 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Driven Automated Tool for Abdominal CT Body Composition Analysis in Gastrointestinal Cancer Management
Mar 10, 2025



The incidence of gastrointestinal cancers remains significantly high, particularly in China, emphasizing the importance of accurate prognostic assessments and effective treatment strategies. Research shows a strong correlation between abdominal muscle and fat tissue composition and patient outcomes. However, existing manual methods for analyzing abdominal tissue composition are time-consuming and costly, limiting clinical research scalability. To address these challenges, we developed an AI-driven tool for automated analysis of abdominal CT scans to effectively identify and segment muscle, subcutaneous fat, and visceral fat. Our tool integrates a multi-view localization model and a high-precision 2D nnUNet-based segmentation model, demonstrating a localization accuracy of 90% and a Dice Score Coefficient of 0.967 for segmentation. Furthermore, it features an interactive interface that allows clinicians to refine the segmentation results, ensuring high-quality outcomes effectively. Our tool offers a standardized method for effectively extracting critical abdominal tissues, potentially enhancing the management and treatment for gastrointestinal cancers. The code is available at https://github.com/NanXinyu/AI-Tool4Abdominal-Seg.git}{https://github.com/NanXinyu/AI-Tool4Abdominal-Seg.git.
Model-Driven Deep Learning for Distributed Detection with Binary Quantization
Mar 30, 2024Within the realm of rapidly advancing wireless sensor networks (WSNs), distributed detection assumes a significant role in various practical applications. However, critical challenge lies in maintaining robust detection performance while operating within the constraints of limited bandwidth and energy resources. This paper introduces a novel approach that combines model-driven deep learning (DL) with binary quantization to strike a balance between communication overhead and detection performance in WSNs. We begin by establishing the lower bound of detection error probability for distributed detection using the maximum a posteriori (MAP) criterion. Furthermore, we prove the global optimality of employing identical local quantizers across sensors, thereby maximizing the corresponding Chernoff information. Subsequently, the paper derives the minimum MAP detection error probability (MAPDEP) by inplementing identical binary probabilistic quantizers across the sensors. Moreover, the paper establishes the equivalence between utilizing all quantized data and their average as input to the detector at the fusion center (FC). In particular, we derive the Kullback-Leibler (KL) divergence, which measures the difference between the true posterior probability and output of the proposed detector. Leveraging the MAPDEP and KL divergence as loss functions, the paper proposes model-driven DL method to separately train the probability controller module in the quantizer and the detector module at the FC. Numerical results validate the convergence and effectiveness of the proposed method, which achieves near-optimal performance with reduced complexity for Gaussian hypothesis testing.
Self-Interference Cancellation for Full-Duplex Massive MIMO OFDM with Single RF Chain
Aug 10, 2023In this paper, the digital self-interference (SI) cancellation in a single radio frequency (RF) chain massive multi-input multi-output (MIMO) full-duplex (FD) orthogonal frequency division multiplexing (OFDM) system with phase noise is studied. To compensate the phase noise, which introduces SI channel estimation error and thus degrades the SI cancellation performance, a weighted linear SI channel estimator is derived to minimize the residual SI power in each OFDM symbol. The digital SI cancellation ability of the proposed method, which is defined as the ratio of the SI power before and after the SI cancellation, is analyzed. Simulation results show that the proposed optimal linear SI channel estimator significantly outperforms the conventional least square (LS) estimator in terms of the SI cancellation ability for the cases with strong SI and low oscillator quality.
Universal Performance Bounds for Joint Self-Interference Cancellation and Data Detection in Full-Duplex Communications
Aug 10, 2023This paper studies the joint digital self-interference (SI) cancellation and data detection in an orthogonal-frequency-division-multiplexing (OFDM) full-duplex (FD) system, considering the effect of phase noise introduced by the oscillators at both the local transmitter and receiver. In particular, an universal iterative two-stage joint SI cancellation and data detection framework is considered and its performance bound independent of any specific estimation and detection methods is derived. First, the channel and phase noise estimation mean square error (MSE) lower bounds in each iteration are derived by analyzing the Fisher information of the received signal. Then, by substituting the derived MSE lower bound into the SINR expression, which is related to the channel and phase noise estimation MSE, the SINR upper bound in each iteration is computed. Finally, by exploiting the SINR upper bound and the transition information of the detection errors between two adjacent iterations, the universal bit error rate (BER) lower bound for data detection is derived.
A Joint Model and Data Driven Method for Distributed Estimation
Mar 30, 2023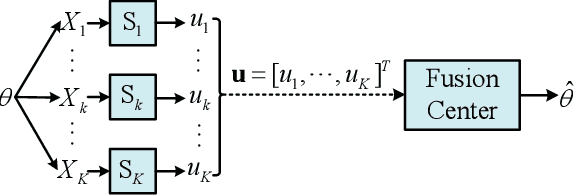
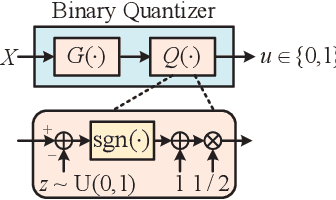
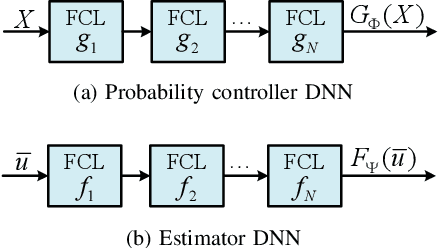
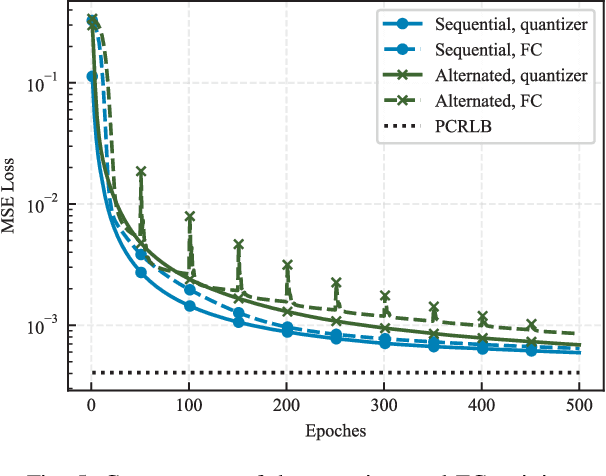
This paper considers the problem of distributed estimation in wireless sensor networks (WSN), which is anticipated to support a wide range of applications such as the environmental monitoring, weather forecasting, and location estimation. To this end, we propose a joint model and data driven distributed estimation method by designing the optimal quantizers and fusion center (FC) based on the Bayesian and minimum mean square error (MMSE) criterions. First, universal mean square error (MSE) lower bound for the quantization-based distributed estimation is derived and adopted as the design metric for the quantizers. Then, the optimality of the mean-fusion operation for the FC with MMSE criterion is proved. Next, by exploiting different levels of the statistic information of the desired parameter and observation noise, a joint model and data driven method is proposed to train parts of the quantizer and FC modules as deep neural networks (DNNs), and two loss functions derived from the MMSE criterion are adopted for the sequential training scheme. Furthermore, we extend the above results to the case with multi-bit quantizers, considering both the parallel and one-hot quantization schemes. Finally, simulation results reveal that the proposed method outperforms the state-of-the-art schemes in typical scenarios.
R2F: A Remote Retraining Framework for AIoT Processors with Computing Errors
Jul 07, 2021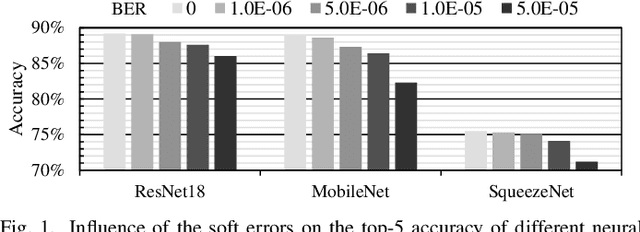
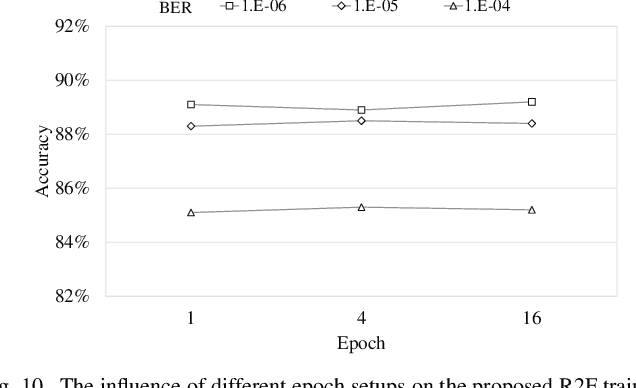
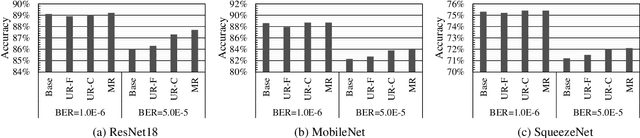
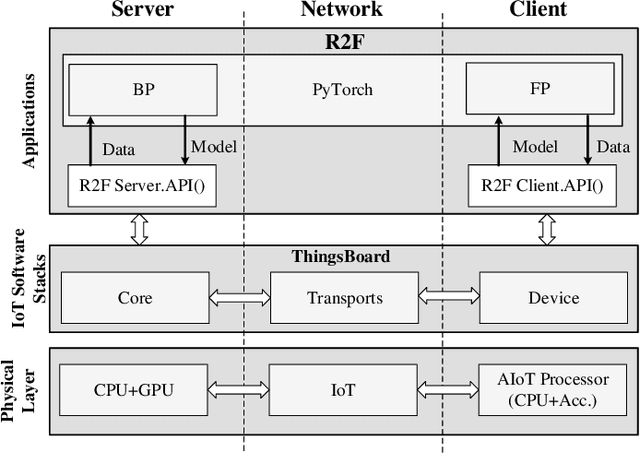
AIoT processors fabricated with newer technology nodes suffer rising soft errors due to the shrinking transistor sizes and lower power supply. Soft errors on the AIoT processors particularly the deep learning accelerators (DLAs) with massive computing may cause substantial computing errors. These computing errors are difficult to be captured by the conventional training on general purposed processors like CPUs and GPUs in a server. Applying the offline trained neural network models to the edge accelerators with errors directly may lead to considerable prediction accuracy loss. To address the problem, we propose a remote retraining framework (R2F) for remote AIoT processors with computing errors. It takes the remote AIoT processor with soft errors in the training loop such that the on-site computing errors can be learned with the application data on the server and the retrained models can be resilient to the soft errors. Meanwhile, we propose an optimized partial TMR strategy to enhance the retraining. According to our experiments, R2F enables elastic design trade-offs between the model accuracy and the performance penalty. The top-5 model accuracy can be improved by 1.93%-13.73% with 0%-200% performance penalty at high fault error rate. In addition, we notice that the retraining requires massive data transmission and even dominates the training time, and propose a sparse increment compression approach for the data transmission optimization, which reduces the retraining time by 38%-88% on average with negligible accuracy loss over a straightforward remote retraining.