 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoXtreme: A Dataset for Robust Object Pose Estimation in Egocentric Views under Extreme Conditions
Mar 26, 2026Smart glass is emerging as an useful device since it provides plenty of insights under hands-busy, eyes-on-task situations. To understand the context of the wearer, 6D object pose estimation in egocentric view is becoming essential. However, existing 6D object pose estimation benchmarks fail to capture the challenges of real-world egocentric applications, which are often dominated by severe motion blur, dynamic illumination, and visual obstructions. This discrepancy creates a significant gap between controlled lab data and chaotic real-world application. To bridge this gap, we introduce EgoXtreme, a new large-scale 6D pose estimation dataset captured entirely from an egocentric perspective. EgoXtreme features three challenging scenarios - industrial maintenance, sports, and emergency rescue - designed to introduce severe perceptual ambiguities through extreme lighting, heavy motion blur, and smoke. Evaluations of state-of-the-art generalizable pose estimators on EgoXtreme indicate that their generalization fails to hold in extreme conditions, especially under low light. We further demonstrate that simply applying image restoration (e.g., deblurring) offers no positive improvement for extreme conditions. While performance gain has appeared in tracking-based approach, implying using temporal information in fast-motion scenarios is meaningful. We conclude that EgoXtreme is an essential resource for developing and evaluating the next generation of pose estimation models robust enough for real-world egocentric vision. The dataset and code are available at https://taegyoun88.github.io/EgoXtreme/
Recognising BSL Fingerspelling in Continuous Signing Sequences
Mar 19, 2026Fingerspelling is a critical component of British Sign Language (BSL), used to spell proper names, technical terms, and words that lack established lexical signs. Fingerspelling recognition is challenging due to the rapid pace of signing and common letter omissions by native signers, while existing BSL fingerspelling datasets are either small in scale or temporally and letter-wise inaccurate. In this work, we introduce a new large-scale BSL fingerspelling dataset, FS23K, constructed using an iterative annotation framework. In addition, we propose a fingerspelling recognition model that explicitly accounts for bi-manual interactions and mouthing cues. As a result, with refined annotations, our approach halves the character error rate (CER) compared to the prior state of the art on fingerspelling recognition. These findings demonstrate the effectiveness of our method and highlight its potential to support future research in sign language understanding and scalable, automated annotation pipelines. The project page can be found at https://taeinkwon.com/projects/fs23k/.
Understanding Co-speech Gestures in-the-wild
Mar 28, 2025
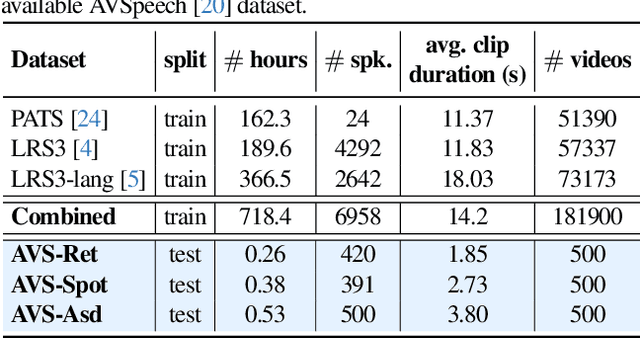
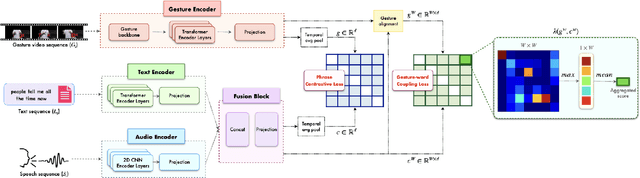
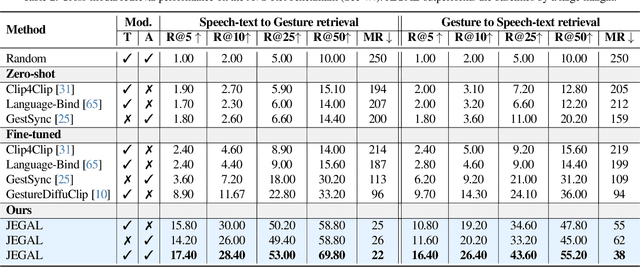
Co-speech gestures play a vital role in non-verbal communication. In this paper, we introduce a new framework for co-speech gesture understanding in the wild. Specifically, we propose three new tasks and benchmarks to evaluate a model's capability to comprehend gesture-text-speech associations: (i) gesture-based retrieval, (ii) gestured word spotting, and (iii) active speaker detection using gestures. We present a new approach that learns a tri-modal speech-text-video-gesture representation to solve these tasks. By leveraging a combination of global phrase contrastive loss and local gesture-word coupling loss, we demonstrate that a strong gesture representation can be learned in a weakly supervised manner from videos in the wild. Our learned representations outperform previous methods, including large vision-language models (VLMs), across all three tasks. Further analysis reveals that speech and text modalities capture distinct gesture-related signals, underscoring the advantages of learning a shared tri-modal embedding space. The dataset, model, and code are available at: https://www.robots.ox.ac.uk/~vgg/research/jegal
Multi Activity Sequence Alignment via Implicit Clustering
Mar 16, 2025Self-supervised temporal sequence alignment can provide rich and effective representations for a wide range of applications. However, existing methods for achieving optimal performance are mostly limited to aligning sequences of the same activity only and require separate models to be trained for each activity. We propose a novel framework that overcomes these limitations using sequence alignment via implicit clustering. Specifically, our key idea is to perform implicit clip-level clustering while aligning frames in sequences. This coupled with our proposed dual augmentation technique enhances the network's ability to learn generalizable and discriminative representations. Our experiments show that our proposed method outperforms state-of-the-art results and highlight the generalization capability of our framework with multi activity and different modalities on three diverse datasets, H2O, PennAction, and IKEA ASM. We will release our code upon acceptance.
EgoPressure: A Dataset for Hand Pressure and Pose Estimation in Egocentric Vision
Sep 03, 2024



Estimating touch contact and pressure in egocentric vision is a central task for downstream applications in Augmented Reality, Virtual Reality, as well as many robotic applications, because it provides precise physical insights into hand-object interaction and object manipulation. However, existing contact pressure datasets lack egocentric views and hand poses, which are essential for accurate estimation during in-situ operation, both for AR/VR interaction and robotic manipulation. In this paper, we introduce EgoPressure,a novel dataset of touch contact and pressure interaction from an egocentric perspective, complemented with hand pose meshes and fine-grained pressure intensities for each contact. The hand poses in our dataset are optimized using our proposed multi-view sequence-based method that processes footage from our capture rig of 8 accurately calibrated RGBD cameras. EgoPressure comprises 5.0 hours of touch contact and pressure interaction from 21 participants captured by a moving egocentric camera and 7 stationary Kinect cameras, which provided RGB images and depth maps at 30 Hz. In addition, we provide baselines for estimating pressure with different modalities, which will enable future developments and benchmarking on the dataset. Overall, we demonstrate that pressure and hand poses are complementary, which supports our intention to better facilitate the physical understanding of hand-object interactions in AR/VR and robotics research.
HoloAssist: an Egocentric Human Interaction Dataset for Interactive AI Assistants in the Real World
Sep 29, 2023



Building an interactive AI assistant that can perceive, reason, and collaborate with humans in the real world has been a long-standing pursuit in the AI community. This work is part of a broader research effort to develop intelligent agents that can interactively guide humans through performing tasks in the physical world. As a first step in this direction, we introduce HoloAssist, a large-scale egocentric human interaction dataset, where two people collaboratively complete physical manipulation tasks. The task performer executes the task while wearing a mixed-reality headset that captures seven synchronized data streams. The task instructor watches the performer's egocentric video in real time and guides them verbally. By augmenting the data with action and conversational annotations and observing the rich behaviors of various participants, we present key insights into how human assistants correct mistakes, intervene in the task completion procedure, and ground their instructions to the environment. HoloAssist spans 166 hours of data captured by 350 unique instructor-performer pairs. Furthermore, we construct and present benchmarks on mistake detection, intervention type prediction, and hand forecasting, along with detailed analysis. We expect HoloAssist will provide an important resource for building AI assistants that can fluidly collaborate with humans in the real world. Data can be downloaded at https://holoassist.github.io/.
CaSAR: Contact-aware Skeletal Action Recognition
Sep 17, 2023



Skeletal Action recognition from an egocentric view is important for applications such as interfaces in AR/VR glasses and human-robot interaction, where the device has limited resources. Most of the existing skeletal action recognition approaches use 3D coordinates of hand joints and 8-corner rectangular bounding boxes of objects as inputs, but they do not capture how the hands and objects interact with each other within the spatial context. In this paper, we present a new framework called Contact-aware Skeletal Action Recognition (CaSAR). It uses novel representations of hand-object interaction that encompass spatial information: 1) contact points where the hand joints meet the objects, 2) distant points where the hand joints are far away from the object and nearly not involved in the current action. Our framework is able to learn how the hands touch or stay away from the objects for each frame of the action sequence, and use this information to predict the action class. We demonstrate that our approach achieves the state-of-the-art accuracy of 91.3% and 98.4% on two public datasets, H2O and FPHA, respectively.
Context-Aware Sequence Alignment using 4D Skeletal Augmentation
Apr 26, 2022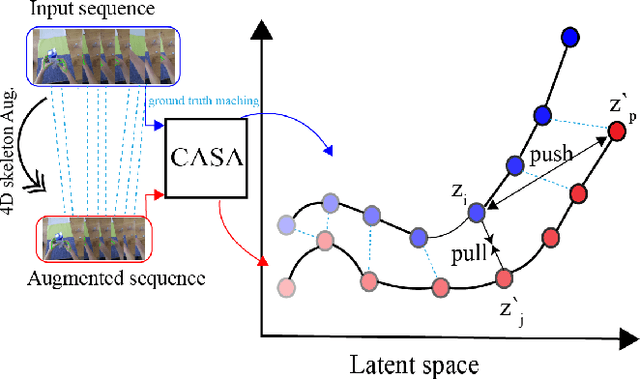
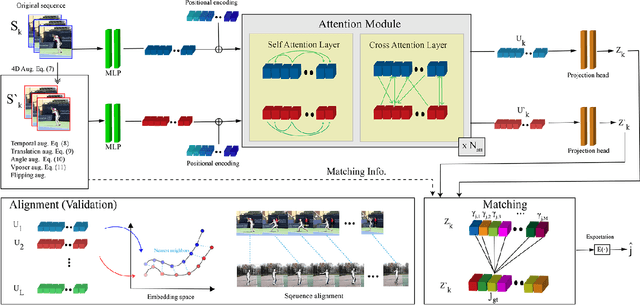
Temporal alignment of fine-grained human actions in videos is important for numerous applications in computer vision, robotics, and mixed reality. State-of-the-art methods directly learn image-based embedding space by leveraging powerful deep convolutional neural networks. While being straightforward, their results are far from satisfactory, the aligned videos exhibit severe temporal discontinuity without additional post-processing steps. The recent advancements in human body and hand pose estimation in the wild promise new ways of addressing the task of human action alignment in videos. In this work, based on off-the-shelf human pose estimators, we propose a novel context-aware self-supervised learning architecture to align sequences of actions. We name it CASA. Specifically, CASA employs self-attention and cross-attention mechanisms to incorporate the spatial and temporal context of human actions, which can solve the temporal discontinuity problem. Moreover, we introduce a self-supervised learning scheme that is empowered by novel 4D augmentation techniques for 3D skeleton representations. We systematically evaluate the key components of our method. Our experiments on three public datasets demonstrate CASA significantly improves phase progress and Kendall's Tau scores over the previous state-of-the-art methods.
H2O: Two Hands Manipulating Objects for First Person Interaction Recognition
Apr 22, 2021
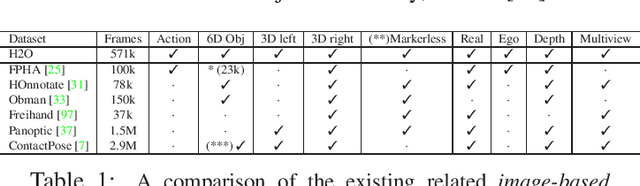


We present, for the first time, a comprehensive framework for egocentric interaction recognition using markerless 3D annotations of two hands manipulating objects. To this end, we propose a method to create a unified dataset for egocentric 3D interaction recognition. Our method produces annotations of the 3D pose of two hands and the 6D pose of the manipulated objects, along with their interaction labels for each frame. Our dataset, called H2O (2 Hands and Objects), provides synchronized multi-view RGB-D images, interaction labels, object classes, ground-truth 3D poses for left & right hands, 6D object poses, ground-truth camera poses, object meshes and scene point clouds. To the best of our knowledge, this is the first benchmark that enables the study of first-person actions with the use of the pose of both left and right hands manipulating objects and presents an unprecedented level of detail for egocentric 3D interaction recognition. We further propose the first method to predict interaction classes by estimating the 3D pose of two hands and the 6D pose of the manipulated objects, jointly from RGB images. Our method models both inter- and intra-dependencies between both hands and objects by learning the topology of a graph convolutional network that predicts interactions. We show that our method facilitated by this dataset establishes a strong baseline for joint hand-object pose estimation and achieves state-of-the-art accuracy for first person interaction recognition.