 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuideline-grounded retrieval-augmented generation for ophthalmic clinical decision support
Mar 23, 2026In this work, we propose Oph-Guid-RAG, a multimodal visual RAG system for ophthalmology clinical question answering and decision support. We treat each guideline page as an independent evidence unit and directly retrieve page images, preserving tables, flowcharts, and layout information. We further design a controllable retrieval framework with routing and filtering, which selectively introduces external evidence and reduces noise. The system integrates query decomposition, query rewriting, retrieval, reranking, and multimodal reasoning, and provides traceable outputs with guideline page references. We evaluate our method on HealthBench using a doctor-based scoring protocol. On the hard subset, our approach improves the overall score from 0.2969 to 0.3861 (+0.0892, +30.0%) compared to GPT-5.2, and achieves higher accuracy, improving from 0.5956 to 0.6576 (+0.0620, +10.4%). Compared to GPT-5.4, our method achieves a larger accuracy gain of +0.1289 (+24.4%). These results show that our method is more effective on challenging cases that require precise, evidence-based reasoning. Ablation studies further show that reranking, routing, and retrieval design are critical for stable performance, especially under difficult settings. Overall, we show how combining visionbased retrieval with controllable reasoning can improve evidence grounding and robustness in clinical AI applications,while pointing out that further work is needed to be more complete.
Affordance-Graphed Task Worlds: Self-Evolving Task Generation for Scalable Embodied Learning
Feb 12, 2026Training robotic policies directly in the real world is expensive and unscalable. Although generative simulation enables large-scale data synthesis, current approaches often fail to generate logically coherent long-horizon tasks and struggle with dynamic physical uncertainties due to open-loop execution. To address these challenges, we propose Affordance-Graphed Task Worlds (AGT-World), a unified framework that autonomously constructs interactive simulated environments and corresponding robot task policies based on real-world observations. Unlike methods relying on random proposals or static replication, AGT-World formalizes the task space as a structured graph, enabling the precise, hierarchical decomposition of complex goals into theoretically grounded atomic primitives. Furthermore, we introduce a Self-Evolution mechanism with hybrid feedback to autonomously refine policies, combining Vision-Language Model reasoning and geometric verification. Extensive experiments demonstrate that our method significantly outperforms in success rates and generalization, achieving a self-improving cycle of proposal, execution, and correction for scalable robot learning.
GRASP: group-Shapley feature selection for patients
Feb 11, 2026Feature selection remains a major challenge in medical prediction, where existing approaches such as LASSO often lack robustness and interpretability. We introduce GRASP, a novel framework that couples Shapley value driven attribution with group $L_{21}$ regularization to extract compact and non-redundant feature sets. GRASP first distills group level importance scores from a pretrained tree model via SHAP, then enforces structured sparsity through group $L_{21}$ regularized logistic regression, yielding stable and interpretable selections. Extensive comparisons with LASSO, SHAP, and deep learning based methods show that GRASP consistently delivers comparable or superior predictive accuracy, while identifying fewer, less redundant, and more stable features.
MeniMV: A Multi-view Benchmark for Meniscus Injury Severity Grading
Dec 20, 2025Precise grading of meniscal horn tears is critical in knee injury diagnosis but remains underexplored in automated MRI analysis. Existing methods often rely on coarse study-level labels or binary classification, lacking localization and severity information. In this paper, we introduce MeniMV, a multi-view benchmark dataset specifically designed for horn-specific meniscus injury grading. MeniMV comprises 3,000 annotated knee MRI exams from 750 patients across three medical centers, providing 6,000 co-registered sagittal and coronal images. Each exam is meticulously annotated with four-tier (grade 0-3) severity labels for both anterior and posterior meniscal horns, verified by chief orthopedic physicians. Notably, MeniMV offers more than double the pathology-labeled data volume of prior datasets while uniquely capturing the dual-view diagnostic context essential in clinical practice. To demonstrate the utility of MeniMV, we benchmark multiple state-of-the-art CNN and Transformer-based models. Our extensive experiments establish strong baselines and highlight challenges in severity grading, providing a valuable foundation for future research in automated musculoskeletal imaging.
Sequence of Expert: Boosting Imitation Planners for Autonomous Driving through Temporal Alternation
Dec 15, 2025Imitation learning (IL) has emerged as a central paradigm in autonomous driving. While IL excels in matching expert behavior in open-loop settings by minimizing per-step prediction errors, its performance degrades unexpectedly in closed-loop due to the gradual accumulation of small, often imperceptible errors over time.Over successive planning cycles, these errors compound, potentially resulting in severe failures.Current research efforts predominantly rely on increasingly sophisticated network architectures or high-fidelity training datasets to enhance the robustness of IL planners against error accumulation, focusing on the state-level robustness at a single time point. However, autonomous driving is inherently a continuous-time process, and leveraging the temporal scale to enhance robustness may provide a new perspective for addressing this issue.To this end, we propose a method termed Sequence of Experts (SoE), a temporal alternation policy that enhances closed-loop performance without increasing model size or data requirements. Our experiments on large-scale autonomous driving benchmarks nuPlan demonstrate that SoE method consistently and significantly improves the performance of all the evaluated models, and achieves state-of-the-art performance.This module may provide a key and widely applicable support for improving the training efficiency of autonomous driving models.
nuCarla: A nuScenes-Style Bird's-Eye View Perception Dataset for CARLA Simulation
Nov 12, 2025

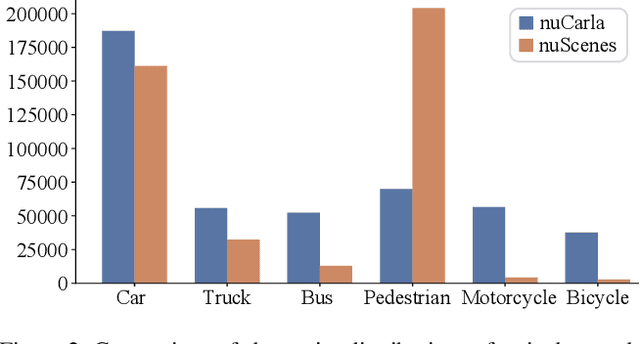

End-to-end (E2E) autonomous driving heavily relies on closed-loop simulation, where perception, planning, and control are jointly trained and evaluated in interactive environments. Yet, most existing datasets are collected from the real world under non-interactive conditions, primarily supporting open-loop learning while offering limited value for closed-loop testing. Due to the lack of standardized, large-scale, and thoroughly verified datasets to facilitate learning of meaningful intermediate representations, such as bird's-eye-view (BEV) features, closed-loop E2E models remain far behind even simple rule-based baselines. To address this challenge, we introduce nuCarla, a large-scale, nuScenes-style BEV perception dataset built within the CARLA simulator. nuCarla features (1) full compatibility with the nuScenes format, enabling seamless transfer of real-world perception models; (2) a dataset scale comparable to nuScenes, but with more balanced class distributions; (3) direct usability for closed-loop simulation deployment; and (4) high-performance BEV backbones that achieve state-of-the-art detection results. By providing both data and models as open benchmarks, nuCarla substantially accelerates closed-loop E2E development, paving the way toward reliable and safety-aware research in autonomous driving.
RADE: Learning Risk-Adjustable Driving Environment via Multi-Agent Conditional Diffusion
May 06, 2025Generating safety-critical scenarios in high-fidelity simulations offers a promising and cost-effective approach for efficient testing of autonomous vehicles. Existing methods typically rely on manipulating a single vehicle's trajectory through sophisticated designed objectives to induce adversarial interactions, often at the cost of realism and scalability. In this work, we propose the Risk-Adjustable Driving Environment (RADE), a simulation framework that generates statistically realistic and risk-adjustable traffic scenes. Built upon a multi-agent diffusion architecture, RADE jointly models the behavior of all agents in the environment and conditions their trajectories on a surrogate risk measure. Unlike traditional adversarial methods, RADE learns risk-conditioned behaviors directly from data, preserving naturalistic multi-agent interactions with controllable risk levels. To ensure physical plausibility, we incorporate a tokenized dynamics check module that efficiently filters generated trajectories using a motion vocabulary. We validate RADE on the real-world rounD dataset, demonstrating that it preserves statistical realism across varying risk levels and naturally increases the likelihood of safety-critical events as the desired risk level grows up. Our results highlight RADE's potential as a scalable and realistic tool for AV safety evaluation.
LightEMMA: Lightweight End-to-End Multimodal Model for Autonomous Driving
May 01, 2025Vision-Language Models (VLMs) have demonstrated significant potential for end-to-end autonomous driving. However, fully exploiting their capabilities for safe and reliable vehicle control remains an open research challenge. To systematically examine advances and limitations of VLMs in driving tasks, we introduce LightEMMA, a Lightweight End-to-End Multimodal Model for Autonomous driving. LightEMMA provides a unified, VLM-based autonomous driving framework without ad hoc customizations, enabling easy integration and evaluation of evolving state-of-the-art commercial and open-source models. We construct twelve autonomous driving agents using various VLMs and evaluate their performance on the nuScenes prediction task, comprehensively assessing metrics such as inference time, computational cost, and predictive accuracy. Illustrative examples highlight that, despite their strong scenario interpretation capabilities, VLMs' practical performance in autonomous driving tasks remains concerning, emphasizing the need for further improvements. The code is available at https://github.com/michigan-traffic-lab/LightEMMA.
Dynamically Local-Enhancement Planner for Large-Scale Autonomous Driving
Feb 28, 2025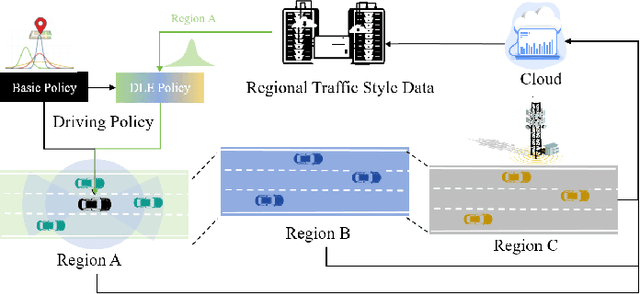
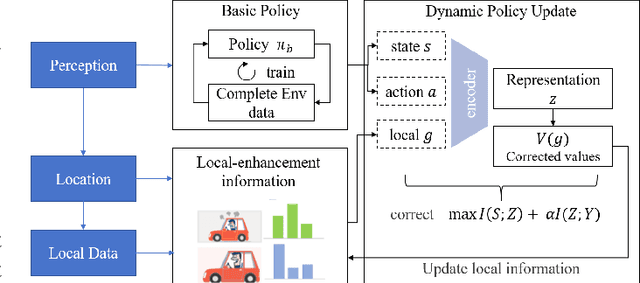
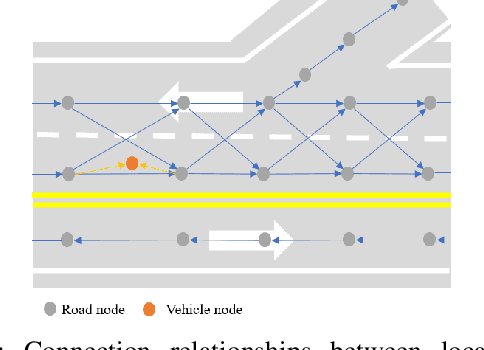
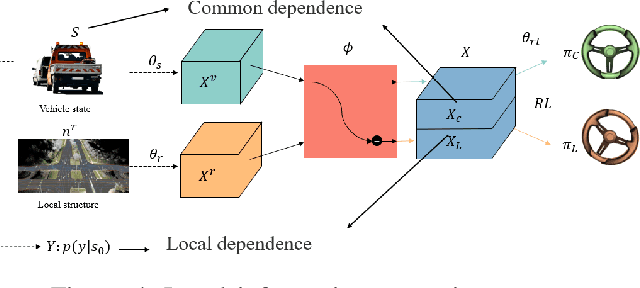
Current autonomous vehicles operate primarily within limited regions, but there is increasing demand for broader applications. However, as models scale, their limited capacity becomes a significant challenge for adapting to novel scenarios. It is increasingly difficult to improve models for new situations using a single monolithic model. To address this issue, we introduce the concept of dynamically enhancing a basic driving planner with local driving data, without permanently modifying the planner itself. This approach, termed the Dynamically Local-Enhancement (DLE) Planner, aims to improve the scalability of autonomous driving systems without significantly expanding the planner's size. Our approach introduces a position-varying Markov Decision Process formulation coupled with a graph neural network that extracts region-specific driving features from local observation data. The learned features describe the local behavior of the surrounding objects, which is then leveraged to enhance a basic reinforcement learning-based policy. We evaluated our approach in multiple scenarios and compared it with a one-for-all driving model. The results show that our method outperforms the baseline policy in both safety (collision rate) and average reward, while maintaining a lighter scale. This approach has the potential to benefit large-scale autonomous vehicles without the need for largely expanding on-device driving models.
Uncertainty-Aware Prediction and Application in Planning for Autonomous Driving: Definitions, Methods, and Comparison
Mar 04, 2024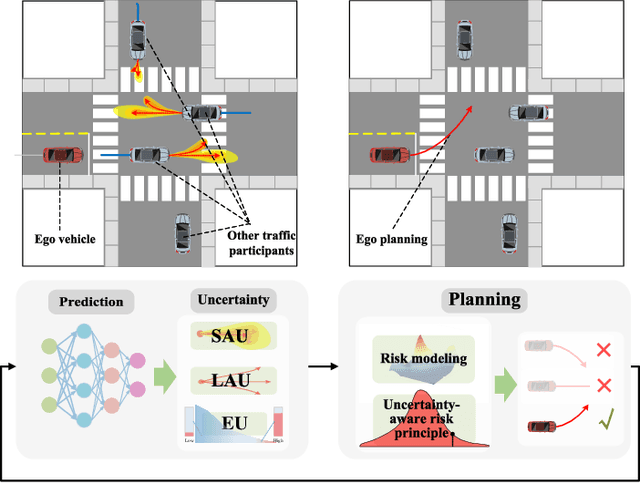

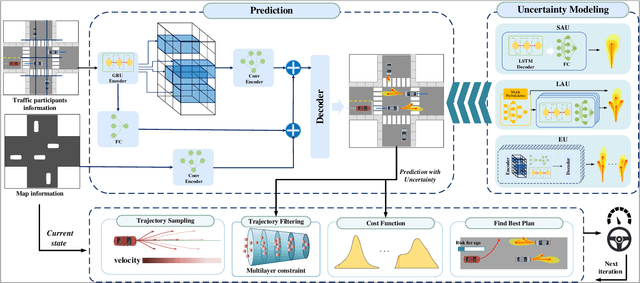

Autonomous driving systems face the formidable challenge of navigating intricate and dynamic environments with uncertainty. This study presents a unified prediction and planning framework that concurrently models short-term aleatoric uncertainty (SAU), long-term aleatoric uncertainty (LAU), and epistemic uncertainty (EU) to predict and establish a robust foundation for planning in dynamic contexts. The framework uses Gaussian mixture models and deep ensemble methods, to concurrently capture and assess SAU, LAU, and EU, where traditional methods do not integrate these uncertainties simultaneously. Additionally, uncertainty-aware planning is introduced, considering various uncertainties. The study's contributions include comparisons of uncertainty estimations, risk modeling, and planning methods in comparison to existing approaches. The proposed methods were rigorously evaluated using the CommonRoad benchmark and settings with limited perception. These experiments illuminated the advantages and roles of different uncertainty factors in autonomous driving processes. In addition, comparative assessments of various uncertainty modeling strategies underscore the benefits of modeling multiple types of uncertainties, thus enhancing planning accuracy and reliability. The proposed framework facilitates the development of methods for UAP and surpasses existing uncertainty-aware risk models, particularly when considering diverse traffic scenarios. Project page: https://swb19.github.io/UAP/.