 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex Hull-based Algebraic Constraint for Visual Quadric SLAM
Mar 03, 2025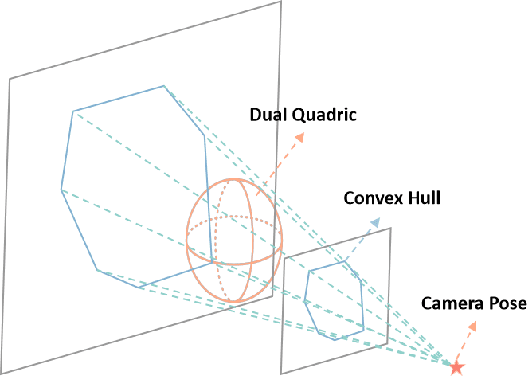

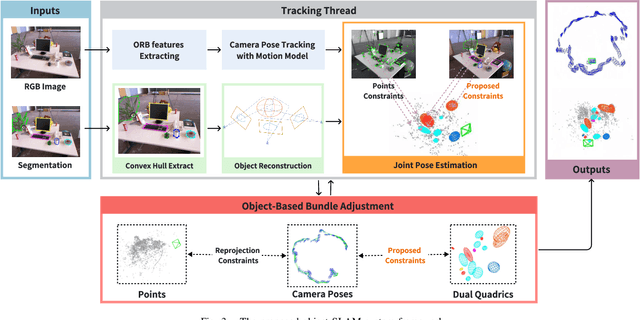

Using Quadrics as the object representation has the benefits of both generality and closed-form projection derivation between image and world spaces. Although numerous constraints have been proposed for dual quadric reconstruction, we found that many of them are imprecise and provide minimal improvements to localization.After scrutinizing the existing constraints, we introduce a concise yet more precise convex hull-based algebraic constraint for object landmarks, which is applied to object reconstruction, frontend pose estimation, and backend bundle adjustment.This constraint is designed to fully leverage precise semantic segmentation, effectively mitigating mismatches between complex-shaped object contours and dual quadrics.Experiments on public datasets demonstrate that our approach is applicable to both monocular and RGB-D SLAM and achieves improved object mapping and localization than existing quadric SLAM methods. The implementation of our method is available at https://github.com/tiev-tongji/convexhull-based-algebraic-constraint.
LOG-LIO2: A LiDAR-Inertial Odometry with Efficient Uncertainty Analysis
May 02, 2024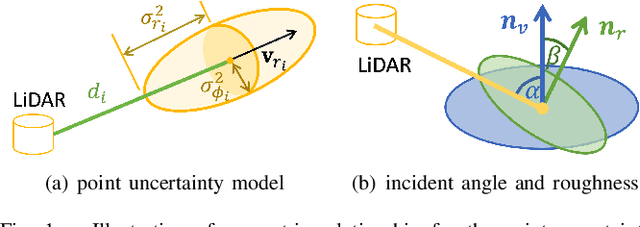
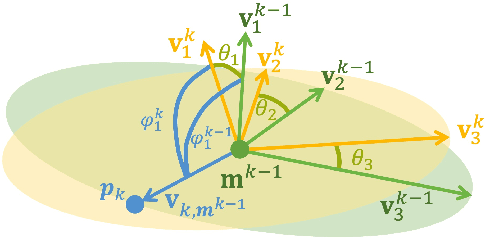
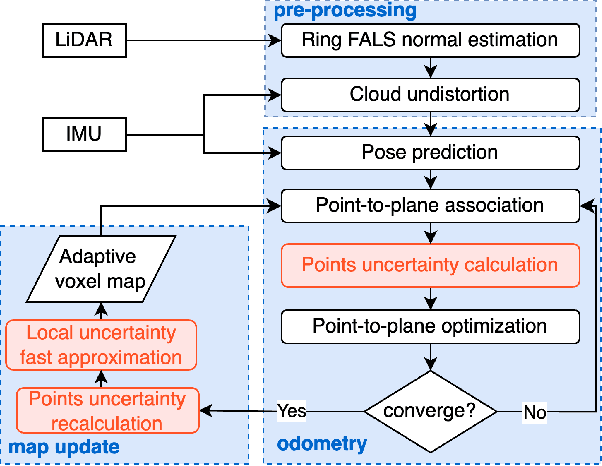
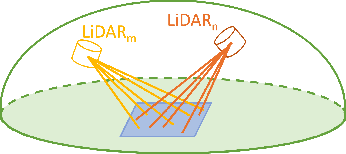
Uncertainty in LiDAR measurements, stemming from factors such as range sensing, is crucial for LIO (LiDAR-Inertial Odometry) systems as it affects the accurate weighting in the loss function. While recent LIO systems address uncertainty related to range sensing, the impact of incident angle on uncertainty is often overlooked by the community. Moreover, the existing uncertainty propagation methods suffer from computational inefficiency. This paper proposes a comprehensive point uncertainty model that accounts for both the uncertainties from LiDAR measurements and surface characteristics, along with an efficient local uncertainty analytical method for LiDAR-based state estimation problem. We employ a projection operator that separates the uncertainty into the ray direction and its orthogonal plane. Then, we derive incremental Jacobian matrices of eigenvalues and eigenvectors w.r.t. points, which enables a fast approximation of uncertainty propagation. This approach eliminates the requirement for redundant traversal of points, significantly reducing the time complexity of uncertainty propagation from $\mathcal{O} (n)$ to $\mathcal{O} (1)$ when a new point is added. Simulations and experiments on public datasets are conducted to validate the accuracy and efficiency of our formulations. The proposed methods have been integrated into a LIO system, which is available at https://github.com/tiev-tongji/LOG-LIO2.
N$^{3}$-Mapping: Normal Guided Neural Non-Projective Signed Distance Fields for Large-scale 3D Mapping
Jan 07, 2024



Accurate and dense mapping in large-scale environments is essential for various robot applications. Recently, implicit neural signed distance fields (SDFs) have shown promising advances in this task. However, most existing approaches employ projective distances from range data as SDF supervision, introducing approximation errors and thus degrading the mapping quality. To address this problem, we introduce N3-Mapping, an implicit neural mapping system featuring normal-guided neural non-projective signed distance fields. Specifically, we directly sample points along the surface normal, instead of the ray, to obtain more accurate non-projective distance values from range data. Then these distance values are used as supervision to train the implicit map. For large-scale mapping, we apply a voxel-oriented sliding window mechanism to alleviate the forgetting issue with a bounded memory footprint. Besides, considering the uneven distribution of measured point clouds, a hierarchical sampling strategy is designed to improve training efficiency. Experiments demonstrate that our method effectively mitigates SDF approximation errors and achieves state-of-the-art mapping quality compared to existing approaches.
Scale Estimation with Dual Quadrics for Monocular Object SLAM
Feb 10, 2022


The scale ambiguity problem is inherently unsolvable to monocular SLAM without the metric baseline between moving cameras. In this paper, we present a novel scale estimation approach based on an object-level SLAM system. To obtain the absolute scale of the reconstructed map, we derive a nonlinear optimization method to make the scaled dimensions of objects conforming to the distribution of their sizes in the physical world, without relying on any prior information of gravity direction. We adopt the dual quadric to represent objects for its ability to fit objects compactly and accurately. In the proposed monocular object-level SLAM system, dual quadrics are fastly initialized based on constraints of 2-D detections and fitted oriented bounding box and are further optimized to provide reliable dimensions for scale estimation.
Unsupervised Joint Learning of Depth, Optical Flow, Ego-motion from Video
May 30, 2021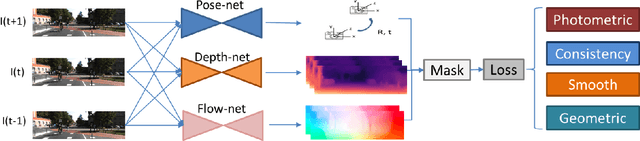
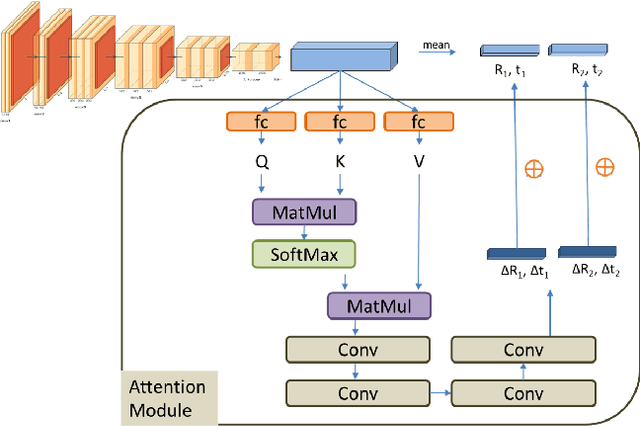


Estimating geometric elements such as depth, camera motion, and optical flow from images is an important part of the robot's visual perception. We use a joint self-supervised method to estimate the three geometric elements. Depth network, optical flow network and camera motion network are independent of each other but are jointly optimized during training phase. Compared with independent training, joint training can make full use of the geometric relationship between geometric elements and provide dynamic and static information of the scene. In this paper, we improve the joint self-supervision method from three aspects: network structure, dynamic object segmentation, and geometric constraints. In terms of network structure, we apply the attention mechanism to the camera motion network, which helps to take advantage of the similarity of camera movement between frames. And according to attention mechanism in Transformer, we propose a plug-and-play convolutional attention module. In terms of dynamic object, according to the different influences of dynamic objects in the optical flow self-supervised framework and the depth-pose self-supervised framework, we propose a threshold algorithm to detect dynamic regions, and mask that in the loss function respectively. In terms of geometric constraints, we use traditional methods to estimate the fundamental matrix from the corresponding points to constrain the camera motion network. We demonstrate the effectiveness of our method on the KITTI dataset. Compared with other joint self-supervised methods, our method achieves state-of-the-art performance in the estimation of pose and optical flow, and the depth estimation has also achieved competitive results. Code will be available https://github.com/jianfenglihg/Unsupervised_geometry.