 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Analysis of Upper Limb and Hand in a Haptic Rotation Task
Nov 17, 2024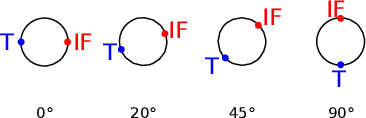
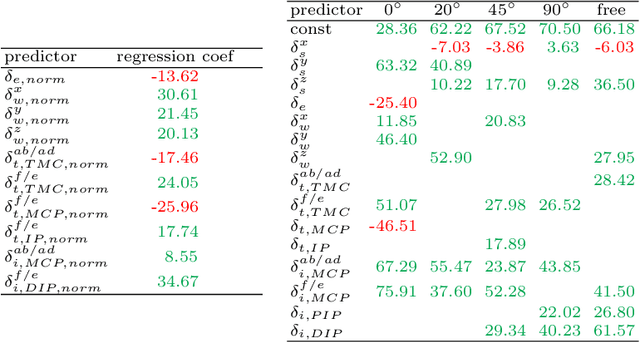
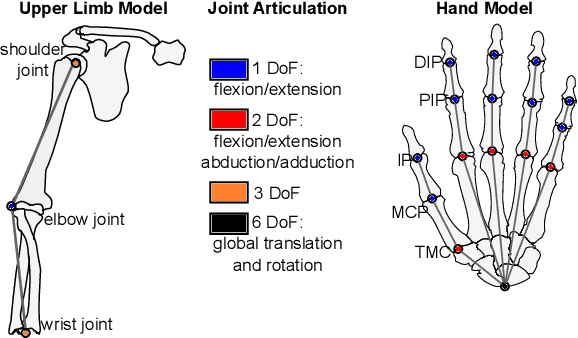
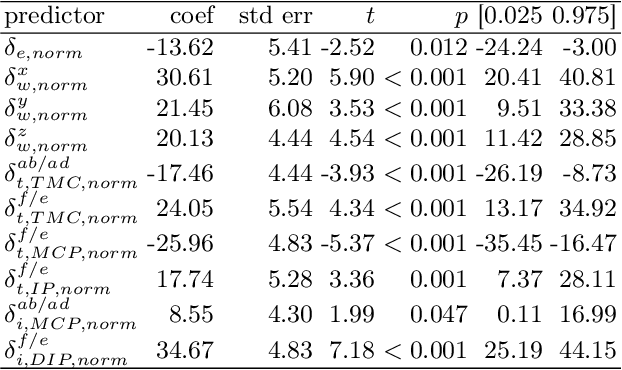
Humans seem to have a bias to overshoot when rotating a rotary knob blindfolded around a specified target angle (i.e. during haptic rotation). Whereas some influence factors that strengthen or weaken such an effect are already known, the underlying reasons for the overshoot are still unknown. This work approaches the topic of haptic rotations by analyzing a detailed recording of the movement. We propose an experimental framework and an approach to investigate which upper limb and hand joint movements contribute significantly to a haptic rotation task and to the angle overshoot based on the acquired data. With stepwise regression with backward elimination, we analyze a rotation around 90 degrees counterclockwise with two fingers under different grasping orientations. Our results showed that the wrist joint, the sideways finger movement in the proximal joints, and the distal finger joints contributed significantly to overshooting. This suggests that two phenomena are behind the overshooting: 1) The significant contribution of the wrist joint indicates a bias of a hand-centered egocentric reference frame. 2) Significant contribution of the finger joints indicates a rolling of the fingertips over the rotary knob surface and, thus, a change of contact point for which probably the human does not compensate.
Generating Piano Practice Policy with a Gaussian Process
Jun 07, 2024

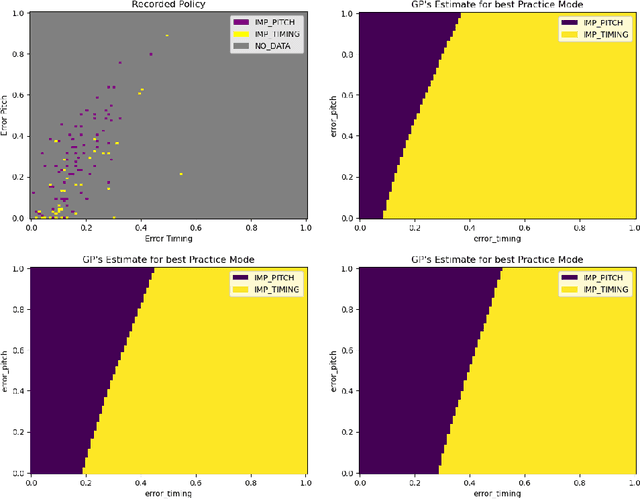
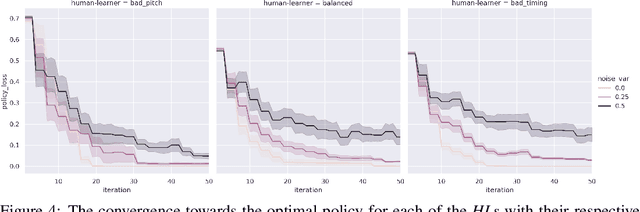
A typical process of learning to play a piece on a piano consists of a progression through a series of practice units that focus on individual dimensions of the skill, the so-called practice modes. Practice modes in learning to play music comprise a particularly large set of possibilities, such as hand coordination, posture, articulation, ability to read a music score, correct timing or pitch, etc. Self-guided practice is known to be suboptimal, and a model that schedules optimal practice to maximize a learner's progress still does not exist. Because we each learn differently and there are many choices for possible piano practice tasks and methods, the set of practice modes should be dynamically adapted to the human learner, a process typically guided by a teacher. However, having a human teacher guide individual practice is not always feasible since it is time-consuming, expensive, and often unavailable. In this work, we present a modeling framework to guide the human learner through the learning process by choosing the practice modes generated by a policy model. To this end, we present a computational architecture building on a Gaussian process that incorporates 1) the learner state, 2) a policy that selects a suitable practice mode, 3) performance evaluation, and 4) expert knowledge. The proposed policy model is trained to approximate the expert-learner interaction during a practice session. In our future work, we will test different Bayesian optimization techniques, e.g., different acquisition functions, and evaluate their effect on the learning progress.
Optimizing piano practice with a utility-based scaffold
Jun 21, 2021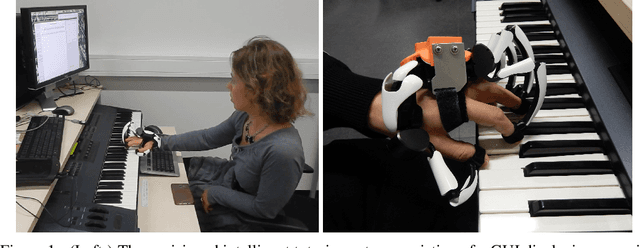
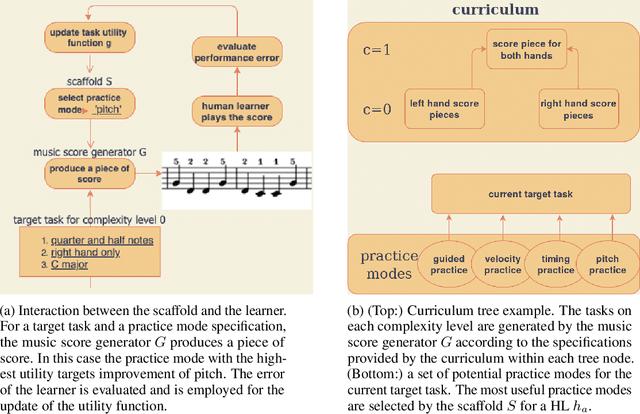
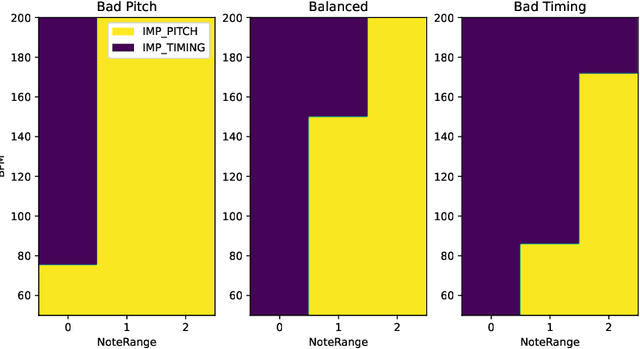
A typical part of learning to play the piano is the progression through a series of practice units that focus on individual dimensions of the skill, such as hand coordination, correct posture, or correct timing. Ideally, a focus on a particular practice method should be made in a way to maximize the learner's progress in learning to play the piano. Because we each learn differently, and because there are many choices for possible piano practice tasks and methods, the set of practice tasks should be dynamically adapted to the human learner. However, having a human teacher guide individual practice is not always feasible since it is time consuming, expensive, and not always available. Instead, we suggest to optimize in the space of practice methods, the so-called practice modes. The proposed optimization process takes into account the skills of the individual learner and their history of learning. In this work we present a modeling framework to guide the human learner through the learning process by choosing practice modes that have the highest expected utility (i.e., improvement in piano playing skill). To this end, we propose a human learner utility model based on a Gaussian process, and exemplify the model training and its application for practice scaffolding on an example of simulated human learners.
Learning efficient haptic shape exploration with a rigid tactile sensor array
Feb 22, 2019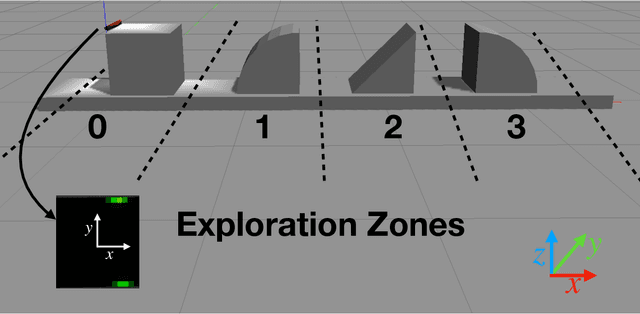
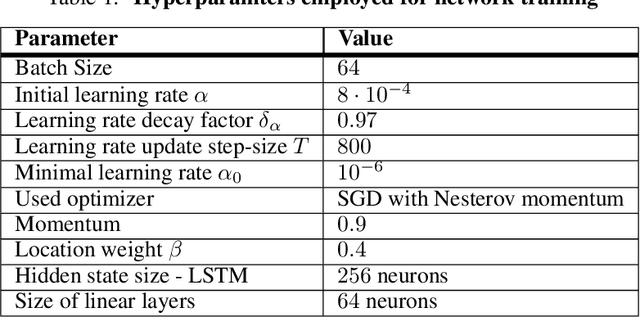
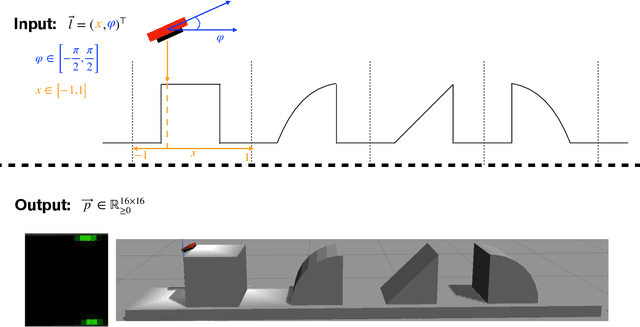
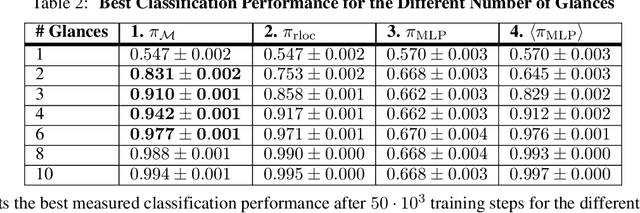
Haptic exploration is a key skill for both robots and humans to discriminate and handle unknown or recognize familiar objects. Its active nature is impressively evident in humans which from early on reliably acquire sophisticated sensory-motor capabilites for active exploratory touch and directed manual exploration that associates surfaces and object properties with their spatial locations. In stark contrast, in robotics the relative lack of good real-world interaction models, along with very restricted sensors and a scarcity of suitable training data to leverage machine learning methods has so far rendered haptic exploration a largely underdeveloped skill for robots, very unlike vision where deep learning approaches and an abundance of available training data have triggered huge advances. In the present work, we connect recent advances in recurrent models of visual attention (RAM) with previous insights about the organisation of human haptic search behavior, exploratory procedures and haptic glances for a novel learning architecture that learns a generative model of haptic exploration in a simplified three-dimensional environment. The proposed algorithm simultaneously optimizes main perception-action loop components: feature extraction, integration of features over time, and the control strategy, while continuously acquiring data online. The resulting method has been successfully tested with four different objects. It achieved results close to 100% while performing object contour exploration that has been optimized for its own sensor morphology.