 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElucidating the design space of language models for image generation
Oct 21, 2024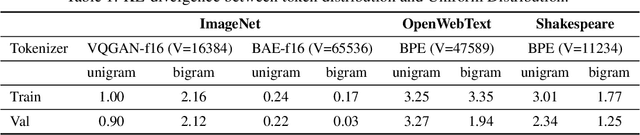
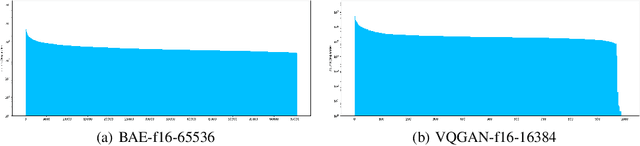
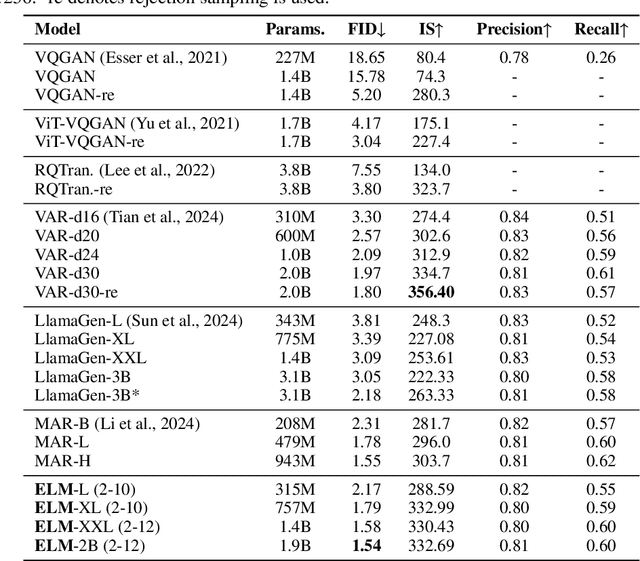
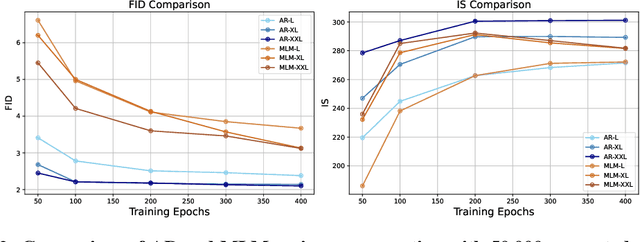
The success of autoregressive (AR) language models in text generation has inspired the computer vision community to adopt Large Language Models (LLMs) for image generation. However, considering the essential differences between text and image modalities, the design space of language models for image generation remains underexplored. We observe that image tokens exhibit greater randomness compared to text tokens, which presents challenges when training with token prediction. Nevertheless, AR models demonstrate their potential by effectively learning patterns even from a seemingly suboptimal optimization problem. Our analysis also reveals that while all models successfully grasp the importance of local information in image generation, smaller models struggle to capture the global context. In contrast, larger models showcase improved capabilities in this area, helping to explain the performance gains achieved when scaling up model size. We further elucidate the design space of language models for vision generation, including tokenizer choice, model choice, model scalability, vocabulary design, and sampling strategy through extensive comparative experiments. Our work is the first to analyze the optimization behavior of language models in vision generation, and we believe it can inspire more effective designs when applying LMs to other domains. Finally, our elucidated language model for image generation, termed as ELM, achieves state-of-the-art performance on the ImageNet 256*256 benchmark. The code is available at https://github.com/Pepperlll/LMforImageGeneration.git.
BiGR: Harnessing Binary Latent Codes for Image Generation and Improved Visual Representation Capabilities
Oct 18, 2024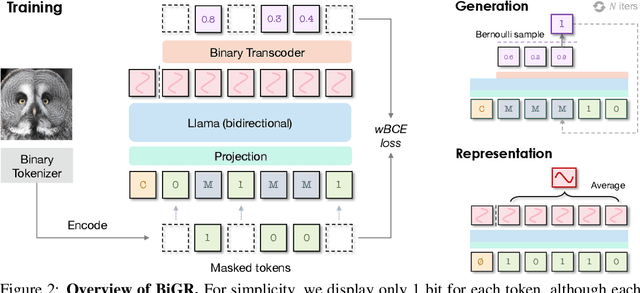
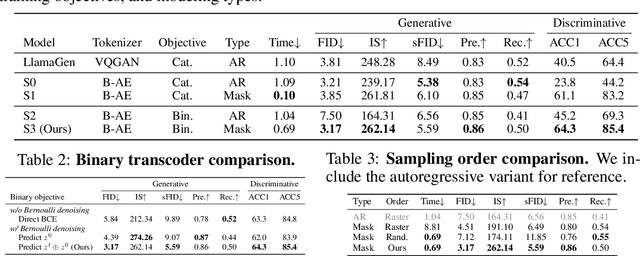
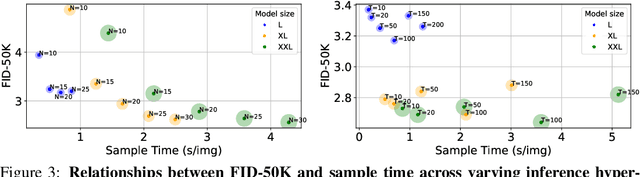
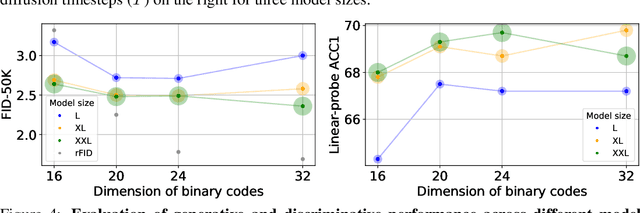
We introduce BiGR, a novel conditional image generation model using compact binary latent codes for generative training, focusing on enhancing both generation and representation capabilities. BiGR is the first conditional generative model that unifies generation and discrimination within the same framework. BiGR features a binary tokenizer, a masked modeling mechanism, and a binary transcoder for binary code prediction. Additionally, we introduce a novel entropy-ordered sampling method to enable efficient image generation. Extensive experiments validate BiGR's superior performance in generation quality, as measured by FID-50k, and representation capabilities, as evidenced by linear-probe accuracy. Moreover, BiGR showcases zero-shot generalization across various vision tasks, enabling applications such as image inpainting, outpainting, editing, interpolation, and enrichment, without the need for structural modifications. Our findings suggest that BiGR unifies generative and discriminative tasks effectively, paving the way for further advancements in the field.
Referee Can Play: An Alternative Approach to Conditional Generation via Model Inversion
Feb 26, 2024



As a dominant force in text-to-image generation tasks, Diffusion Probabilistic Models (DPMs) face a critical challenge in controllability, struggling to adhere strictly to complex, multi-faceted instructions. In this work, we aim to address this alignment challenge for conditional generation tasks. First, we provide an alternative view of state-of-the-art DPMs as a way of inverting advanced Vision-Language Models (VLMs). With this formulation, we naturally propose a training-free approach that bypasses the conventional sampling process associated with DPMs. By directly optimizing images with the supervision of discriminative VLMs, the proposed method can potentially achieve a better text-image alignment. As proof of concept, we demonstrate the pipeline with the pre-trained BLIP-2 model and identify several key designs for improved image generation. To further enhance the image fidelity, a Score Distillation Sampling module of Stable Diffusion is incorporated. By carefully balancing the two components during optimization, our method can produce high-quality images with near state-of-the-art performance on T2I-Compbench.
Inducing Neural Collapse in Deep Long-tailed Learning
Feb 24, 2023



Although deep neural networks achieve tremendous success on various classification tasks, the generalization ability drops sheer when training datasets exhibit long-tailed distributions. One of the reasons is that the learned representations (i.e. features) from the imbalanced datasets are less effective than those from balanced datasets. Specifically, the learned representation under class-balanced distribution will present the Neural Collapse (NC) phenomena. NC indicates the features from the same category are close to each other and from different categories are maximally distant, showing an optimal linear separable state of classification. However, the pattern differs on imbalanced datasets and is partially responsible for the reduced performance of the model. In this work, we propose two explicit feature regularization terms to learn high-quality representation for class-imbalanced data. With the proposed regularization, NC phenomena will appear under the class-imbalanced distribution, and the generalization ability can be significantly improved. Our method is easily implemented, highly effective, and can be plugged into most existing methods. The extensive experimental results on widely-used benchmarks show the effectiveness of our method