 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Sign Language Production with Latent Motion Transformer
Dec 20, 2023



Sign Language Production (SLP) is the tough task of turning sign language into sign videos. The main goal of SLP is to create these videos using a sign gloss. In this research, we've developed a new method to make high-quality sign videos without using human poses as a middle step. Our model works in two main parts: first, it learns from a generator and the video's hidden features, and next, it uses another model to understand the order of these hidden features. To make this method even better for sign videos, we make several significant improvements. (i) In the first stage, we take an improved 3D VQ-GAN to learn downsampled latent representations. (ii) In the second stage, we introduce sequence-to-sequence attention to better leverage conditional information. (iii) The separated two-stage training discards the realistic visual semantic of the latent codes in the second stage. To endow the latent sequences semantic information, we extend the token-level autoregressive latent codes learning with perceptual loss and reconstruction loss for the prior model with visual perception. Compared with previous state-of-the-art approaches, our model performs consistently better on two word-level sign language datasets, i.e., WLASL and NMFs-CSL.
Vector Quantized Diffusion Model with CodeUnet for Text-to-Sign Pose Sequences Generation
Aug 19, 2022
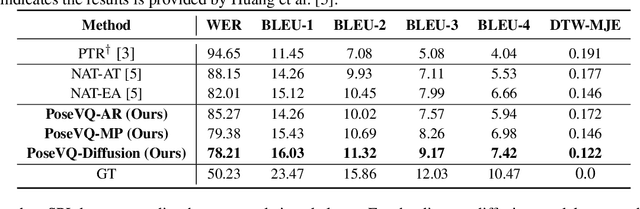
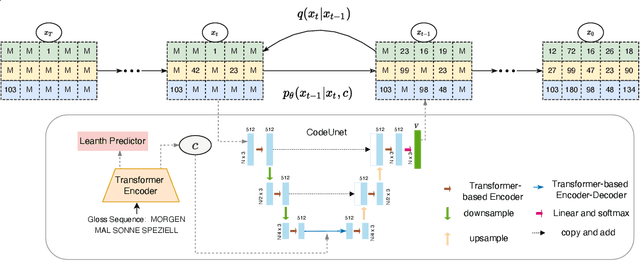

Sign Language Production (SLP) aims to translate spoken languages into sign sequences automatically. The core process of SLP is to transform sign gloss sequences into their corresponding sign pose sequences (G2P). Most existing G2P models usually perform this conditional long-range generation in an autoregressive manner, which inevitably leads to an accumulation of errors. To address this issue, we propose a vector quantized diffusion method for conditional pose sequences generation, called PoseVQ-Diffusion, which is an iterative non-autoregressive method. Specifically, we first introduce a vector quantized variational autoencoder (Pose-VQVAE) model to represent a pose sequence as a sequence of latent codes. Then we model the latent discrete space by an extension of the recently developed diffusion architecture. To better leverage the spatial-temporal information, we introduce a novel architecture, namely CodeUnet, to generate higher quality pose sequence in the discrete space. Moreover, taking advantage of the learned codes, we develop a novel sequential k-nearest-neighbours method to predict the variable lengths of pose sequences for corresponding gloss sequences. Consequently, compared with the autoregressive G2P models, our model has a faster sampling speed and produces significantly better results. Compared with previous non-autoregressive G2P methods, PoseVQ-Diffusion improves the predicted results with iterative refinements, thus achieving state-of-the-art results on the SLP evaluation benchmark.