 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Unpaired Single Image Super-Resolution of Faces
Jan 22, 2022



We propose an adversarial attack for facial class-specific Single Image Super-Resolution (SISR) methods. Existing attacks, such as the Fast Gradient Sign Method (FGSM) or the Projected Gradient Descent (PGD) method, are either fast but ineffective, or effective but prohibitively slow on these networks. By closely inspecting the surface that the MSE loss, used to train such networks, traces under varying degradations, we were able to identify its parameterizable property. We leverage this property to propose an adverasrial attack that is able to locate the optimum degradation (effective) without needing multiple gradient-ascent steps (fast). Our experiments show that the proposed method is able to achieve a better speed vs effectiveness trade-off than the state-of-theart adversarial attacks, such as FGSM and PGD, for the task of unpaired facial as well as class-specific SISR.
Robust Super-Resolution of Real Faces using Smooth Features
Nov 04, 2020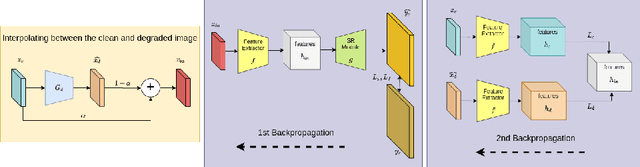

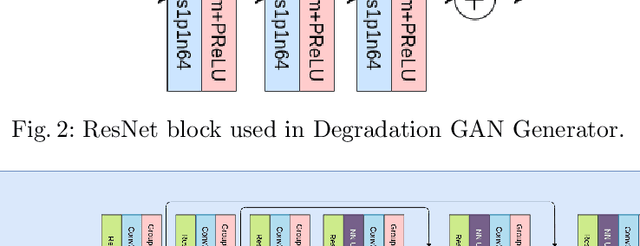
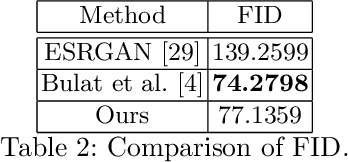
Real low-resolution (LR) face images contain degradations which are too varied and complex to be captured by known downsampling kernels and signal-independent noises. So, in order to successfully super-resolve real faces, a method needs to be robust to a wide range of noise, blur, compression artifacts etc. Some of the recent works attempt to model these degradations from a dataset of real images using a Generative Adversarial Network (GAN). They generate synthetically degraded LR images and use them with corresponding real high-resolution(HR) image to train a super-resolution (SR) network using a combination of a pixel-wise loss and an adversarial loss. In this paper, we propose a two module super-resolution network where the feature extractor module extracts robust features from the LR image, and the SR module generates an HR estimate using only these robust features. We train a degradation GAN to convert bicubically downsampled clean images to real degraded images, and interpolate between the obtained degraded LR image and its clean LR counterpart. This interpolated LR image is then used along with it's corresponding HR counterpart to train the super-resolution network from end to end. Entropy Regularized Wasserstein Divergence is used to force the encoded features learnt from the clean and degraded images to closely resemble those extracted from the interpolated image to ensure robustness.
Analyzing Perception-Distortion Tradeoff using Enhanced Perceptual Super-resolution Network
Nov 04, 2018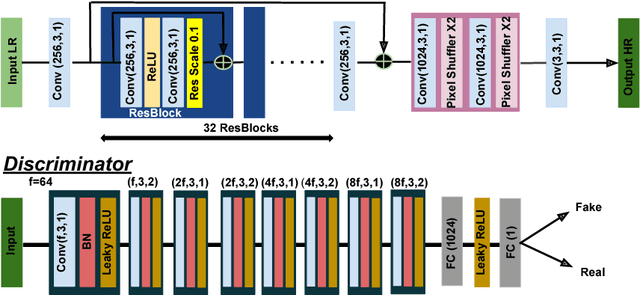
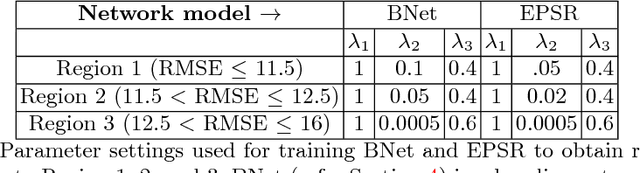
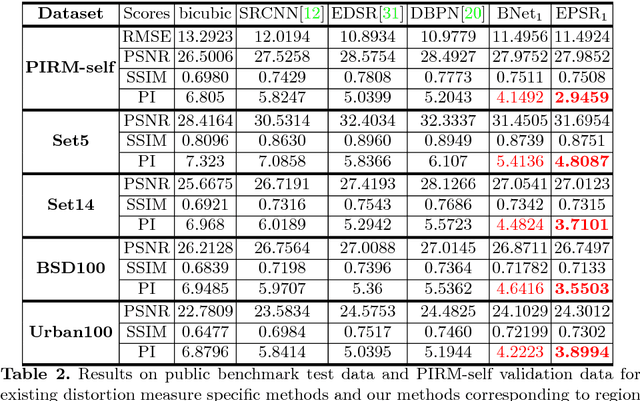

Convolutional neural network (CNN) based methods have recently achieved great success for image super-resolution (SR). However, most deep CNN based SR models attempt to improve distortion measures (e.g. PSNR, SSIM, IFC, VIF) while resulting in poor quantified perceptual quality (e.g. human opinion score, no-reference quality measures such as NIQE). Few works have attempted to improve the perceptual quality at the cost of performance reduction in distortion measures. A very recent study has revealed that distortion and perceptual quality are at odds with each other and there is always a trade-off between the two. Often the restoration algorithms that are superior in terms of perceptual quality, are inferior in terms of distortion measures. Our work attempts to analyze the trade-off between distortion and perceptual quality for the problem of single image SR. To this end, we use the well-known SR architecture-enhanced deep super-resolution (EDSR) network and show that it can be adapted to achieve better perceptual quality for a specific range of the distortion measure. While the original network of EDSR was trained to minimize the error defined based on per-pixel accuracy alone, we train our network using a generative adversarial network framework with EDSR as the generator module. Our proposed network, called enhanced perceptual super-resolution network (EPSR), is trained with a combination of mean squared error loss, perceptual loss, and adversarial loss. Our experiments reveal that EPSR achieves the state-of-the-art trade-off between distortion and perceptual quality while the existing methods perform well in either of these measures alone.