 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCartoon Hallucinations Detection: Pose-aware In Context Visual Learning
Mar 25, 2024



Large-scale Text-to-Image (TTI) models have become a common approach for generating training data in various generative fields. However, visual hallucinations, which contain perceptually critical defects, remain a concern, especially in non-photorealistic styles like cartoon characters. We propose a novel visual hallucination detection system for cartoon character images generated by TTI models. Our approach leverages pose-aware in-context visual learning (PA-ICVL) with Vision-Language Models (VLMs), utilizing both RGB images and pose information. By incorporating pose guidance from a fine-tuned pose estimator, we enable VLMs to make more accurate decisions. Experimental results demonstrate significant improvements in identifying visual hallucinations compared to baseline methods relying solely on RGB images. This research advances TTI models by mitigating visual hallucinations, expanding their potential in non-photorealistic domains.
ToonAging: Face Re-Aging upon Artistic Portrait Style Transfer
Feb 05, 2024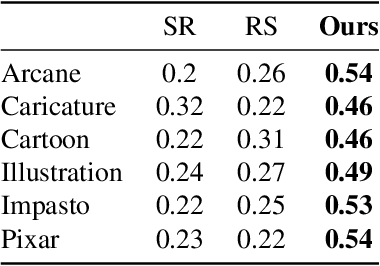

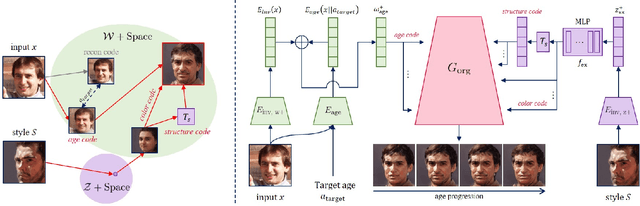
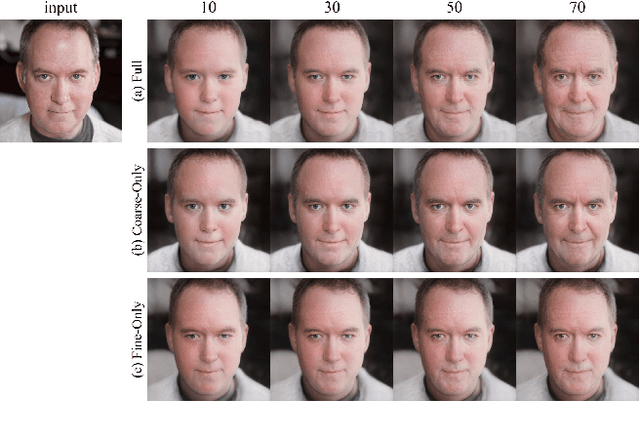
Face re-aging is a prominent field in computer vision and graphics, with significant applications in photorealistic domains such as movies, advertising, and live streaming. Recently, the need to apply face re-aging to non-photorealistic images, like comics, illustrations, and animations, has emerged as an extension in various entertainment sectors. However, the absence of a network capable of seamlessly editing the apparent age on NPR images means that these tasks have been confined to a naive approach, applying each task sequentially. This often results in unpleasant artifacts and a loss of facial attributes due to domain discrepancies. In this paper, we introduce a novel one-stage method for face re-aging combined with portrait style transfer, executed in a single generative step. We leverage existing face re-aging and style transfer networks, both trained within the same PR domain. Our method uniquely fuses distinct latent vectors, each responsible for managing aging-related attributes and NPR appearance. Adopting an exemplar-based approach, our method offers greater flexibility than domain-level fine-tuning approaches, which typically require separate training or fine-tuning for each domain. This effectively addresses the limitation of requiring paired datasets for re-aging and domain-level, data-driven approaches for stylization. Our experiments show that our model can effortlessly generate re-aged images while simultaneously transferring the style of examples, maintaining both natural appearance and controllability.
Video Face Re-Aging: Toward Temporally Consistent Face Re-Aging
Dec 07, 2023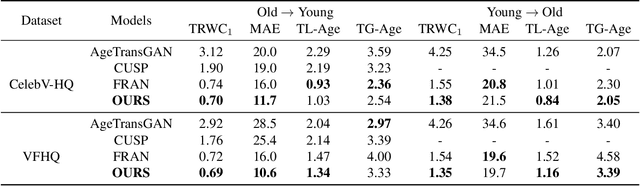
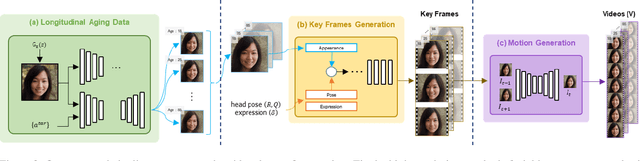
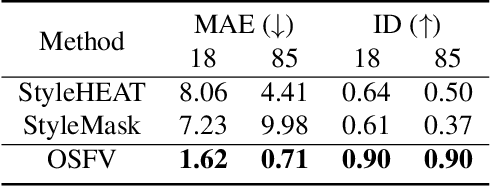
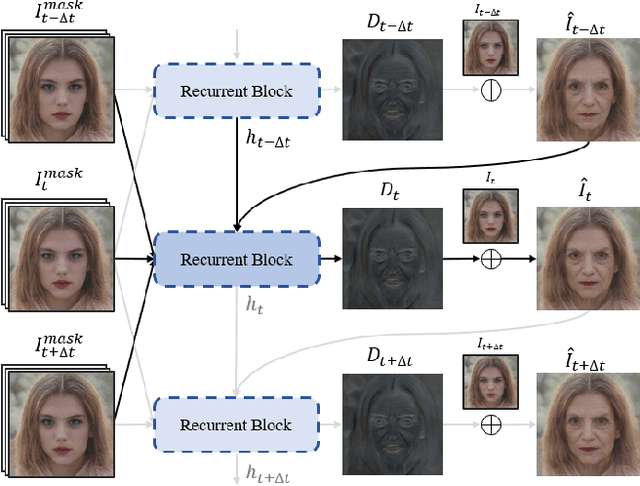
Video face re-aging deals with altering the apparent age of a person to the target age in videos. This problem is challenging due to the lack of paired video datasets maintaining temporal consistency in identity and age. Most re-aging methods process each image individually without considering the temporal consistency of videos. While some existing works address the issue of temporal coherence through video facial attribute manipulation in latent space, they often fail to deliver satisfactory performance in age transformation. To tackle the issues, we propose (1) a novel synthetic video dataset that features subjects across a diverse range of age groups; (2) a baseline architecture designed to validate the effectiveness of our proposed dataset, and (3) the development of three novel metrics tailored explicitly for evaluating the temporal consistency of video re-aging techniques. Our comprehensive experiments on public datasets, such as VFHQ and CelebV-HQ, show that our method outperforms the existing approaches in terms of both age transformation and temporal consistency.