 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGMA: An Open-Source Interactive System for Mixed-Reality Task Assistance Research
May 16, 2024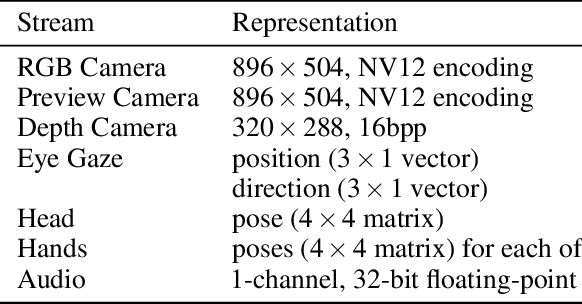


We introduce an open-source system called SIGMA (short for "Situated Interactive Guidance, Monitoring, and Assistance") as a platform for conducting research on task-assistive agents in mixed-reality scenarios. The system leverages the sensing and rendering affordances of a head-mounted mixed-reality device in conjunction with large language and vision models to guide users step by step through procedural tasks. We present the system's core capabilities, discuss its overall design and implementation, and outline directions for future research enabled by the system. SIGMA is easily extensible and provides a useful basis for future research at the intersection of mixed reality and AI. By open-sourcing an end-to-end implementation, we aim to lower the barrier to entry, accelerate research in this space, and chart a path towards community-driven end-to-end evaluation of large language, vision, and multimodal models in the context of real-world interactive applications.
HoloAssist: an Egocentric Human Interaction Dataset for Interactive AI Assistants in the Real World
Sep 29, 2023



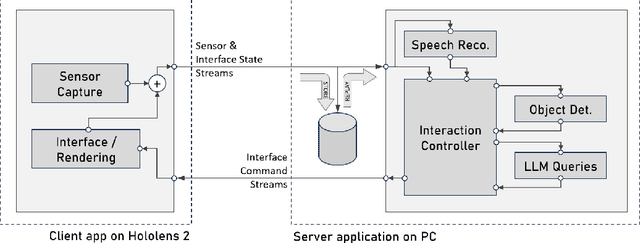
Building an interactive AI assistant that can perceive, reason, and collaborate with humans in the real world has been a long-standing pursuit in the AI community. This work is part of a broader research effort to develop intelligent agents that can interactively guide humans through performing tasks in the physical world. As a first step in this direction, we introduce HoloAssist, a large-scale egocentric human interaction dataset, where two people collaboratively complete physical manipulation tasks. The task performer executes the task while wearing a mixed-reality headset that captures seven synchronized data streams. The task instructor watches the performer's egocentric video in real time and guides them verbally. By augmenting the data with action and conversational annotations and observing the rich behaviors of various participants, we present key insights into how human assistants correct mistakes, intervene in the task completion procedure, and ground their instructions to the environment. HoloAssist spans 166 hours of data captured by 350 unique instructor-performer pairs. Furthermore, we construct and present benchmarks on mistake detection, intervention type prediction, and hand forecasting, along with detailed analysis. We expect HoloAssist will provide an important resource for building AI assistants that can fluidly collaborate with humans in the real world. Data can be downloaded at https://holoassist.github.io/.
Visual-Semantic Scene Understanding by Sharing Labels in a Context Network
Sep 16, 2013

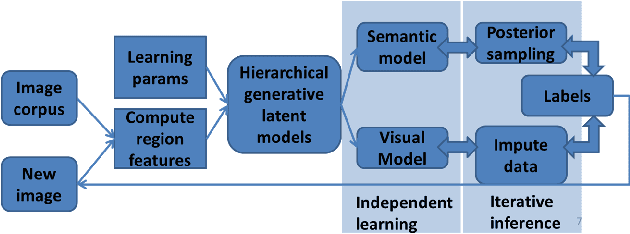

We consider the problem of naming objects in complex, natural scenes containing widely varying object appearance and subtly different names. Informed by cognitive research, we propose an approach based on sharing context based object hypotheses between visual and lexical spaces. To this end, we present the Visual Semantic Integration Model (VSIM) that represents object labels as entities shared between semantic and visual contexts and infers a new image by updating labels through context switching. At the core of VSIM is a semantic Pachinko Allocation Model and a visual nearest neighbor Latent Dirichlet Allocation Model. For inference, we derive an iterative Data Augmentation algorithm that pools the label probabilities and maximizes the joint label posterior of an image. Our model surpasses the performance of state-of-art methods in several visual tasks on the challenging SUN09 dataset.