 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Semantic Scene Understanding by Sharing Labels in a Context Network
Paper and Code
Sep 16, 2013

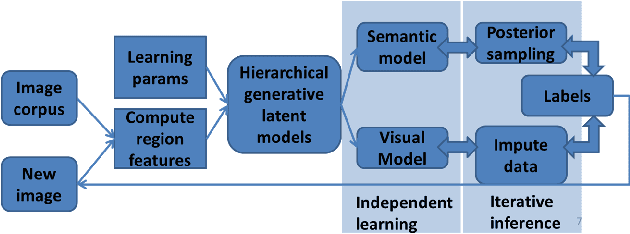

We consider the problem of naming objects in complex, natural scenes containing widely varying object appearance and subtly different names. Informed by cognitive research, we propose an approach based on sharing context based object hypotheses between visual and lexical spaces. To this end, we present the Visual Semantic Integration Model (VSIM) that represents object labels as entities shared between semantic and visual contexts and infers a new image by updating labels through context switching. At the core of VSIM is a semantic Pachinko Allocation Model and a visual nearest neighbor Latent Dirichlet Allocation Model. For inference, we derive an iterative Data Augmentation algorithm that pools the label probabilities and maximizes the joint label posterior of an image. Our model surpasses the performance of state-of-art methods in several visual tasks on the challenging SUN09 dataset.