 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Understanding: From Geometry and Semantics to Unified Models
Mar 18, 2026Video understanding aims to enable models to perceive, reason about, and interact with the dynamic visual world. In contrast to image understanding, video understanding inherently requires modeling temporal dynamics and evolving visual context, placing stronger demands on spatiotemporal reasoning and making it a foundational problem in computer vision. In this survey, we present a structured overview of video understanding by organizing the literature into three complementary perspectives: low-level video geometry understanding, high-level semantic understanding, and unified video understanding models. We further highlight a broader shift from isolated, task-specific pipelines toward unified modeling paradigms that can be adapted to diverse downstream objectives, enabling a more systematic view of recent progress. By consolidating these perspectives, this survey provides a coherent map of the evolving video understanding landscape, summarizes key modeling trends and design principles, and outlines open challenges toward building robust, scalable, and unified video foundation models.
* A comprehensive survey of video understanding, spanning low-level geometry, high-level semantics, and unified understanding models
Stable Segment Anything Model
Dec 05, 2023The Segment Anything Model (SAM) achieves remarkable promptable segmentation given high-quality prompts which, however, often require good skills to specify. To make SAM robust to casual prompts, this paper presents the first comprehensive analysis on SAM's segmentation stability across a diverse spectrum of prompt qualities, notably imprecise bounding boxes and insufficient points. Our key finding reveals that given such low-quality prompts, SAM's mask decoder tends to activate image features that are biased towards the background or confined to specific object parts. To mitigate this issue, our key idea consists of calibrating solely SAM's mask attention by adjusting the sampling locations and amplitudes of image features, while the original SAM model architecture and weights remain unchanged. Consequently, our deformable sampling plugin (DSP) enables SAM to adaptively shift attention to the prompted target regions in a data-driven manner, facilitated by our effective robust training strategy (RTS). During inference, dynamic routing plugin (DRP) is proposed that toggles SAM between the deformable and regular grid sampling modes, conditioned on the input prompt quality. Thus, our solution, termed Stable-SAM, offers several advantages: 1) improved SAM's segmentation stability across a wide range of prompt qualities, while 2) retaining SAM's powerful promptable segmentation efficiency and generality, with 3) minimal learnable parameters (0.08 M) and fast adaptation (by 1 training epoch). Extensive experiments across multiple datasets validate the effectiveness and advantages of our approach, underscoring Stable-SAM as a more robust solution for segmenting anything. Codes will be released upon acceptance. https://github.com/fanq15/Stable-SAM
Gaussian Grouping: Segment and Edit Anything in 3D Scenes
Dec 01, 2023
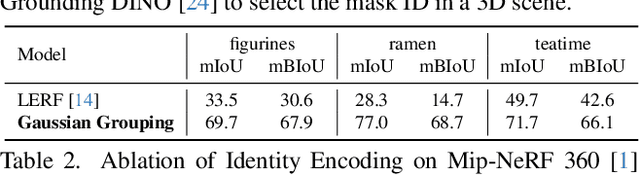


The recent Gaussian Splatting achieves high-quality and real-time novel-view synthesis of the 3D scenes. However, it is solely concentrated on the appearance and geometry modeling, while lacking in fine-grained object-level scene understanding. To address this issue, we propose Gaussian Grouping, which extends Gaussian Splatting to jointly reconstruct and segment anything in open-world 3D scenes. We augment each Gaussian with a compact Identity Encoding, allowing the Gaussians to be grouped according to their object instance or stuff membership in the 3D scene. Instead of resorting to expensive 3D labels, we supervise the Identity Encodings during the differentiable rendering by leveraging the 2D mask predictions by SAM, along with introduced 3D spatial consistency regularization. Comparing to the implicit NeRF representation, we show that the discrete and grouped 3D Gaussians can reconstruct, segment and edit anything in 3D with high visual quality, fine granularity and efficiency. Based on Gaussian Grouping, we further propose a local Gaussian Editing scheme, which shows efficacy in versatile scene editing applications, including 3D object removal, inpainting, colorization and scene recomposition. Our code and models will be at https://github.com/lkeab/gaussian-grouping.
Cascade-DETR: Delving into High-Quality Universal Object Detection
Jul 20, 2023Object localization in general environments is a fundamental part of vision systems. While dominating on the COCO benchmark, recent Transformer-based detection methods are not competitive in diverse domains. Moreover, these methods still struggle to very accurately estimate the object bounding boxes in complex environments. We introduce Cascade-DETR for high-quality universal object detection. We jointly tackle the generalization to diverse domains and localization accuracy by proposing the Cascade Attention layer, which explicitly integrates object-centric information into the detection decoder by limiting the attention to the previous box prediction. To further enhance accuracy, we also revisit the scoring of queries. Instead of relying on classification scores, we predict the expected IoU of the query, leading to substantially more well-calibrated confidences. Lastly, we introduce a universal object detection benchmark, UDB10, that contains 10 datasets from diverse domains. While also advancing the state-of-the-art on COCO, Cascade-DETR substantially improves DETR-based detectors on all datasets in UDB10, even by over 10 mAP in some cases. The improvements under stringent quality requirements are even more pronounced. Our code and models will be released at https://github.com/SysCV/cascade-detr.
Segment Anything in High Quality
Jun 02, 2023



The recent Segment Anything Model (SAM) represents a big leap in scaling up segmentation models, allowing for powerful zero-shot capabilities and flexible prompting. Despite being trained with 1.1 billion masks, SAM's mask prediction quality falls short in many cases, particularly when dealing with objects that have intricate structures. We propose HQ-SAM, equipping SAM with the ability to accurately segment any object, while maintaining SAM's original promptable design, efficiency, and zero-shot generalizability. Our careful design reuses and preserves the pre-trained model weights of SAM, while only introducing minimal additional parameters and computation. We design a learnable High-Quality Output Token, which is injected into SAM's mask decoder and is responsible for predicting the high-quality mask. Instead of only applying it on mask-decoder features, we first fuse them with early and final ViT features for improved mask details. To train our introduced learnable parameters, we compose a dataset of 44K fine-grained masks from several sources. HQ-SAM is only trained on the introduced detaset of 44k masks, which takes only 4 hours on 8 GPUs. We show the efficacy of HQ-SAM in a suite of 9 diverse segmentation datasets across different downstream tasks, where 7 out of them are evaluated in a zero-shot transfer protocol. Our code and models will be released at https://github.com/SysCV/SAM-HQ.