language pairs.
Adaptive Machine Translation with Large Language Models
Jan 30, 2023Consistency is a key requirement of high-quality translation. It is especially important to adhere to pre-approved terminology and corrected translations in domain-specific projects. Machine translation (MT) has achieved significant progress in the area of domain adaptation. However, real-time adaptation remains challenging. Large-scale language models (LLMs) have recently shown interesting capabilities of in-context learning, where they learn to replicate certain input-output text generation patterns, without further fine-tuning. By feeding an LLM with a prompt that consists of a list of translation pairs, it can then simulate the domain and style characteristics at inference time. This work aims to investigate how we can utilize in-context learning to improve real-time adaptive MT. Our extensive experiments show promising results at translation time. For example, GPT-3.5 can adapt to a set of in-domain sentence pairs and/or terminology while translating a new sentence. We observe that the translation quality with few-shot in-context learning can surpass that of strong encoder-decoder MT systems, especially for high-resource languages. Moreover, we investigate whether we can combine MT from strong encoder-decoder models with fuzzy matches, which can further improve the translation, especially for less supported languages. We conduct our experiments across five diverse languages, namely English-to-Arabic (EN-AR), English-to-Chinese (EN-ZH), English-to-French (EN-FR), English-to-Kinyarwanda (EN-RW), and English-to-Spanish (EN-ES) language pairs.
Translation Word-Level Auto-Completion: What can we achieve out of the box?
Oct 23, 2022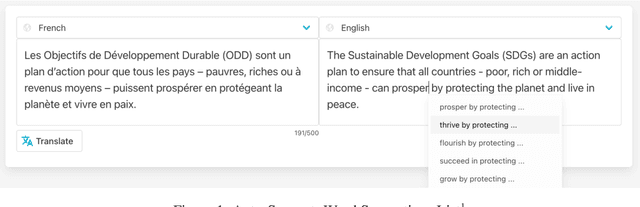
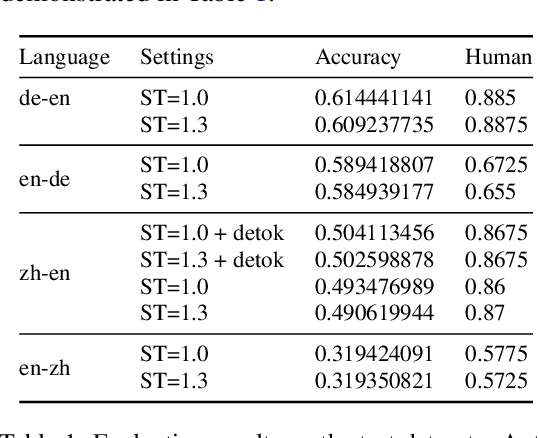

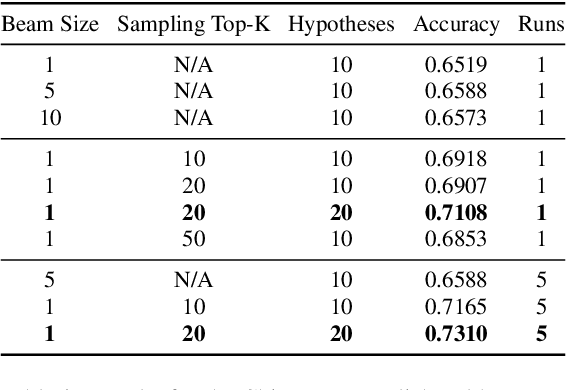
Research on Machine Translation (MT) has achieved important breakthroughs in several areas. While there is much more to be done in order to build on this success, we believe that the language industry needs better ways to take full advantage of current achievements. Due to a combination of factors, including time, resources, and skills, businesses tend to apply pragmatism into their AI workflows. Hence, they concentrate more on outcomes, e.g. delivery, shipping, releases, and features, and adopt high-level working production solutions, where possible. Among the features thought to be helpful for translators are sentence-level and word-level translation auto-suggestion and auto-completion. Suggesting alternatives can inspire translators and limit their need to refer to external resources, which hopefully boosts their productivity. This work describes our submissions to WMT's shared task on word-level auto-completion, for the Chinese-to-English, English-to-Chinese, German-to-English, and English-to-German language directions. We investigate the possibility of using pre-trained models and out-of-the-box features from available libraries. We employ random sampling to generate diverse alternatives, which reveals good results. Furthermore, we introduce our open-source API, based on CTranslate2, to serve translations, auto-suggestions, and auto-completions.
* WMT 2022
Domain-Specific Text Generation for Machine Translation
Aug 11, 2022
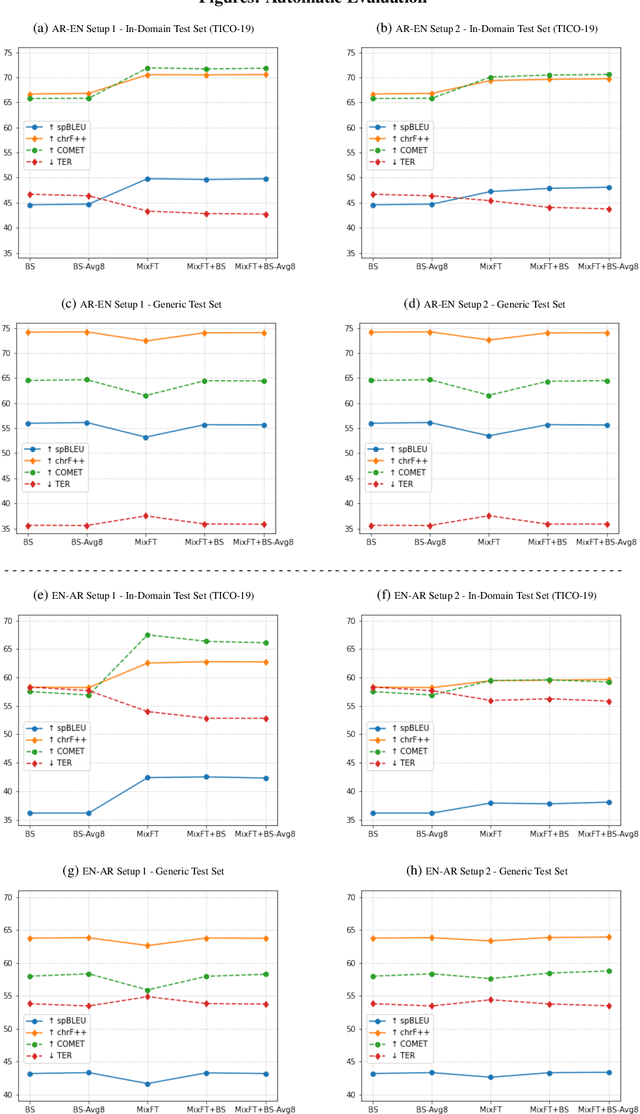
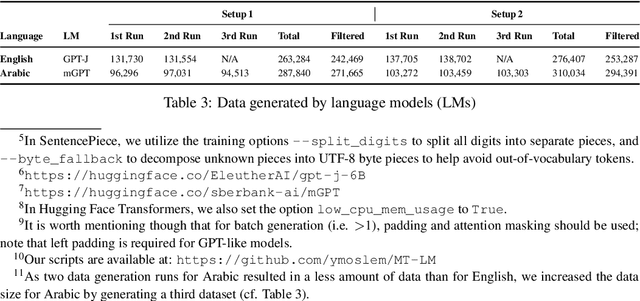
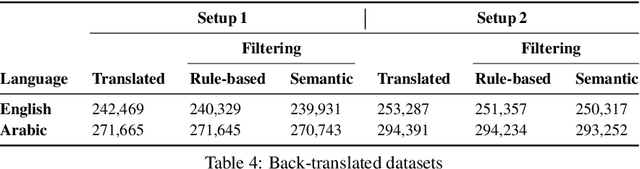
Preservation of domain knowledge from the source to target is crucial in any translation workflow. It is common in the translation industry to receive highly specialized projects, where there is hardly any parallel in-domain data. In such scenarios where there is insufficient in-domain data to fine-tune Machine Translation (MT) models, producing translations that are consistent with the relevant context is challenging. In this work, we propose a novel approach to domain adaptation leveraging state-of-the-art pretrained language models (LMs) for domain-specific data augmentation for MT, simulating the domain characteristics of either (a) a small bilingual dataset, or (b) the monolingual source text to be translated. Combining this idea with back-translation, we can generate huge amounts of synthetic bilingual in-domain data for both use cases. For our investigation, we use the state-of-the-art Transformer architecture. We employ mixed fine-tuning to train models that significantly improve translation of in-domain texts. More specifically, in both scenarios, our proposed methods achieve improvements of approximately 5-6 BLEU and 2-3 BLEU, respectively, on the Arabic-to-English and English-to-Arabic language pairs. Furthermore, the outcome of human evaluation corroborates the automatic evaluation results.
Facilitating Access to Multilingual COVID-19 Information via Neural Machine Translation
May 01, 2020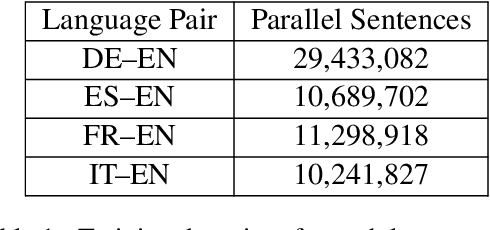
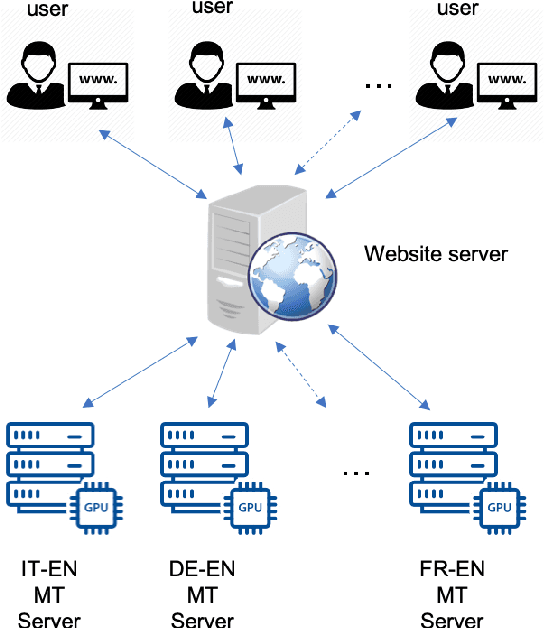
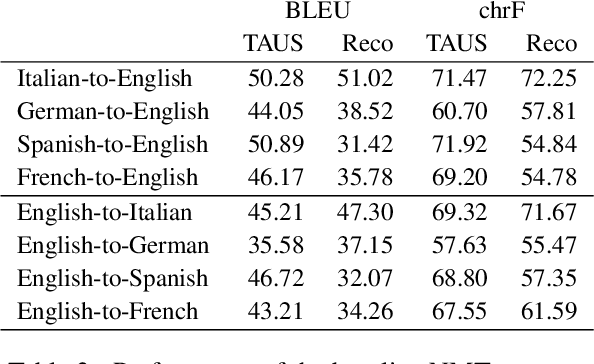

Every day, more people are becoming infected and dying from exposure to COVID-19. Some countries in Europe like Spain, France, the UK and Italy have suffered particularly badly from the virus. Others such as Germany appear to have coped extremely well. Both health professionals and the general public are keen to receive up-to-date information on the effects of the virus, as well as treatments that have proven to be effective. In cases where language is a barrier to access of pertinent information, machine translation (MT) may help people assimilate information published in different languages. Our MT systems trained on COVID-19 data are freely available for anyone to use to help translate information published in German, French, Italian, Spanish into English, as well as the reverse direction.