 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Temporal Action Detection with Transformer
Paper and Code

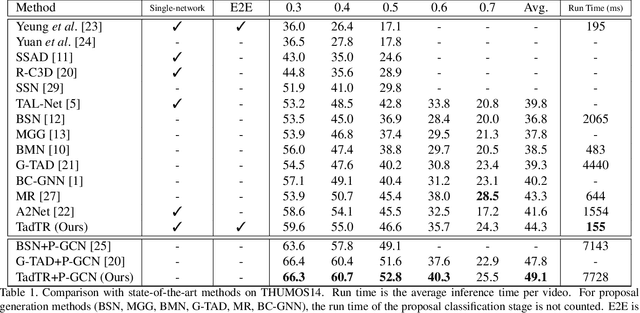

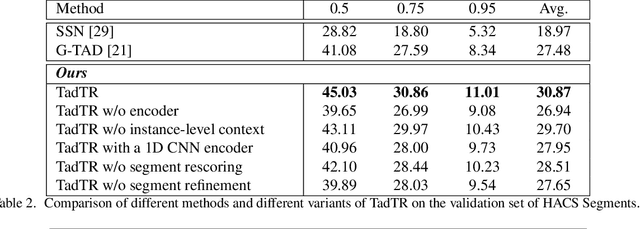
Temporal action detection (TAD) aims to determine the semantic label and the boundaries of every action instance in an untrimmed video. It is a fundamental and challenging task in video understanding and significant progress has been made. Previous methods involve multiple stages or networks and hand-designed rules or operations, which fall short in efficiency and flexibility. In this paper, we propose an end-to-end framework for TAD upon Transformer, termed \textit{TadTR}, which maps a set of learnable embeddings to action instances in parallel. TadTR is able to adaptively extract temporal context information required for making action predictions, by selectively attending to a sparse set of snippets in a video. As a result, it simplifies the pipeline of TAD and requires lower computation cost than previous detectors, while preserving remarkable detection performance. TadTR achieves state-of-the-art performance on HACS Segments (+3.35% average mAP). As a single-network detector, TadTR runs 10$\times$ faster than its comparable competitor. It outperforms existing single-network detectors by a large margin on THUMOS14 (+5.0% average mAP) and ActivityNet (+7.53% average mAP). When combined with other detectors, it reports 54.1% mAP at IoU=0.5 on THUMOS14, and 34.55% average mAP on ActivityNet-1.3. Our code will be released at \url{https://github.com/xlliu7/TadTR}.