 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Joint Learning of Depth, Optical Flow, Ego-motion from Video
Paper and Code
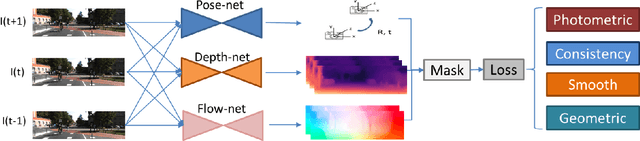
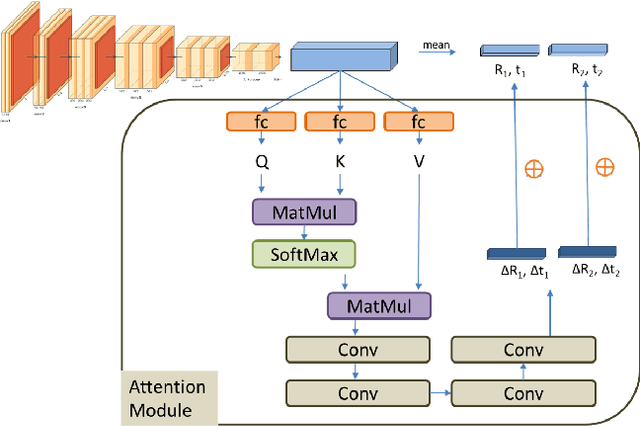


Estimating geometric elements such as depth, camera motion, and optical flow from images is an important part of the robot's visual perception. We use a joint self-supervised method to estimate the three geometric elements. Depth network, optical flow network and camera motion network are independent of each other but are jointly optimized during training phase. Compared with independent training, joint training can make full use of the geometric relationship between geometric elements and provide dynamic and static information of the scene. In this paper, we improve the joint self-supervision method from three aspects: network structure, dynamic object segmentation, and geometric constraints. In terms of network structure, we apply the attention mechanism to the camera motion network, which helps to take advantage of the similarity of camera movement between frames. And according to attention mechanism in Transformer, we propose a plug-and-play convolutional attention module. In terms of dynamic object, according to the different influences of dynamic objects in the optical flow self-supervised framework and the depth-pose self-supervised framework, we propose a threshold algorithm to detect dynamic regions, and mask that in the loss function respectively. In terms of geometric constraints, we use traditional methods to estimate the fundamental matrix from the corresponding points to constrain the camera motion network. We demonstrate the effectiveness of our method on the KITTI dataset. Compared with other joint self-supervised methods, our method achieves state-of-the-art performance in the estimation of pose and optical flow, and the depth estimation has also achieved competitive results. Code will be available https://github.com/jianfenglihg/Unsupervised_geometry.