 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSRE: Latent Semantic Rule Encoding for Real-Time Semantic Risk Detection in Autonomous Driving
Dec 31, 2025Real-world autonomous driving must adhere to complex human social rules that extend beyond legally codified traffic regulations. Many of these semantic constraints, such as yielding to emergency vehicles, complying with traffic officers' gestures, or stopping for school buses, are intuitive for humans yet difficult to encode explicitly. Although large vision-language models (VLMs) can interpret such semantics, their inference cost makes them impractical for real-time deployment.This work proposes LSRE, a Latent Semantic Rule Encoding framework that converts sparsely sampled VLM judgments into decision boundaries within the latent space of a recurrent world model. By encoding language-defined safety semantics into a lightweight latent classifier, LSRE enables real-time semantic risk assessment at 10 Hz without per-frame VLM queries. Experiments on six semantic-failure scenarios in CARLA demonstrate that LSRE attains semantic risk detection accuracy comparable to a large VLM baseline, while providing substantially earlier hazard anticipation and maintaining low computational latency. LSRE further generalizes to rarely seen semantic-similar test cases, indicating that language-guided latent classification offers an effective and deployable mechanism for semantic safety monitoring in autonomous driving.
DTCCL: Disengagement-Triggered Contrastive Continual Learning for Autonomous Bus Planners
Dec 22, 2025Autonomous buses run on fixed routes but must operate in open, dynamic urban environments. Disengagement events on these routes are often geographically concentrated and typically arise from planner failures in highly interactive regions. Such policy-level failures are difficult to correct using conventional imitation learning, which easily overfits to sparse disengagement data. To address this issue, this paper presents a Disengagement-Triggered Contrastive Continual Learning (DTCCL) framework that enables autonomous buses to improve planning policies through real-world operation. Each disengagement triggers cloud-based data augmentation that generates positive and negative samples by perturbing surrounding agents while preserving route context. Contrastive learning refines policy representations to better distinguish safe and unsafe behaviors, and continual updates are applied in a cloud-edge loop without human supervision. Experiments on urban bus routes demonstrate that DTCCL improves overall planning performance by 48.6 percent compared with direct retraining, validating its effectiveness for scalable, closed-loop policy improvement in autonomous public transport.
Are All Data Necessary? Efficient Data Pruning for Large-scale Autonomous Driving Dataset via Trajectory Entropy Maximization
Dec 22, 2025Collecting large-scale naturalistic driving data is essential for training robust autonomous driving planners. However, real-world datasets often contain a substantial amount of repetitive and low-value samples, which lead to excessive storage costs and bring limited benefits to policy learning. To address this issue, we propose an information-theoretic data pruning method that effectively reduces the training data volume without compromising model performance. Our approach evaluates the trajectory distribution information entropy of driving data and iteratively selects high-value samples that preserve the statistical characteristics of the original dataset in a model-agnostic manner. From a theoretical perspective, we show that maximizing trajectory entropy effectively constrains the Kullback-Leibler divergence between the pruned subset and the original data distribution, thereby maintaining generalization ability. Comprehensive experiments on the NuPlan benchmark with a large-scale imitation learning framework demonstrate that the proposed method can reduce the dataset size by up to 40% while maintaining closed-loop performance. This work provides a lightweight and theoretically grounded approach for scalable data management and efficient policy learning in autonomous driving systems.
Sequence of Expert: Boosting Imitation Planners for Autonomous Driving through Temporal Alternation
Dec 15, 2025Imitation learning (IL) has emerged as a central paradigm in autonomous driving. While IL excels in matching expert behavior in open-loop settings by minimizing per-step prediction errors, its performance degrades unexpectedly in closed-loop due to the gradual accumulation of small, often imperceptible errors over time.Over successive planning cycles, these errors compound, potentially resulting in severe failures.Current research efforts predominantly rely on increasingly sophisticated network architectures or high-fidelity training datasets to enhance the robustness of IL planners against error accumulation, focusing on the state-level robustness at a single time point. However, autonomous driving is inherently a continuous-time process, and leveraging the temporal scale to enhance robustness may provide a new perspective for addressing this issue.To this end, we propose a method termed Sequence of Experts (SoE), a temporal alternation policy that enhances closed-loop performance without increasing model size or data requirements. Our experiments on large-scale autonomous driving benchmarks nuPlan demonstrate that SoE method consistently and significantly improves the performance of all the evaluated models, and achieves state-of-the-art performance.This module may provide a key and widely applicable support for improving the training efficiency of autonomous driving models.
Dynamically Local-Enhancement Planner for Large-Scale Autonomous Driving
Feb 28, 2025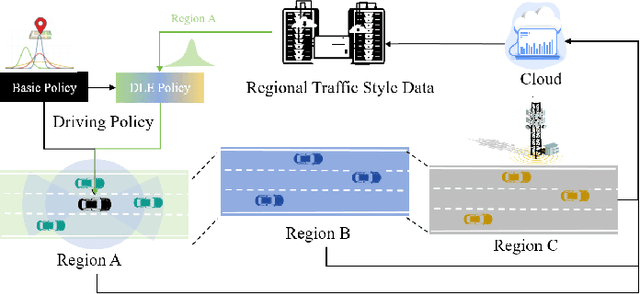
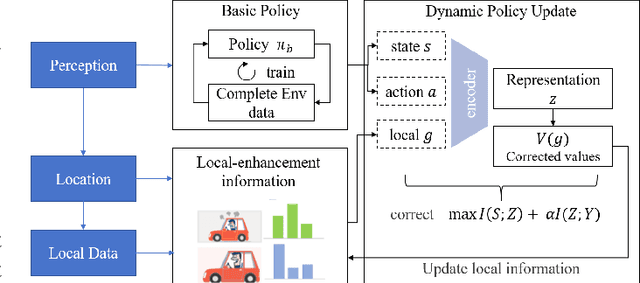
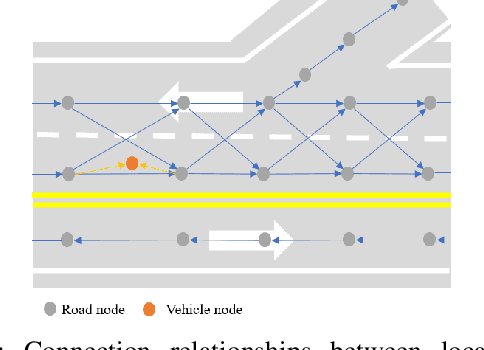
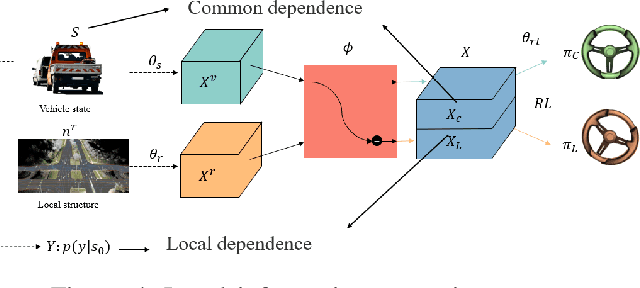
Current autonomous vehicles operate primarily within limited regions, but there is increasing demand for broader applications. However, as models scale, their limited capacity becomes a significant challenge for adapting to novel scenarios. It is increasingly difficult to improve models for new situations using a single monolithic model. To address this issue, we introduce the concept of dynamically enhancing a basic driving planner with local driving data, without permanently modifying the planner itself. This approach, termed the Dynamically Local-Enhancement (DLE) Planner, aims to improve the scalability of autonomous driving systems without significantly expanding the planner's size. Our approach introduces a position-varying Markov Decision Process formulation coupled with a graph neural network that extracts region-specific driving features from local observation data. The learned features describe the local behavior of the surrounding objects, which is then leveraged to enhance a basic reinforcement learning-based policy. We evaluated our approach in multiple scenarios and compared it with a one-for-all driving model. The results show that our method outperforms the baseline policy in both safety (collision rate) and average reward, while maintaining a lighter scale. This approach has the potential to benefit large-scale autonomous vehicles without the need for largely expanding on-device driving models.
Dynamically Conservative Self-Driving Planner for Long-Tail Cases
May 12, 2023



Self-driving vehicles (SDVs) are becoming reality but still suffer from "long-tail" challenges during natural driving: the SDVs will continually encounter rare, safety-critical cases that may not be included in the dataset they were trained. Some safety-assurance planners solve this problem by being conservative in all possible cases, which may significantly affect driving mobility. To this end, this work proposes a method to automatically adjust the conservative level according to each case's "long-tail" rate, named dynamically conservative planner (DCP). We first define the "long-tail" rate as an SDV's confidence to pass a driving case. The rate indicates the probability of safe-critical events and is estimated using the statistics bootstrapped method with historical data. Then, a reinforcement learning-based planner is designed to contain candidate policies with different conservative levels. The final policy is optimized based on the estimated "long-tail" rate. In this way, the DCP is designed to automatically adjust to be more conservative in low-confidence "long-tail" cases while keeping efficient otherwise. The DCP is evaluated in the CARLA simulator using driving cases with "long-tail" distributed training data. The results show that the DCP can accurately estimate the "long-tail" rate to identify potential risks. Based on the rate, the DCP automatically avoids potential collisions in "long-tail" cases using conservative decisions while not affecting the average velocity in other typical cases. Thus, the DCP is safer and more efficient than the baselines with fixed conservative levels, e.g., an always conservative planner. This work provides a technique to guarantee SDV's performance in unexpected driving cases without resorting to a global conservative setting, which contributes to solving the "long-tail" problem practically.
Identify, Estimate and Bound the Uncertainty of Reinforcement Learning for Autonomous Driving
May 12, 2023Deep reinforcement learning (DRL) has emerged as a promising approach for developing more intelligent autonomous vehicles (AVs). A typical DRL application on AVs is to train a neural network-based driving policy. However, the black-box nature of neural networks can result in unpredictable decision failures, making such AVs unreliable. To this end, this work proposes a method to identify and protect unreliable decisions of a DRL driving policy. The basic idea is to estimate and constrain the policy's performance uncertainty, which quantifies potential performance drop due to insufficient training data or network fitting errors. By constraining the uncertainty, the DRL model's performance is always greater than that of a baseline policy. The uncertainty caused by insufficient data is estimated by the bootstrapped method. Then, the uncertainty caused by the network fitting error is estimated using an ensemble network. Finally, a baseline policy is added as the performance lower bound to avoid potential decision failures. The overall framework is called uncertainty-bound reinforcement learning (UBRL). The proposed UBRL is evaluated on DRL policies with different amounts of training data, taking an unprotected left-turn driving case as an example. The result shows that the UBRL method can identify potentially unreliable decisions of DRL policy. The UBRL guarantees to outperform baseline policy even when the DRL policy is not well-trained and has high uncertainty. Meanwhile, the performance of UBRL improves with more training data. Such a method is valuable for the DRL application on real-road driving and provides a metric to evaluate a DRL policy.
Long-Tail Prediction Uncertainty Aware Trajectory Planning for Self-driving Vehicles
Jul 02, 2022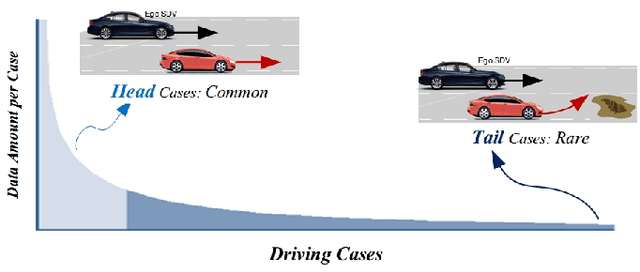
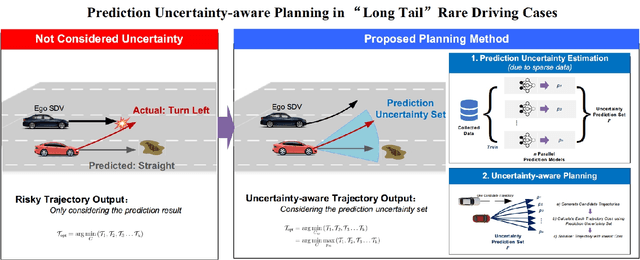
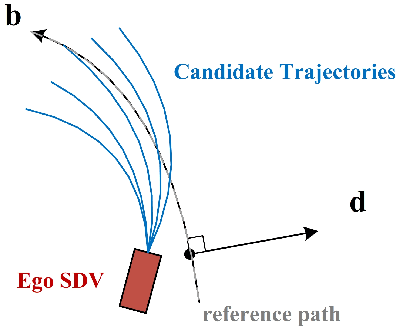
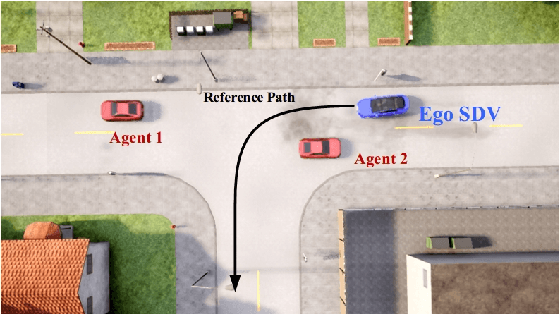
A typical trajectory planner of autonomous driving usually relies on predicting the future behavior of surrounding obstacles. In recent years, prediction models based on deep learning have been widely used due to their impressive performance. However, recent studies have shown that deep learning models trained on a dataset following a long-tailed driving scenario distribution will suffer from large prediction errors in the "tails," which might lead to failures of the planner. To this end, this work defines a notion of prediction model uncertainty to quantify high errors due to sparse data. Moreover, this work proposes a trajectory planner to consider such prediction uncertainty for safer performance. Firstly, the prediction model's uncertainty due to insufficient training data is estimated by an ensemble network structure. Then a trajectory planner is designed to consider the worst-case arising from prediction uncertainty. The results show that the proposed method can improve the safety of trajectory planning under the prediction uncertainty caused by insufficient data. At the same time, with sufficient data, the framework will not lead to overly conservative results. This technology helps to improve the safety and reliability of autonomous vehicles under the long-tail data distribution of the real world.