 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlUDA: Controllable Diffusion-assisted Unsupervised Domain Adaptation for Cross-Weather Semantic Segmentation
Paper and Code
Feb 09, 2024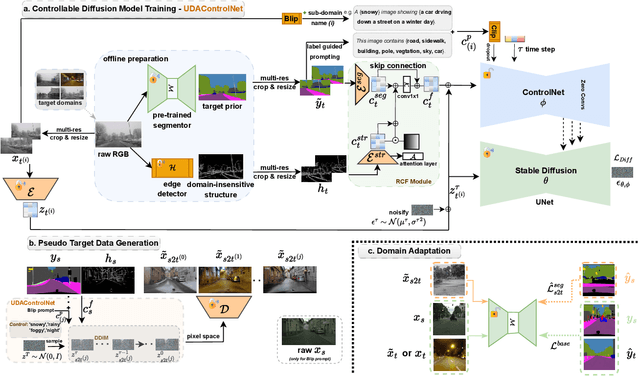



Data generation is recognized as a potent strategy for unsupervised domain adaptation (UDA) pertaining semantic segmentation in adverse weathers. Nevertheless, these adverse weather scenarios encompass multiple possibilities, and high-fidelity data synthesis with controllable weather is under-researched in previous UDA works. The recent strides in large-scale text-to-image diffusion models (DM) have ushered in a novel avenue for research, enabling the generation of realistic images conditioned on semantic labels. This capability proves instrumental for cross-domain data synthesis from source to target domain owing to their shared label space. Thus, source domain labels can be paired with those generated pseudo target data for training UDA. However, from the UDA perspective, there exists several challenges for DM training: (i) ground-truth labels from target domain are missing; (ii) the prompt generator may produce vague or noisy descriptions of images from adverse weathers; (iii) existing arts often struggle to well handle the complex scene structure and geometry of urban scenes when conditioned only on semantic labels. To tackle the above issues, we propose ControlUDA, a diffusion-assisted framework tailored for UDA segmentation under adverse weather conditions. It first leverages target prior from a pre-trained segmentor for tuning the DM, compensating the missing target domain labels; It also contains UDAControlNet, a condition-fused multi-scale and prompt-enhanced network targeted at high-fidelity data generation in adverse weathers. Training UDA with our generated data brings the model performances to a new milestone (72.0 mIoU) on the popular Cityscapes-to-ACDC benchmark for adverse weathers. Furthermore, ControlUDA helps to achieve good model generalizability on unseen data.