 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffinity Space Adaptation for Semantic Segmentation Across Domains
Sep 26, 2020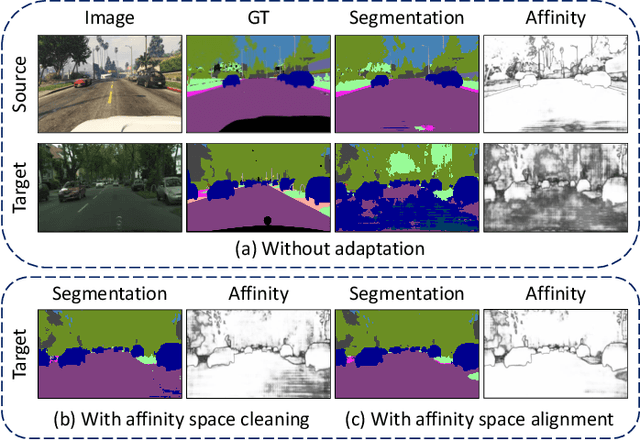
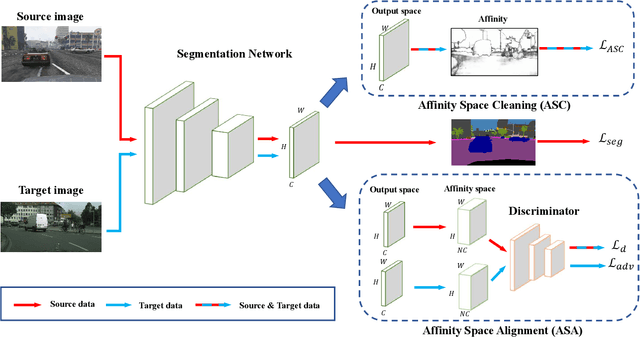

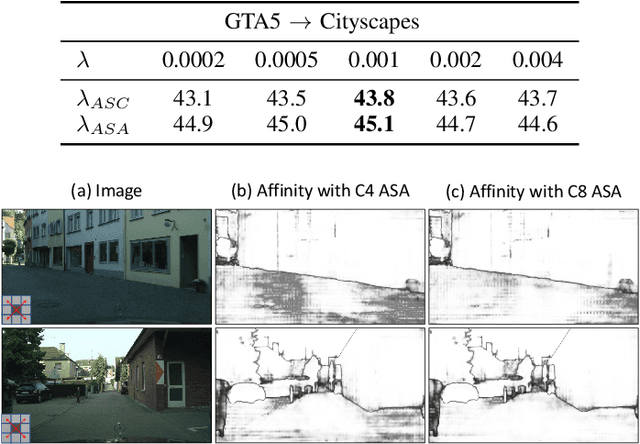
Semantic segmentation with dense pixel-wise annotation has achieved excellent performance thanks to deep learning. However, the generalization of semantic segmentation in the wild remains challenging. In this paper, we address the problem of unsupervised domain adaptation (UDA) in semantic segmentation. Motivated by the fact that source and target domain have invariant semantic structures, we propose to exploit such invariance across domains by leveraging co-occurring patterns between pairwise pixels in the output of structured semantic segmentation. This is different from most existing approaches that attempt to adapt domains based on individual pixel-wise information in image, feature, or output level. Specifically, we perform domain adaptation on the affinity relationship between adjacent pixels termed affinity space of source and target domain. To this end, we develop two affinity space adaptation strategies: affinity space cleaning and adversarial affinity space alignment. Extensive experiments demonstrate that the proposed method achieves superior performance against some state-of-the-art methods on several challenging benchmarks for semantic segmentation across domains. The code is available at https://github.com/idealwei/ASANet.
Learning Directional Feature Maps for Cardiac MRI Segmentation
Jul 22, 2020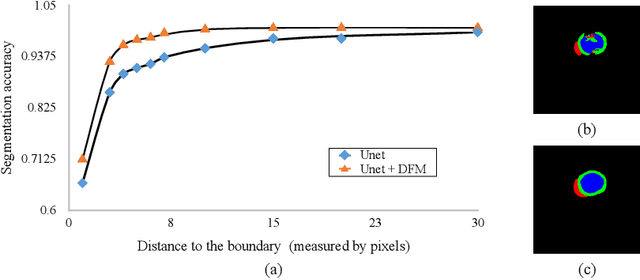
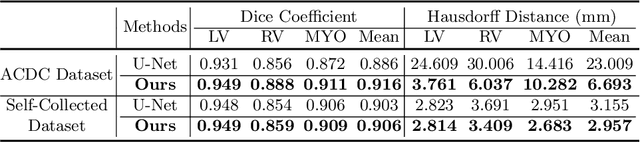
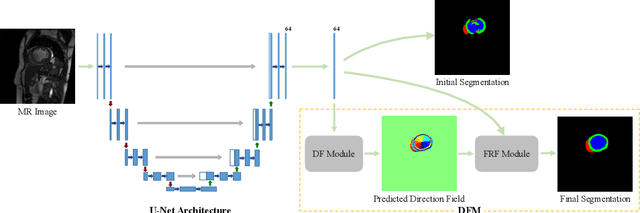
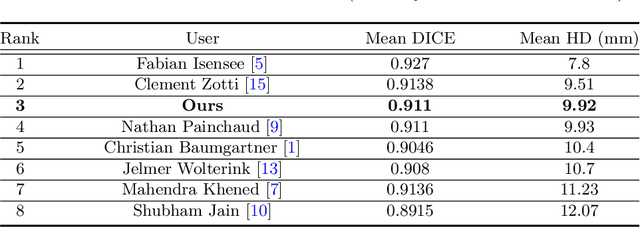
Cardiac MRI segmentation plays a crucial role in clinical diagnosis for evaluating personalized cardiac performance parameters. Due to the indistinct boundaries and heterogeneous intensity distributions in the cardiac MRI, most existing methods still suffer from two aspects of challenges: inter-class indistinction and intra-class inconsistency. To tackle these two problems, we propose a novel method to exploit the directional feature maps, which can simultaneously strengthen the differences between classes and the similarities within classes. Specifically, we perform cardiac segmentation and learn a direction field pointing away from the nearest cardiac tissue boundary to each pixel via a direction field (DF) module. Based on the learned direction field, we then propose a feature rectification and fusion (FRF) module to improve the original segmentation features, and obtain the final segmentation. The proposed modules are simple yet effective and can be flexibly added to any existing segmentation network without excessively increasing time and space complexity. We evaluate the proposed method on the 2017 MICCAI Automated Cardiac Diagnosis Challenge (ACDC) dataset and a large-scale self-collected dataset, showing good segmentation performance and robust generalization ability of the proposed method.
Gliding vertex on the horizontal bounding box for multi-oriented object detection
Nov 21, 2019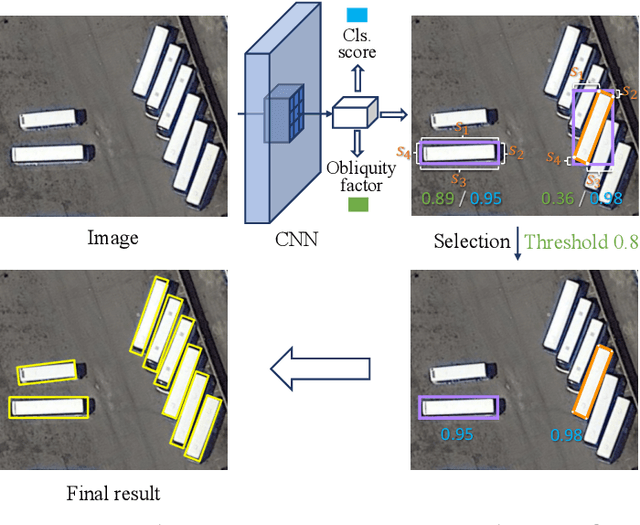
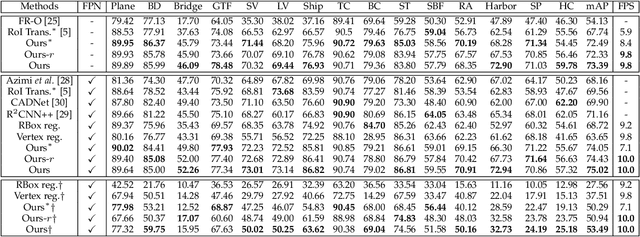
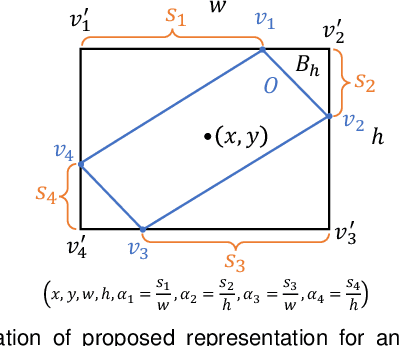
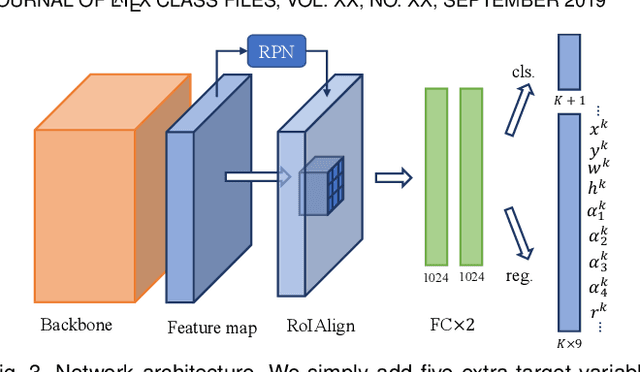
Object detection has recently experienced substantial progress. Yet, the widely adopted horizontal bounding box representation is not appropriate for ubiquitous oriented objects such as objects in aerial images and scene texts. In this paper, we propose a simple yet effective framework to detect multi-oriented objects. Instead of directly regressing the four vertices, we glide the vertex of the horizontal bounding box on each corresponding side to accurately describe a multi-oriented object. Specifically, We regress four length ratios characterizing the relative gliding offset on each corresponding side. This may facilitate the offset learning and avoid the confusion issue of sequential label points for oriented objects. To further remedy the confusion issue for nearly horizontal objects, we also introduce an obliquity factor based on area ratio between the object and its horizontal bounding box, guiding the selection of horizontal or oriented detection for each object. We add these five extra target variables to the regression head of fast R-CNN, which requires ignorable extra computation time. Extensive experimental results demonstrate that without bells and whistles, the proposed method achieves superior performances on multiple multi-oriented object detection benchmarks including object detection in aerial images, scene text detection, pedestrian detection in fisheye images.
TextField: Learning A Deep Direction Field for Irregular Scene Text Detection
Dec 04, 2018

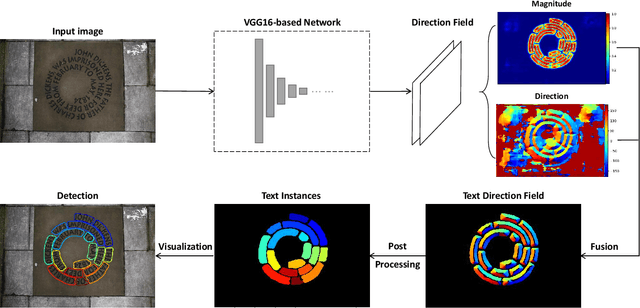
Scene text detection is an important step of scene text reading system. The main challenges lie on significantly varied sizes and aspect ratios, arbitrary orientations and shapes. Driven by recent progress in deep learning, impressive performances have been achieved for multi-oriented text detection. Yet, the performance drops dramatically in detecting curved texts due to the limited text representation (e.g., horizontal bounding boxes, rotated rectangles, or quadrilaterals). It is of great interest to detect curved texts, which are actually very common in natural scenes. In this paper, we present a novel text detector named TextField for detecting irregular scene texts. Specifically, we learn a direction field pointing away from the nearest text boundary to each text point. This direction field is represented by an image of two-dimensional vectors and learned via a fully convolutional neural network. It encodes both binary text mask and direction information used to separate adjacent text instances, which is challenging for classical segmentation-based approaches. Based on the learned direction field, we apply a simple yet effective morphological-based post-processing to achieve the final detection. Experimental results show that the proposed TextField outperforms the state-of-the-art methods by a large margin (28% and 8%) on two curved text datasets: Total-Text and CTW1500, respectively, and also achieves very competitive performance on multi-oriented datasets: ICDAR 2015 and MSRA-TD500. Furthermore, TextField is robust in generalizing to unseen datasets.
DeepFlux for Skeletons in the Wild
Nov 30, 2018
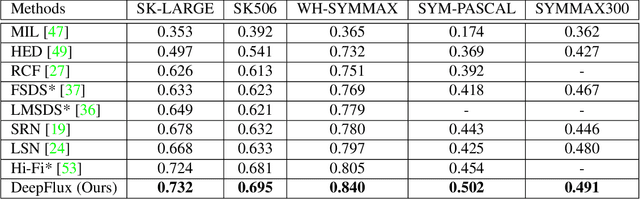
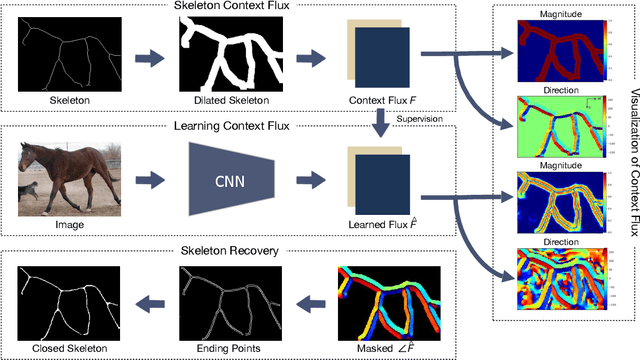
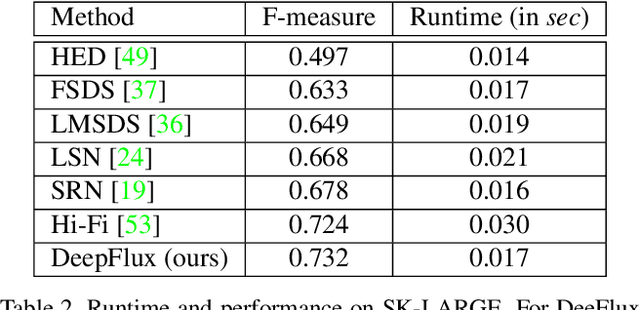
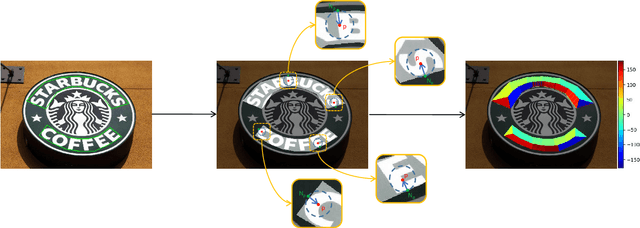
Computing object skeletons in natural images is challenging, owing to large variations in object appearance and scale, and the complexity of handling background clutter. Many recent methods frame object skeleton detection as a binary pixel classification problem, which is similar in spirit to learning-based edge detection, as well as to semantic segmentation methods. In the present article, we depart from this strategy by training a CNN to predict a two-dimensional vector field, which maps each scene point to a candidate skeleton pixel, in the spirit of flux-based skeletonization algorithms. This "image context flux" representation has two major advantages over previous approaches. First, it explicitly encodes the relative position of skeletal pixels to semantically meaningful entities, such as the image points in their spatial context, and hence also the implied object boundaries. Second, since the skeleton detection context is a region-based vector field, it is better able to cope with object parts of large width. We evaluate the proposed method on three benchmark datasets for skeleton detection and two for symmetry detection, achieving consistently superior performance over state-of-the-art methods.