 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrdinal Regression via Binary Preference vs Simple Regression: Statistical and Experimental Perspectives
Jul 06, 2022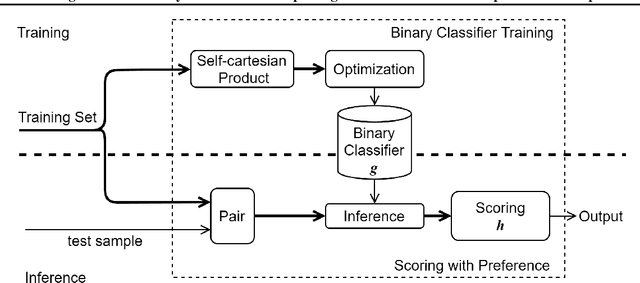

Ordinal regression with anchored reference samples (ORARS) has been proposed for predicting the subjective Mean Opinion Score (MOS) of input stimuli automatically. The ORARS addresses the MOS prediction problem by pairing a test sample with each of the pre-scored anchored reference samples. A trained binary classifier is then used to predict which sample, test or anchor, is better statistically. Posteriors of the binary preference decision are then used to predict the MOS of the test sample. In this paper, rigorous framework, analysis, and experiments to demonstrate that ORARS are advantageous over simple regressions are presented. The contributions of this work are: 1) Show that traditional regression can be reformulated into multiple preference tests to yield a better performance, which is confirmed with simulations experimentally; 2) Generalize ORARS to other regression problems and verify its effectiveness; 3) Provide some prerequisite conditions which can insure proper application of ORARS.
Unsupervised Cross-Lingual Speech Emotion Recognition Using DomainAdversarial Neural Network
Dec 21, 2020



By using deep learning approaches, Speech Emotion Recog-nition (SER) on a single domain has achieved many excellentresults. However, cross-domain SER is still a challenging taskdue to the distribution shift between source and target domains.In this work, we propose a Domain Adversarial Neural Net-work (DANN) based approach to mitigate this distribution shiftproblem for cross-lingual SER. Specifically, we add a languageclassifier and gradient reversal layer after the feature extractor toforce the learned representation both language-independent andemotion-meaningful. Our method is unsupervised, i. e., labelson target language are not required, which makes it easier to ap-ply our method to other languages. Experimental results showthe proposed method provides an average absolute improve-ment of 3.91% over the baseline system for arousal and valenceclassification task. Furthermore, we find that batch normaliza-tion is beneficial to the performance gain of DANN. Thereforewe also explore the effect of different ways of data combinationfor batch normalization.
Improving pronunciation assessment via ordinal regression with anchored reference samples
Oct 26, 2020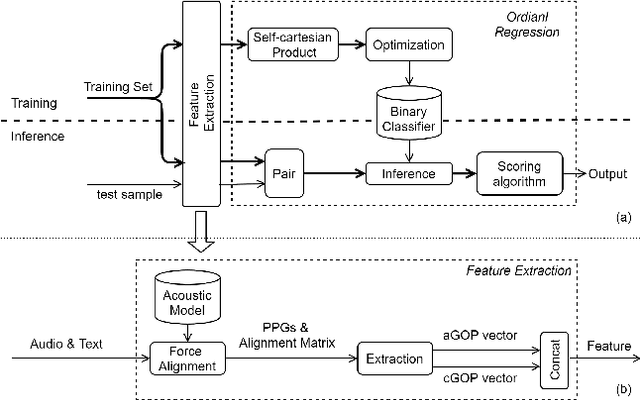
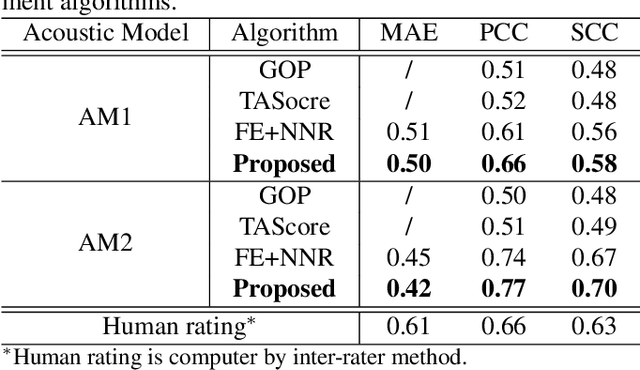
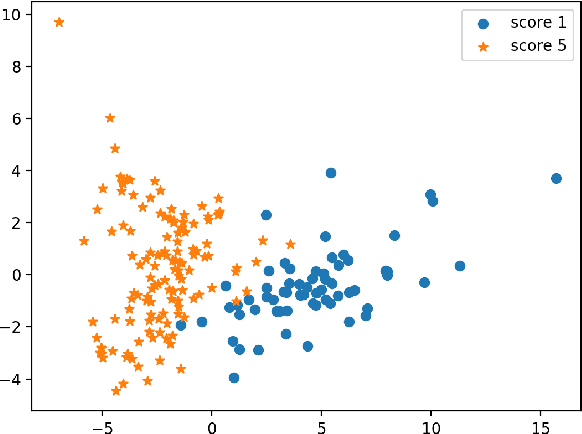
Sentence level pronunciation assessment is important for Computer Assisted Language Learning (CALL). Traditional speech pronunciation assessment, based on the Goodness of Pronunciation (GOP) algorithm, has some weakness in assessing a speech utterance: 1) Phoneme GOP scores cannot be easily translated into a sentence score with a simple average for effective assessment; 2) The rank ordering information has not been well exploited in GOP scoring for delivering a robust assessment and correlate well with a human rater's evaluations. In this paper, we propose two new statistical features, average GOP (aGOP) and confusion GOP (cGOP) and use them to train a binary classifier in Ordinal Regression with Anchored Reference Samples (ORARS). When the proposed approach is tested on Microsoft mTutor ESL Dataset, a relative improvement of Pearson correlation coefficient of 26.9% is obtained over the conventional GOP-based one. The performance is at a human-parity level or better than human raters.