 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Phrase Break of ESL Speech with Pre-trained Language Models and Large Language Models
Jun 08, 2023



This work introduces approaches to assessing phrase breaks in ESL learners' speech using pre-trained language models (PLMs) and large language models (LLMs). There are two tasks: overall assessment of phrase break for a speech clip and fine-grained assessment of every possible phrase break position. To leverage NLP models, speech input is first force-aligned with texts, and then pre-processed into a token sequence, including words and phrase break information. To utilize PLMs, we propose a pre-training and fine-tuning pipeline with the processed tokens. This process includes pre-training with a replaced break token detection module and fine-tuning with text classification and sequence labeling. To employ LLMs, we design prompts for ChatGPT. The experiments show that with the PLMs, the dependence on labeled training data has been greatly reduced, and the performance has improved. Meanwhile, we verify that ChatGPT, a renowned LLM, has potential for further advancement in this area.
Smart Word Suggestions for Writing Assistance
May 17, 2023



Enhancing word usage is a desired feature for writing assistance. To further advance research in this area, this paper introduces "Smart Word Suggestions" (SWS) task and benchmark. Unlike other works, SWS emphasizes end-to-end evaluation and presents a more realistic writing assistance scenario. This task involves identifying words or phrases that require improvement and providing substitution suggestions. The benchmark includes human-labeled data for testing, a large distantly supervised dataset for training, and the framework for evaluation. The test data includes 1,000 sentences written by English learners, accompanied by over 16,000 substitution suggestions annotated by 10 native speakers. The training dataset comprises over 3.7 million sentences and 12.7 million suggestions generated through rules. Our experiments with seven baselines demonstrate that SWS is a challenging task. Based on experimental analysis, we suggest potential directions for future research on SWS. The dataset and related codes is available at https://github.com/microsoft/SmartWordSuggestions.
Low-code LLM: Visual Programming over LLMs
Apr 20, 2023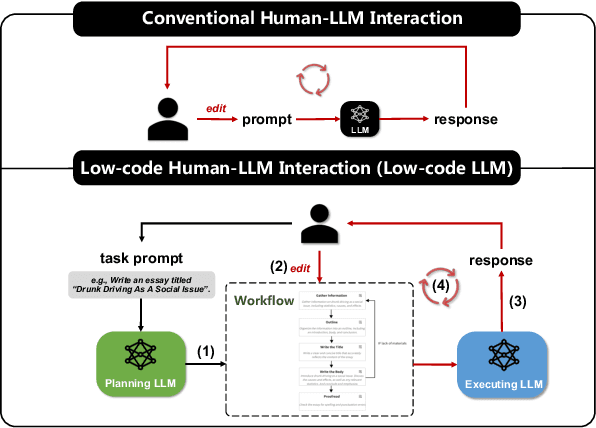

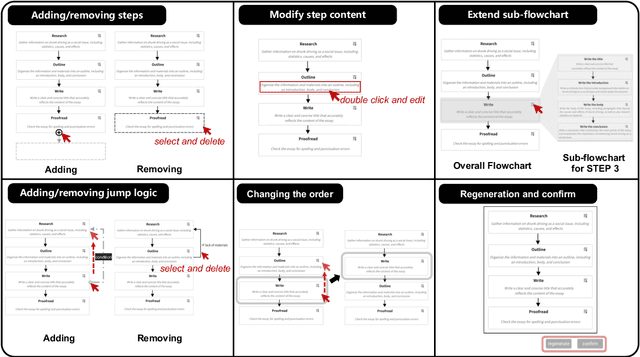

Effectively utilizing LLMs for complex tasks is challenging, often involving a time-consuming and uncontrollable prompt engineering process. This paper introduces a novel human-LLM interaction framework, Low-code LLM. It incorporates six types of simple low-code visual programming interactions, all supported by clicking, dragging, or text editing, to achieve more controllable and stable responses. Through visual interaction with a graphical user interface, users can incorporate their ideas into the workflow without writing trivial prompts. The proposed Low-code LLM framework consists of a Planning LLM that designs a structured planning workflow for complex tasks, which can be correspondingly edited and confirmed by users through low-code visual programming operations, and an Executing LLM that generates responses following the user-confirmed workflow. We highlight three advantages of the low-code LLM: controllable generation results, user-friendly human-LLM interaction, and broadly applicable scenarios. We demonstrate its benefits using four typical applications. By introducing this approach, we aim to bridge the gap between humans and LLMs, enabling more effective and efficient utilization of LLMs for complex tasks. Our system will be soon publicly available at LowCodeLLM.
An Approach to Mispronunciation Detection and Diagnosis with Acoustic, Phonetic and Linguistic (APL) Embeddings
Oct 14, 2021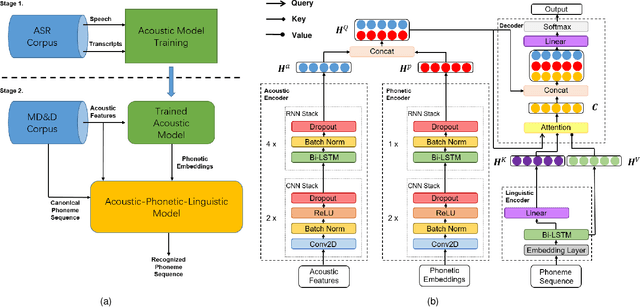
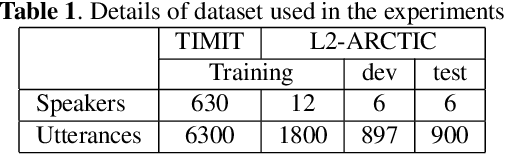
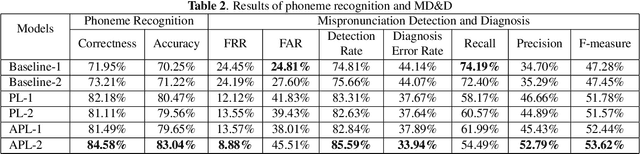
Many mispronunciation detection and diagnosis (MD&D) research approaches try to exploit both the acoustic and linguistic features as input. Yet the improvement of the performance is limited, partially due to the shortage of large amount annotated training data at the phoneme level. Phonetic embeddings, extracted from ASR models trained with huge amount of word level annotations, can serve as a good representation of the content of input speech, in a noise-robust and speaker-independent manner. These embeddings, when used as implicit phonetic supplementary information, can alleviate the data shortage of explicit phoneme annotations. We propose to utilize Acoustic, Phonetic and Linguistic (APL) embedding features jointly for building a more powerful MD\&D system. Experimental results obtained on the L2-ARCTIC database show the proposed approach outperforms the baseline by 9.93%, 10.13% and 6.17% on the detection accuracy, diagnosis error rate and the F-measure, respectively.
Improving pronunciation assessment via ordinal regression with anchored reference samples
Oct 26, 2020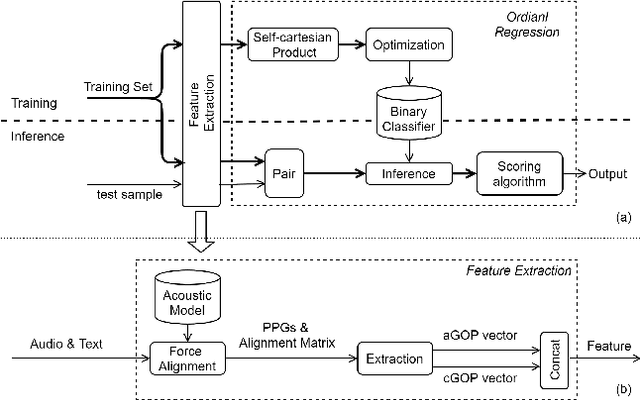
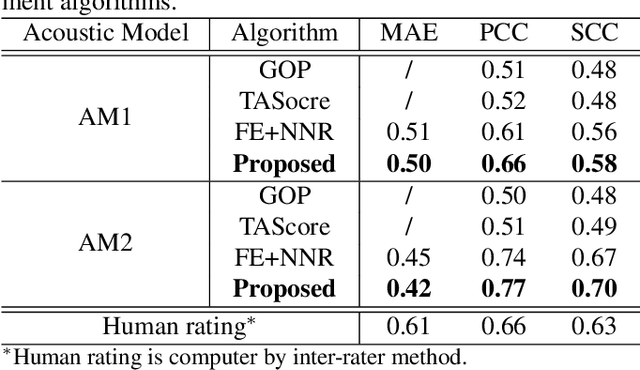
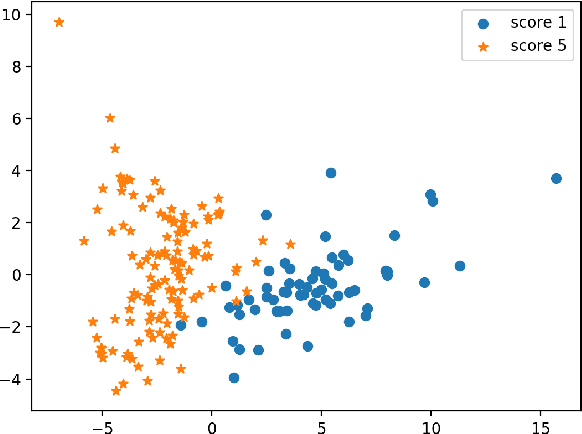
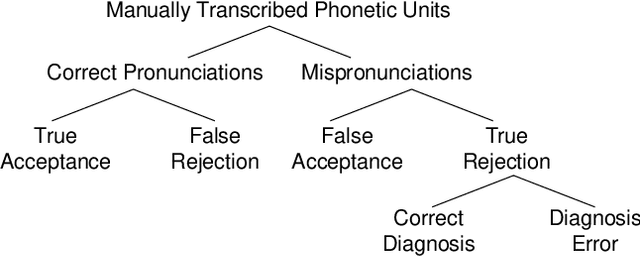
Sentence level pronunciation assessment is important for Computer Assisted Language Learning (CALL). Traditional speech pronunciation assessment, based on the Goodness of Pronunciation (GOP) algorithm, has some weakness in assessing a speech utterance: 1) Phoneme GOP scores cannot be easily translated into a sentence score with a simple average for effective assessment; 2) The rank ordering information has not been well exploited in GOP scoring for delivering a robust assessment and correlate well with a human rater's evaluations. In this paper, we propose two new statistical features, average GOP (aGOP) and confusion GOP (cGOP) and use them to train a binary classifier in Ordinal Regression with Anchored Reference Samples (ORARS). When the proposed approach is tested on Microsoft mTutor ESL Dataset, a relative improvement of Pearson correlation coefficient of 26.9% is obtained over the conventional GOP-based one. The performance is at a human-parity level or better than human raters.