Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual and Multi-Aspect Hate Speech Analysis
Paper and Code



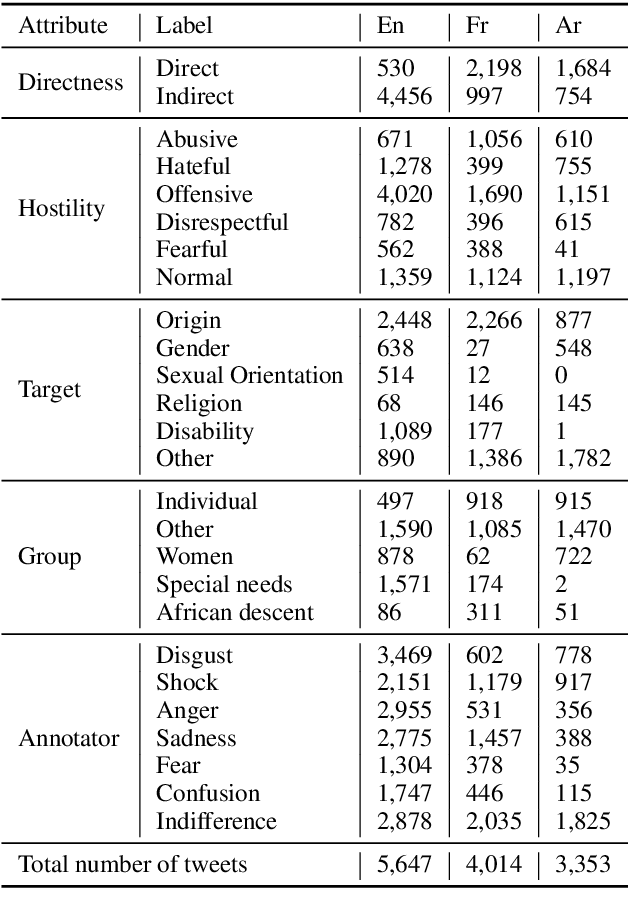
Current research on hate speech analysis is typically oriented towards monolingual and single classification tasks. In this paper, we present a new multilingual multi-aspect hate speech analysis dataset and use it to test the current state-of-the-art multilingual multitask learning approaches. We evaluate our dataset in various classification settings, then we discuss how to leverage our annotations in order to improve hate speech detection and classification in general.
View paper on