 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Agnostic Prompt Learning for Multi-Modal Camouflaged Object Detection
Apr 14, 2026Camouflaged Object Detection (COD) aims to segment objects that blend seamlessly into complex backgrounds, with growing interest in exploiting additional visual modalities to enhance robustness through complementary information. However, most existing approaches generally rely on modality-specific architectures or customized fusion strategies, which limit scalability and cross-modal generalization. To address this, we propose a novel framework that generates modality-agnostic multi-modal prompts for the Segment Anything Model (SAM), enabling parameter-efficient adaptation to arbitrary auxiliary modalities and significantly improving overall performance on COD tasks. Specifically, we model multi-modal learning through interactions between a data-driven content domain and a knowledge-driven prompt domain, distilling task-relevant cues into unified prompts for SAM decoding. We further introduce a lightweight Mask Refine Module to calibrate coarse predictions by incorporating fine-grained prompt cues, leading to more accurate camouflaged object boundaries. Extensive experiments on RGB-Depth, RGB-Thermal, and RGB-Polarization benchmarks validate the effectiveness and generalization of our modality-agnostic framework.
Unsupervised Domain Adaptive Person Search via Dual Self-Calibration
Dec 21, 2024



Unsupervised Domain Adaptive (UDA) person search focuses on employing the model trained on a labeled source domain dataset to a target domain dataset without any additional annotations. Most effective UDA person search methods typically utilize the ground truth of the source domain and pseudo-labels derived from clustering during the training process for domain adaptation. However, the performance of these approaches will be significantly restricted by the disrupting pseudo-labels resulting from inter-domain disparities. In this paper, we propose a Dual Self-Calibration (DSCA) framework for UDA person search that effectively eliminates the interference of noisy pseudo-labels by considering both the image-level and instance-level features perspectives. Specifically, we first present a simple yet effective Perception-Driven Adaptive Filter (PDAF) to adaptively predict a dynamic filter threshold based on input features. This threshold assists in eliminating noisy pseudo-boxes and other background interference, allowing our approach to focus on foreground targets and avoid indiscriminate domain adaptation. Besides, we further propose a Cluster Proxy Representation (CPR) module to enhance the update strategy of cluster representation, which mitigates the pollution of clusters from misidentified instances and effectively streamlines the training process for unlabeled target domains. With the above design, our method can achieve state-of-the-art (SOTA) performance on two benchmark datasets, with 80.2% mAP and 81.7% top-1 on the CUHK-SYSU dataset, with 39.9% mAP and 81.6% top-1 on the PRW dataset, which is comparable to or even exceeds the performance of some fully supervised methods. Our source code is available at https://github.com/whbdmu/DSCA.
Distractor-aware Event-based Tracking
Oct 29, 2023



Event cameras, or dynamic vision sensors, have recently achieved success from fundamental vision tasks to high-level vision researches. Due to its ability to asynchronously capture light intensity changes, event camera has an inherent advantage to capture moving objects in challenging scenarios including objects under low light, high dynamic range, or fast moving objects. Thus event camera are natural for visual object tracking. However, the current event-based trackers derived from RGB trackers simply modify the input images to event frames and still follow conventional tracking pipeline that mainly focus on object texture for target distinction. As a result, the trackers may not be robust dealing with challenging scenarios such as moving cameras and cluttered foreground. In this paper, we propose a distractor-aware event-based tracker that introduces transformer modules into Siamese network architecture (named DANet). Specifically, our model is mainly composed of a motion-aware network and a target-aware network, which simultaneously exploits both motion cues and object contours from event data, so as to discover motion objects and identify the target object by removing dynamic distractors. Our DANet can be trained in an end-to-end manner without any post-processing and can run at over 80 FPS on a single V100. We conduct comprehensive experiments on two large event tracking datasets to validate the proposed model. We demonstrate that our tracker has superior performance against the state-of-the-art trackers in terms of both accuracy and efficiency.
In the Blink of an Eye: Event-based Emotion Recognition
Oct 06, 2023



We introduce a wearable single-eye emotion recognition device and a real-time approach to recognizing emotions from partial observations of an emotion that is robust to changes in lighting conditions. At the heart of our method is a bio-inspired event-based camera setup and a newly designed lightweight Spiking Eye Emotion Network (SEEN). Compared to conventional cameras, event-based cameras offer a higher dynamic range (up to 140 dB vs. 80 dB) and a higher temporal resolution. Thus, the captured events can encode rich temporal cues under challenging lighting conditions. However, these events lack texture information, posing problems in decoding temporal information effectively. SEEN tackles this issue from two different perspectives. First, we adopt convolutional spiking layers to take advantage of the spiking neural network's ability to decode pertinent temporal information. Second, SEEN learns to extract essential spatial cues from corresponding intensity frames and leverages a novel weight-copy scheme to convey spatial attention to the convolutional spiking layers during training and inference. We extensively validate and demonstrate the effectiveness of our approach on a specially collected Single-eye Event-based Emotion (SEE) dataset. To the best of our knowledge, our method is the first eye-based emotion recognition method that leverages event-based cameras and spiking neural network.
Frame-Event Alignment and Fusion Network for High Frame Rate Tracking
May 25, 2023



Most existing RGB-based trackers target low frame rate benchmarks of around 30 frames per second. This setting restricts the tracker's functionality in the real world, especially for fast motion. Event-based cameras as bioinspired sensors provide considerable potential for high frame rate tracking due to their high temporal resolution. However, event-based cameras cannot offer fine-grained texture information like conventional cameras. This unique complementarity motivates us to combine conventional frames and events for high frame rate object tracking under various challenging conditions. Inthispaper, we propose an end-to-end network consisting of multi-modality alignment and fusion modules to effectively combine meaningful information from both modalities at different measurement rates. The alignment module is responsible for cross-style and cross-frame-rate alignment between frame and event modalities under the guidance of the moving cues furnished by events. While the fusion module is accountable for emphasizing valuable features and suppressing noise information by the mutual complement between the two modalities. Extensive experiments show that the proposed approach outperforms state-of-the-art trackers by a significant margin in high frame rate tracking. With the FE240hz dataset, our approach achieves high frame rate tracking up to 240Hz.
Object Tracking by Jointly Exploiting Frame and Event Domain
Sep 19, 2021
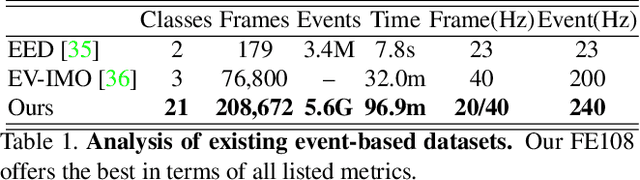
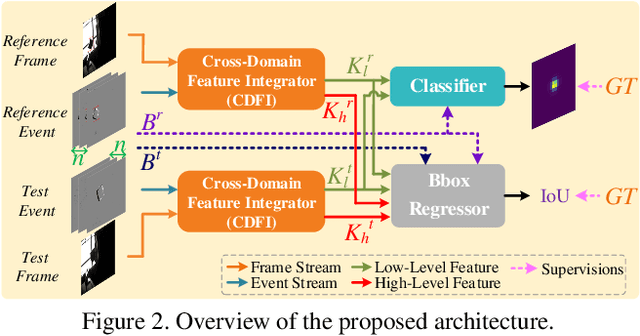
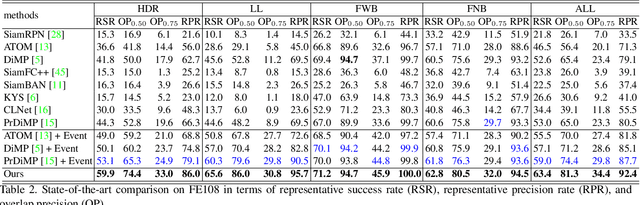
Inspired by the complementarity between conventional frame-based and bio-inspired event-based cameras, we propose a multi-modal based approach to fuse visual cues from the frame- and event-domain to enhance the single object tracking performance, especially in degraded conditions (e.g., scenes with high dynamic range, low light, and fast-motion objects). The proposed approach can effectively and adaptively combine meaningful information from both domains. Our approach's effectiveness is enforced by a novel designed cross-domain attention schemes, which can effectively enhance features based on self- and cross-domain attention schemes; The adaptiveness is guarded by a specially designed weighting scheme, which can adaptively balance the contribution of the two domains. To exploit event-based visual cues in single-object tracking, we construct a large-scale frame-event-based dataset, which we subsequently employ to train a novel frame-event fusion based model. Extensive experiments show that the proposed approach outperforms state-of-the-art frame-based tracking methods by at least 10.4% and 11.9% in terms of representative success rate and precision rate, respectively. Besides, the effectiveness of each key component of our approach is evidenced by our thorough ablation study.
Multi-domain Collaborative Feature Representation for Robust Visual Object Tracking
Aug 10, 2021
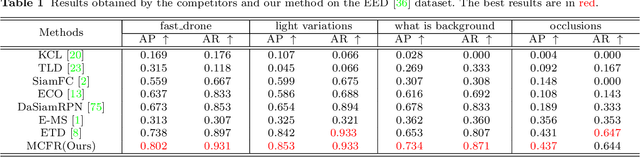
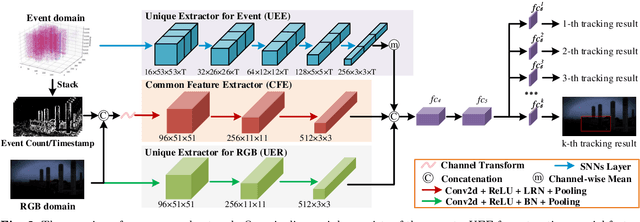

Jointly exploiting multiple different yet complementary domain information has been proven to be an effective way to perform robust object tracking. This paper focuses on effectively representing and utilizing complementary features from the frame domain and event domain for boosting object tracking performance in challenge scenarios. Specifically, we propose Common Features Extractor (CFE) to learn potential common representations from the RGB domain and event domain. For learning the unique features of the two domains, we utilize a Unique Extractor for Event (UEE) based on Spiking Neural Networks to extract edge cues in the event domain which may be missed in RGB in some challenging conditions, and a Unique Extractor for RGB (UER) based on Deep Convolutional Neural Networks to extract texture and semantic information in RGB domain. Extensive experiments on standard RGB benchmark and real event tracking dataset demonstrate the effectiveness of the proposed approach. We show our approach outperforms all compared state-of-the-art tracking algorithms and verify event-based data is a powerful cue for tracking in challenging scenes.
A Two-Stage Attentive Network for Single Image Super-Resolution
Apr 21, 2021



Recently, deep convolutional neural networks (CNNs) have been widely explored in single image super-resolution (SISR) and contribute remarkable progress. However, most of the existing CNNs-based SISR methods do not adequately explore contextual information in the feature extraction stage and pay little attention to the final high-resolution (HR) image reconstruction step, hence hindering the desired SR performance. To address the above two issues, in this paper, we propose a two-stage attentive network (TSAN) for accurate SISR in a coarse-to-fine manner. Specifically, we design a novel multi-context attentive block (MCAB) to make the network focus on more informative contextual features. Moreover, we present an essential refined attention block (RAB) which could explore useful cues in HR space for reconstructing fine-detailed HR image. Extensive evaluations on four benchmark datasets demonstrate the efficacy of our proposed TSAN in terms of quantitative metrics and visual effects. Code is available at https://github.com/Jee-King/TSAN.
DRFN: Deep Recurrent Fusion Network for Single-Image Super-Resolution with Large Factors
Aug 23, 2019

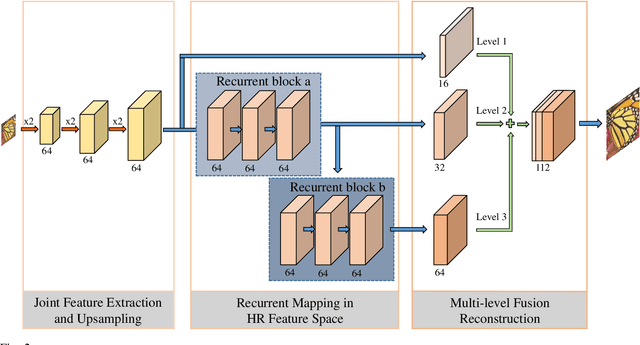

Recently, single-image super-resolution has made great progress owing to the development of deep convolutional neural networks (CNNs). The vast majority of CNN-based models use a pre-defined upsampling operator, such as bicubic interpolation, to upscale input low-resolution images to the desired size and learn non-linear mapping between the interpolated image and ground truth high-resolution (HR) image. However, interpolation processing can lead to visual artifacts as details are over-smoothed, particularly when the super-resolution factor is high. In this paper, we propose a Deep Recurrent Fusion Network (DRFN), which utilizes transposed convolution instead of bicubic interpolation for upsampling and integrates different-level features extracted from recurrent residual blocks to reconstruct the final HR images. We adopt a deep recurrence learning strategy and thus have a larger receptive field, which is conducive to reconstructing an image more accurately. Furthermore, we show that the multi-level fusion structure is suitable for dealing with image super-resolution problems. Extensive benchmark evaluations demonstrate that the proposed DRFN performs better than most current deep learning methods in terms of accuracy and visual effects, especially for large-scale images, while using fewer parameters.