 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCtrl&Shift: High-Quality Geometry-Aware Object Manipulation in Visual Generation
Feb 11, 2026Object-level manipulation, relocating or reorienting objects in images or videos while preserving scene realism, is central to film post-production, AR, and creative editing. Yet existing methods struggle to jointly achieve three core goals: background preservation, geometric consistency under viewpoint shifts, and user-controllable transformations. Geometry-based approaches offer precise control but require explicit 3D reconstruction and generalize poorly; diffusion-based methods generalize better but lack fine-grained geometric control. We present Ctrl&Shift, an end-to-end diffusion framework to achieve geometry-consistent object manipulation without explicit 3D representations. Our key insight is to decompose manipulation into two stages, object removal and reference-guided inpainting under explicit camera pose control, and encode both within a unified diffusion process. To enable precise, disentangled control, we design a multi-task, multi-stage training strategy that separates background, identity, and pose signals across tasks. To improve generalization, we introduce a scalable real-world dataset construction pipeline that generates paired image and video samples with estimated relative camera poses. Extensive experiments demonstrate that Ctrl&Shift achieves state-of-the-art results in fidelity, viewpoint consistency, and controllability. To our knowledge, this is the first framework to unify fine-grained geometric control and real-world generalization for object manipulation, without relying on any explicit 3D modeling.
Point2Insert: Video Object Insertion via Sparse Point Guidance
Feb 04, 2026This paper introduces Point2Insert, a sparse-point-based framework for flexible and user-friendly object insertion in videos, motivated by the growing popularity of accurate, low-effort object placement. Existing approaches face two major challenges: mask-based insertion methods require labor-intensive mask annotations, while instruction-based methods struggle to place objects at precise locations. Point2Insert addresses these issues by requiring only a small number of sparse points instead of dense masks, eliminating the need for tedious mask drawing. Specifically, it supports both positive and negative points to indicate regions that are suitable or unsuitable for insertion, enabling fine-grained spatial control over object locations. The training of Point2Insert consists of two stages. In Stage 1, we train an insertion model that generates objects in given regions conditioned on either sparse-point prompts or a binary mask. In Stage 2, we further train the model on paired videos synthesized by an object removal model, adapting it to video insertion. Moreover, motivated by the higher insertion success rate of mask-guided editing, we leverage a mask-guided insertion model as a teacher to distill reliable insertion behavior into the point-guided model. Extensive experiments demonstrate that Point2Insert consistently outperforms strong baselines and even surpasses models with $\times$10 more parameters.
TeleStyle: Content-Preserving Style Transfer in Images and Videos
Jan 28, 2026Content-preserving style transfer, generating stylized outputs based on content and style references, remains a significant challenge for Diffusion Transformers (DiTs) due to the inherent entanglement of content and style features in their internal representations. In this technical report, we present TeleStyle, a lightweight yet effective model for both image and video stylization. Built upon Qwen-Image-Edit, TeleStyle leverages the base model's robust capabilities in content preservation and style customization. To facilitate effective training, we curated a high-quality dataset of distinct specific styles and further synthesized triplets using thousands of diverse, in-the-wild style categories. We introduce a Curriculum Continual Learning framework to train TeleStyle on this hybrid dataset of clean (curated) and noisy (synthetic) triplets. This approach enables the model to generalize to unseen styles without compromising precise content fidelity. Additionally, we introduce a video-to-video stylization module to enhance temporal consistency and visual quality. TeleStyle achieves state-of-the-art performance across three core evaluation metrics: style similarity, content consistency, and aesthetic quality. Code and pre-trained models are available at https://github.com/Tele-AI/TeleStyle
Unison: A Fully Automatic, Task-Universal, and Low-Cost Framework for Unified Understanding and Generation
Dec 08, 2025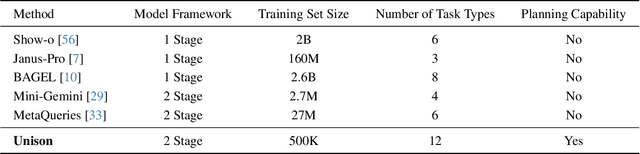
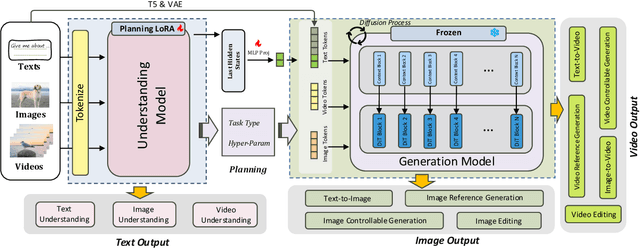


Unified understanding and generation is a highly appealing research direction in multimodal learning. There exist two approaches: one trains a transformer via an auto-regressive paradigm, and the other adopts a two-stage scheme connecting pre-trained understanding and generative models for alignment fine-tuning. The former demands massive data and computing resources unaffordable for ordinary researchers. Though the latter requires a lower training cost, existing works often suffer from limited task coverage or poor generation quality. Both approaches lack the ability to parse input meta-information (such as task type, image resolution, video duration, etc.) and require manual parameter configuration that is tedious and non-intelligent. In this paper, we propose Unison which adopts the two-stage scheme while preserving the capabilities of the pre-trained models well. With an extremely low training cost, we cover a variety of multimodal understanding tasks, including text, image, and video understanding, as well as diverse generation tasks, such as text-to-visual content generation, editing, controllable generation, and IP-based reference generation. We also equip our model with the ability to automatically parse user intentions, determine the target task type, and accurately extract the meta-information required for the corresponding task. This enables full automation of various multimodal tasks without human intervention. Experiments demonstrate that, under a low-cost setting of only 500k training samples and 50 GPU hours, our model can accurately and automatically identify tasks and extract relevant parameters, and achieve superior performance across a variety of understanding and generation tasks.
MiniMax-Remover: Taming Bad Noise Helps Video Object Removal
May 30, 2025Recent advances in video diffusion models have driven rapid progress in video editing techniques. However, video object removal, a critical subtask of video editing, remains challenging due to issues such as hallucinated objects and visual artifacts. Furthermore, existing methods often rely on computationally expensive sampling procedures and classifier-free guidance (CFG), resulting in slow inference. To address these limitations, we propose MiniMax-Remover, a novel two-stage video object removal approach. Motivated by the observation that text condition is not best suited for this task, we simplify the pretrained video generation model by removing textual input and cross-attention layers, resulting in a more lightweight and efficient model architecture in the first stage. In the second stage, we distilled our remover on successful videos produced by the stage-1 model and curated by human annotators, using a minimax optimization strategy to further improve editing quality and inference speed. Specifically, the inner maximization identifies adversarial input noise ("bad noise") that makes failure removals, while the outer minimization step trains the model to generate high-quality removal results even under such challenging conditions. As a result, our method achieves a state-of-the-art video object removal results with as few as 6 sampling steps and doesn't rely on CFG, significantly improving inference efficiency. Extensive experiments demonstrate the effectiveness and superiority of MiniMax-Remover compared to existing methods. Codes and Videos are available at: https://minimax-remover.github.io.
Taming Transformer Without Using Learning Rate Warmup
May 28, 2025Scaling Transformer to a large scale without using some technical tricks such as learning rate warump and using an obviously lower learning rate is an extremely challenging task, and is increasingly gaining more attention. In this paper, we provide a theoretical analysis for the process of training Transformer and reveal the rationale behind the model crash phenomenon in the training process, termed \textit{spectral energy concentration} of ${\bW_q}^{\top} \bW_k$, which is the reason for a malignant entropy collapse, where ${\bW_q}$ and $\bW_k$ are the projection matrices for the query and the key in Transformer, respectively. To remedy this problem, motivated by \textit{Weyl's Inequality}, we present a novel optimization strategy, \ie, making the weight updating in successive steps smooth -- if the ratio $\frac{\sigma_{1}(\nabla \bW_t)}{\sigma_{1}(\bW_{t-1})}$ is larger than a threshold, we will automatically bound the learning rate to a weighted multiple of $\frac{\sigma_{1}(\bW_{t-1})}{\sigma_{1}(\nabla \bW_t)}$, where $\nabla \bW_t$ is the updating quantity in step $t$. Such an optimization strategy can prevent spectral energy concentration to only a few directions, and thus can avoid malignant entropy collapse which will trigger the model crash. We conduct extensive experiments using ViT, Swin-Transformer and GPT, showing that our optimization strategy can effectively and stably train these Transformers without using learning rate warmup.
Señorita-2M: A High-Quality Instruction-based Dataset for General Video Editing by Video Specialists
Feb 10, 2025



Recent advancements in video generation have spurred the development of video editing techniques, which can be divided into inversion-based and end-to-end methods. However, current video editing methods still suffer from several challenges. Inversion-based methods, though training-free and flexible, are time-consuming during inference, struggle with fine-grained editing instructions, and produce artifacts and jitter. On the other hand, end-to-end methods, which rely on edited video pairs for training, offer faster inference speeds but often produce poor editing results due to a lack of high-quality training video pairs. In this paper, to close the gap in end-to-end methods, we introduce Se\~norita-2M, a high-quality video editing dataset. Se\~norita-2M consists of approximately 2 millions of video editing pairs. It is built by crafting four high-quality, specialized video editing models, each crafted and trained by our team to achieve state-of-the-art editing results. We also propose a filtering pipeline to eliminate poorly edited video pairs. Furthermore, we explore common video editing architectures to identify the most effective structure based on current pre-trained generative model. Extensive experiments show that our dataset can help to yield remarkably high-quality video editing results. More details are available at https://senorita.github.io.
Adversarial Prompt Distillation for Vision-Language Models
Nov 22, 2024Large pre-trained Vision-Language Models (VLMs) such as Contrastive Language-Image Pre-Training (CLIP) have been shown to be susceptible to adversarial attacks, raising concerns about their deployment in safety-critical scenarios like autonomous driving and medical diagnosis. One promising approach for improving the robustness of pre-trained VLMs is Adversarial Prompt Tuning (APT), which combines adversarial training with prompt tuning. However, existing APT methods are mostly single-modal methods that design prompt(s) for only the visual or textual modality, limiting their effectiveness in either robustness or clean accuracy. In this work, we propose a novel method called Adversarial Prompt Distillation (APD) that combines APT with knowledge distillation to boost the adversarial robustness of CLIP. Specifically, APD is a bimodal method that adds prompts for both the visual and textual modalities while leveraging a cleanly pre-trained teacher CLIP model to distill and boost the performance of the student CLIP model on downstream tasks. Extensive experiments on multiple benchmark datasets demonstrate the superiority of our APD over the current state-of-the-art APT methods in terms of both natural and adversarial performances. The effectiveness of our APD method validates the possibility of using a non-robust teacher to improve the generalization and robustness of VLMs.
BiGR: Harnessing Binary Latent Codes for Image Generation and Improved Visual Representation Capabilities
Oct 18, 2024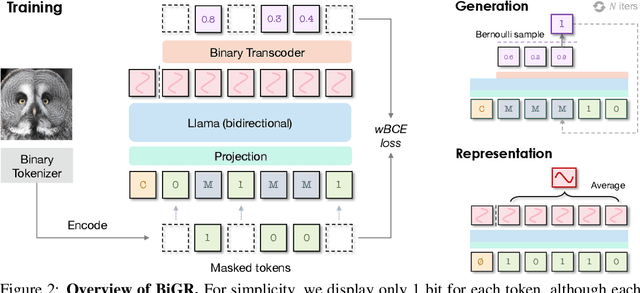
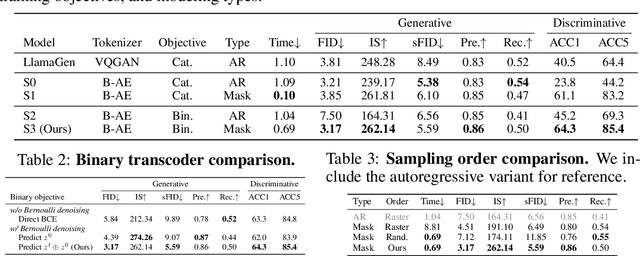
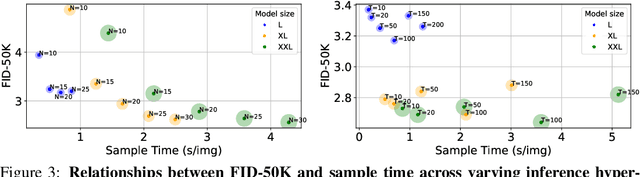
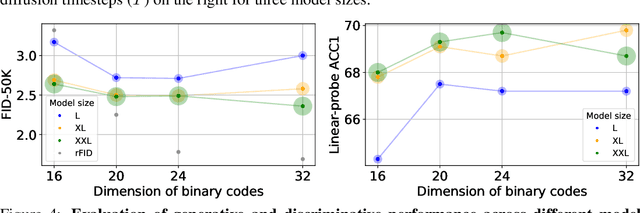
We introduce BiGR, a novel conditional image generation model using compact binary latent codes for generative training, focusing on enhancing both generation and representation capabilities. BiGR is the first conditional generative model that unifies generation and discrimination within the same framework. BiGR features a binary tokenizer, a masked modeling mechanism, and a binary transcoder for binary code prediction. Additionally, we introduce a novel entropy-ordered sampling method to enable efficient image generation. Extensive experiments validate BiGR's superior performance in generation quality, as measured by FID-50k, and representation capabilities, as evidenced by linear-probe accuracy. Moreover, BiGR showcases zero-shot generalization across various vision tasks, enabling applications such as image inpainting, outpainting, editing, interpolation, and enrichment, without the need for structural modifications. Our findings suggest that BiGR unifies generative and discriminative tasks effectively, paving the way for further advancements in the field.
CoCoCo: Improving Text-Guided Video Inpainting for Better Consistency, Controllability and Compatibility
Mar 18, 2024Recent advancements in video generation have been remarkable, yet many existing methods struggle with issues of consistency and poor text-video alignment. Moreover, the field lacks effective techniques for text-guided video inpainting, a stark contrast to the well-explored domain of text-guided image inpainting. To this end, this paper proposes a novel text-guided video inpainting model that achieves better consistency, controllability and compatibility. Specifically, we introduce a simple but efficient motion capture module to preserve motion consistency, and design an instance-aware region selection instead of a random region selection to obtain better textual controllability, and utilize a novel strategy to inject some personalized models into our CoCoCo model and thus obtain better model compatibility. Extensive experiments show that our model can generate high-quality video clips. Meanwhile, our model shows better motion consistency, textual controllability and model compatibility. More details are shown in [cococozibojia.github.io](cococozibojia.github.io).