 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning efficient haptic shape exploration with a rigid tactile sensor array
Feb 22, 2019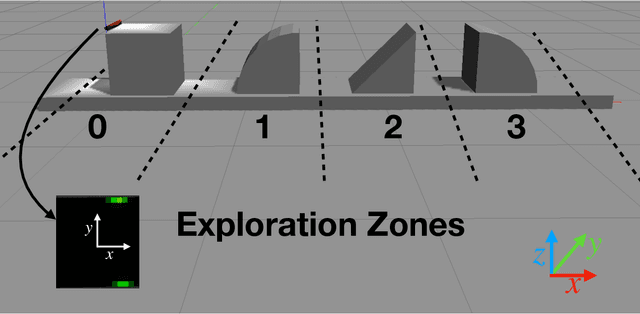
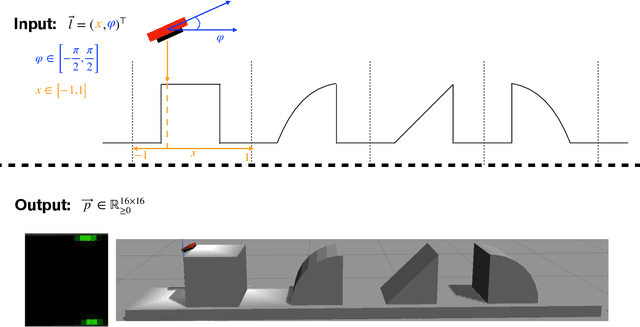
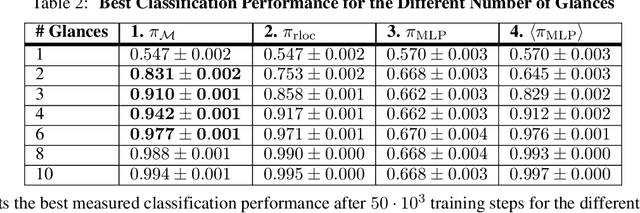
Haptic exploration is a key skill for both robots and humans to discriminate and handle unknown or recognize familiar objects. Its active nature is impressively evident in humans which from early on reliably acquire sophisticated sensory-motor capabilites for active exploratory touch and directed manual exploration that associates surfaces and object properties with their spatial locations. In stark contrast, in robotics the relative lack of good real-world interaction models, along with very restricted sensors and a scarcity of suitable training data to leverage machine learning methods has so far rendered haptic exploration a largely underdeveloped skill for robots, very unlike vision where deep learning approaches and an abundance of available training data have triggered huge advances. In the present work, we connect recent advances in recurrent models of visual attention (RAM) with previous insights about the organisation of human haptic search behavior, exploratory procedures and haptic glances for a novel learning architecture that learns a generative model of haptic exploration in a simplified three-dimensional environment. The proposed algorithm simultaneously optimizes main perception-action loop components: feature extraction, integration of features over time, and the control strategy, while continuously acquiring data online. The resulting method has been successfully tested with four different objects. It achieved results close to 100% while performing object contour exploration that has been optimized for its own sensor morphology.
Modularization of End-to-End Learning: Case Study in Arcade Games
Jan 27, 2019
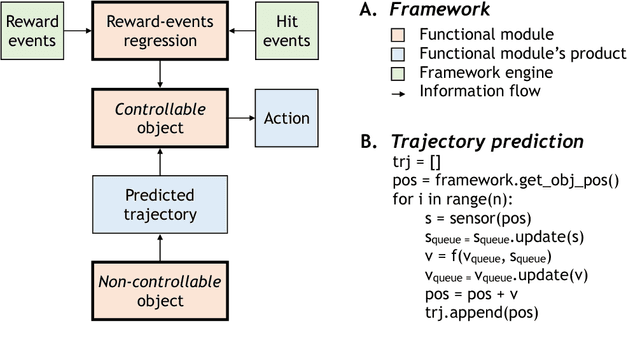
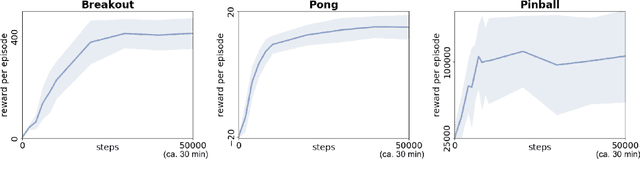
Complex environments and tasks pose a difficult problem for holistic end-to-end learning approaches. Decomposition of an environment into interacting controllable and non-controllable objects allows supervised learning for non-controllable objects and universal value function approximator learning for controllable objects. Such decomposition should lead to a shorter learning time and better generalisation capability. Here, we consider arcade-game environments as sets of interacting objects (controllable, non-controllable) and propose a set of functional modules that are specialized on mastering different types of interactions in a broad range of environments. The modules utilize regression, supervised learning, and reinforcement learning algorithms. Results of this case study in different Atari games suggest that human-level performance can be achieved by a learning agent within a human amount of game experience (10-15 minutes game time) when a proper decomposition of an environment or a task is provided. However, automatization of such decomposition remains a challenging problem. This case study shows how a model of a causal structure underlying an environment or a task can benefit learning time and generalization capability of the agent, and argues in favor of exploiting modular structure in contrast to using pure end-to-end learning approaches.