 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Framework to Jointly Compress and Index Remote Sensing Images for Efficient Content-Based Retrieval
Jan 17, 2022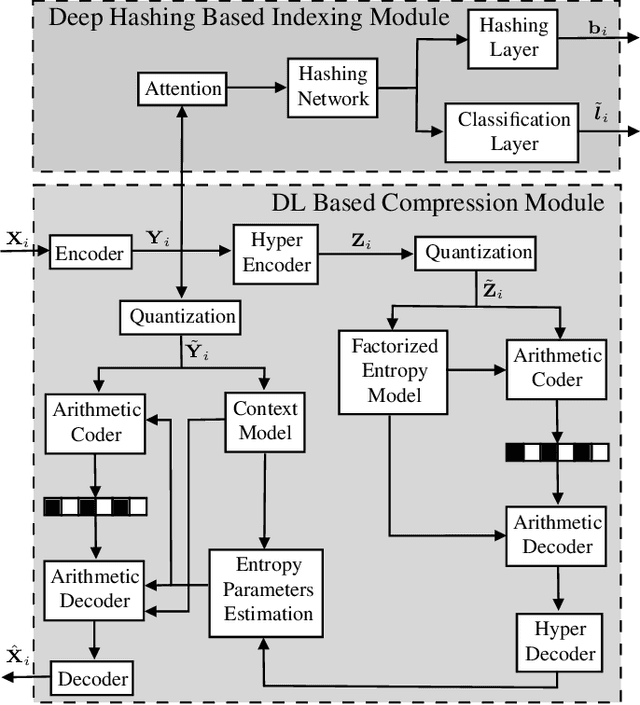
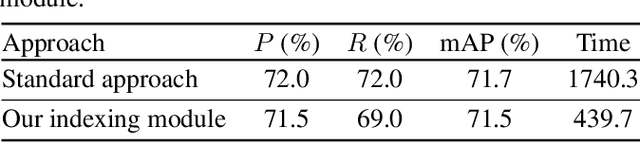
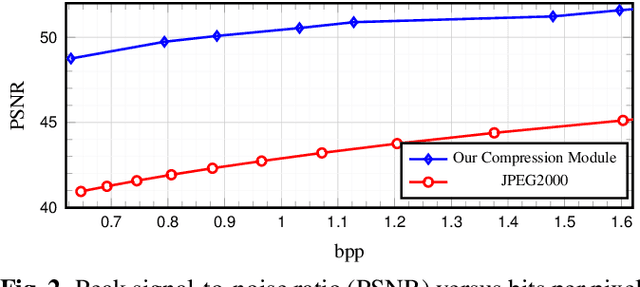

Remote sensing (RS) images are usually stored in compressed format to reduce the storage size of the archives. Thus, existing content-based image retrieval (CBIR) systems in RS require decoding images before applying CBIR (which is computationally demanding in the case of large-scale CBIR problems). To address this problem, in this paper, we present a joint framework that simultaneously learns RS image compression and indexing, eliminating the need for decoding RS images before applying CBIR. The proposed framework is made up of two modules. The first module aims at effectively compressing RS images. It is achieved based on an auto-encoder architecture. The second module aims at producing hash codes with a high discrimination capability. It is achieved based on a deep hashing method that exploits soft pairwise, bit-balancing and classification loss functions. We also propose a two stage learning strategy with gradient manipulation techniques to obtain image representations that are compatible with both RS image indexing and compression. Experimental results show the compression and CBIR efficacy of the proposed framework when compared to widely used approaches in RS. The code of the proposed framework is available at https://git.tu-berlin.de/rsim/RS-JCIF.
Analyzing Perception-Distortion Tradeoff using Enhanced Perceptual Super-resolution Network
Nov 04, 2018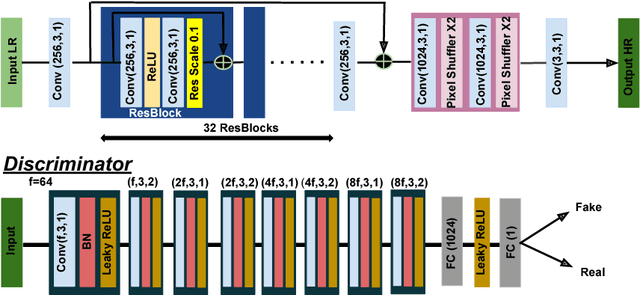
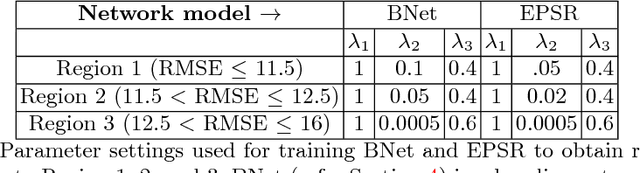
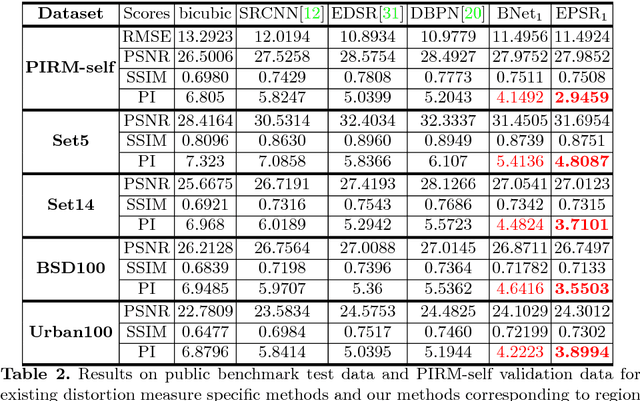

Convolutional neural network (CNN) based methods have recently achieved great success for image super-resolution (SR). However, most deep CNN based SR models attempt to improve distortion measures (e.g. PSNR, SSIM, IFC, VIF) while resulting in poor quantified perceptual quality (e.g. human opinion score, no-reference quality measures such as NIQE). Few works have attempted to improve the perceptual quality at the cost of performance reduction in distortion measures. A very recent study has revealed that distortion and perceptual quality are at odds with each other and there is always a trade-off between the two. Often the restoration algorithms that are superior in terms of perceptual quality, are inferior in terms of distortion measures. Our work attempts to analyze the trade-off between distortion and perceptual quality for the problem of single image SR. To this end, we use the well-known SR architecture-enhanced deep super-resolution (EDSR) network and show that it can be adapted to achieve better perceptual quality for a specific range of the distortion measure. While the original network of EDSR was trained to minimize the error defined based on per-pixel accuracy alone, we train our network using a generative adversarial network framework with EDSR as the generator module. Our proposed network, called enhanced perceptual super-resolution network (EPSR), is trained with a combination of mean squared error loss, perceptual loss, and adversarial loss. Our experiments reveal that EPSR achieves the state-of-the-art trade-off between distortion and perceptual quality while the existing methods perform well in either of these measures alone.
PIRM Challenge on Perceptual Image Enhancement on Smartphones: Report
Oct 03, 2018
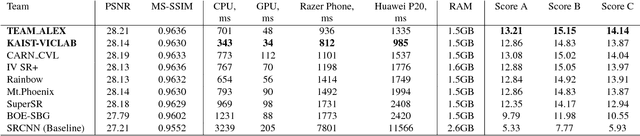

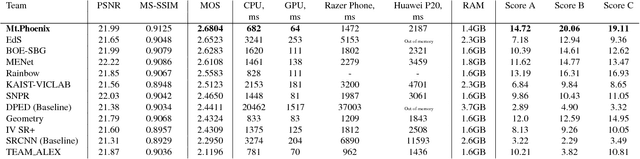
This paper reviews the first challenge on efficient perceptual image enhancement with the focus on deploying deep learning models on smartphones. The challenge consisted of two tracks. In the first one, participants were solving the classical image super-resolution problem with a bicubic downscaling factor of 4. The second track was aimed at real-world photo enhancement, and the goal was to map low-quality photos from the iPhone 3GS device to the same photos captured with a DSLR camera. The target metric used in this challenge combined the runtime, PSNR scores and solutions' perceptual results measured in the user study. To ensure the efficiency of the submitted models, we additionally measured their runtime and memory requirements on Android smartphones. The proposed solutions significantly improved baseline results defining the state-of-the-art for image enhancement on smartphones.