 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2F: A Remote Retraining Framework for AIoT Processors with Computing Errors
Jul 07, 2021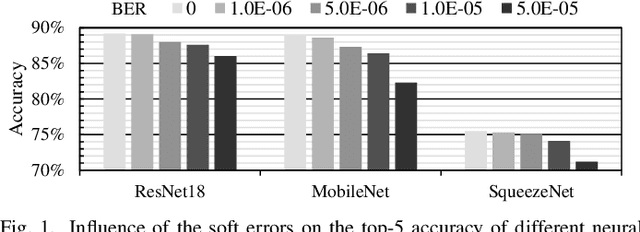
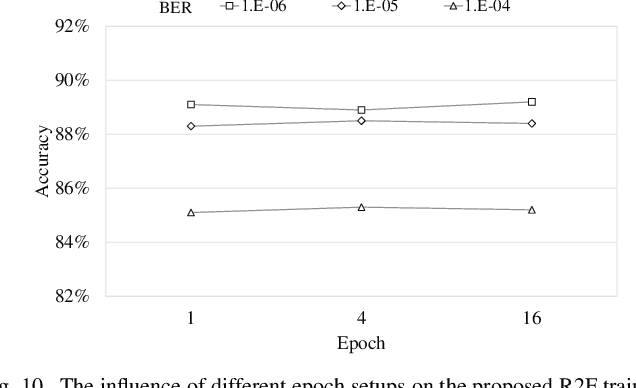
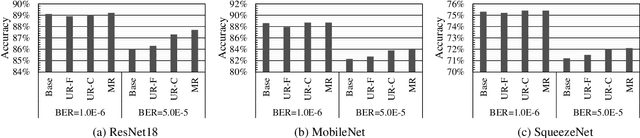
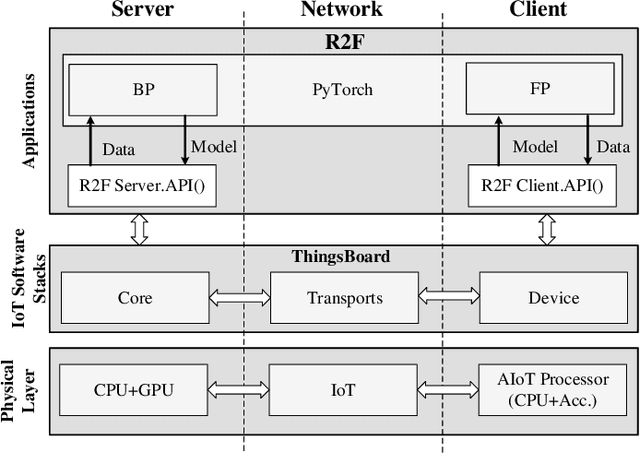
AIoT processors fabricated with newer technology nodes suffer rising soft errors due to the shrinking transistor sizes and lower power supply. Soft errors on the AIoT processors particularly the deep learning accelerators (DLAs) with massive computing may cause substantial computing errors. These computing errors are difficult to be captured by the conventional training on general purposed processors like CPUs and GPUs in a server. Applying the offline trained neural network models to the edge accelerators with errors directly may lead to considerable prediction accuracy loss. To address the problem, we propose a remote retraining framework (R2F) for remote AIoT processors with computing errors. It takes the remote AIoT processor with soft errors in the training loop such that the on-site computing errors can be learned with the application data on the server and the retrained models can be resilient to the soft errors. Meanwhile, we propose an optimized partial TMR strategy to enhance the retraining. According to our experiments, R2F enables elastic design trade-offs between the model accuracy and the performance penalty. The top-5 model accuracy can be improved by 1.93%-13.73% with 0%-200% performance penalty at high fault error rate. In addition, we notice that the retraining requires massive data transmission and even dominates the training time, and propose a sparse increment compression approach for the data transmission optimization, which reduces the retraining time by 38%-88% on average with negligible accuracy loss over a straightforward remote retraining.