 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCL: Continual Contrastive Learning for LiDAR Place Recognition
Mar 24, 2023



Place recognition is an essential and challenging task in loop closing and global localization for robotics and autonomous driving applications. Benefiting from the recent advances in deep learning techniques, the performance of LiDAR place recognition (LPR) has been greatly improved. However, current deep learning-based methods suffer from two major problems: poor generalization ability and catastrophic forgetting. In this paper, we propose a continual contrastive learning method, named CCL, to tackle the catastrophic forgetting problem and generally improve the robustness of LPR approaches. Our CCL constructs a contrastive feature pool and utilizes contrastive loss to train more transferable representations of places. When transferred into new environments, our CCL continuously reviews the contrastive memory bank and applies a distribution-based knowledge distillation to maintain the retrieval ability of the past data while continually learning to recognize new places from the new data. We thoroughly evaluate our approach on Oxford, MulRan, and PNV datasets using three different LPR methods. The experimental results show that our CCL consistently improves the performance of different methods in different environments outperforming the state-of-the-art continual learning method. The implementation of our method has been released at https://github.com/cloudcjf/CCL.
Patch-NetVLAD+: Learned patch descriptor and weighted matching strategy for place recognition
Feb 11, 2022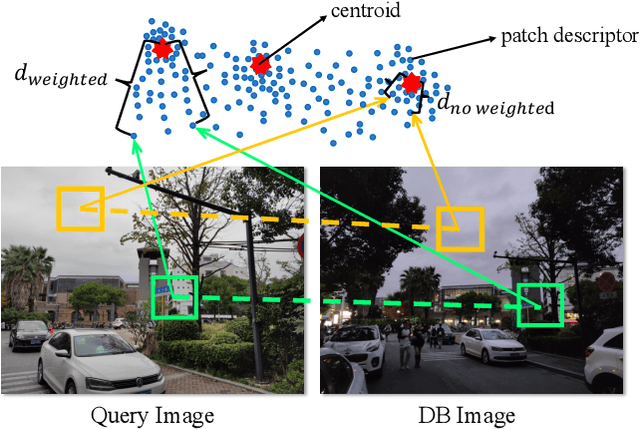
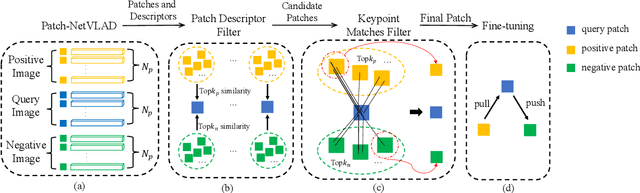
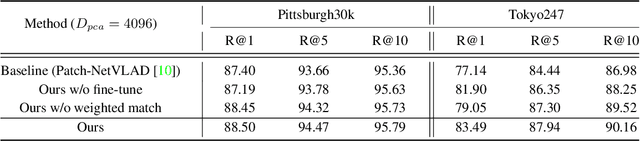
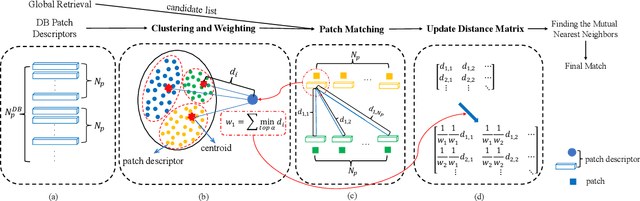
Visual Place Recognition (VPR) in areas with similar scenes such as urban or indoor scenarios is a major challenge. Existing VPR methods using global descriptors have difficulty capturing local specific regions (LSR) in the scene and are therefore prone to localization confusion in such scenarios. As a result, finding the LSR that are critical for location recognition becomes key. To address this challenge, we introduced Patch-NetVLAD+, which was inspired by patch-based VPR researches. Our method proposed a fine-tuning strategy with triplet loss to make NetVLAD suitable for extracting patch-level descriptors. Moreover, unlike existing methods that treat all patches in an image equally, our method extracts patches of LSR, which present less frequently throughout the dataset, and makes them play an important role in VPR by assigning proper weights to them. Experiments on Pittsburgh30k and Tokyo247 datasets show that our approach achieved up to 6.35\% performance improvement than existing patch-based methods.
DSC: Deep Scan Context Descriptor for Large-Scale Place Recognition
Nov 27, 2021
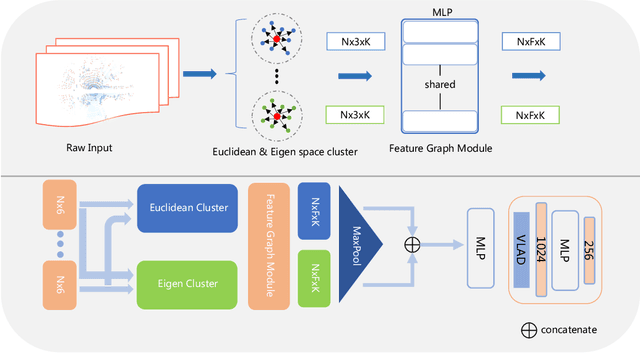
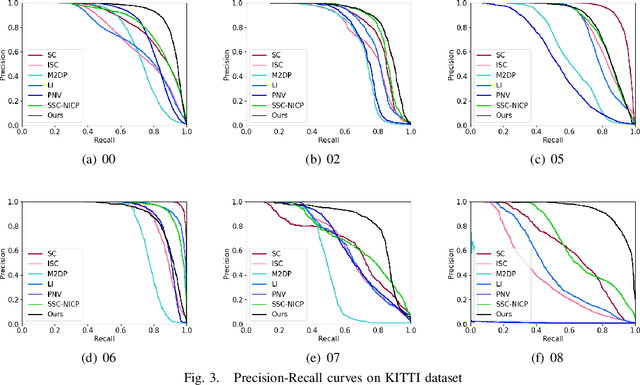
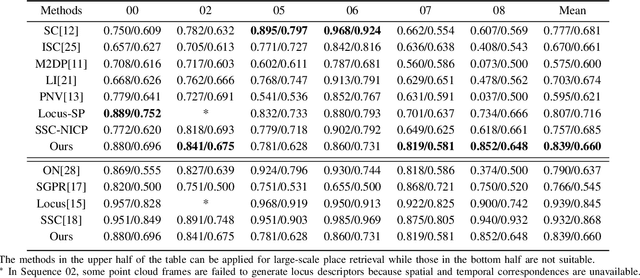
LiDAR-based place recognition is an essential and challenging task both in loop closure detection and global relocalization. We propose Deep Scan Context (DSC), a general and discriminative global descriptor that captures the relationship among segments of a point cloud. Unlike previous methods that utilize either semantics or a sequence of adjacent point clouds for better place recognition, we only use raw point clouds to get competitive results. Concretely, we first segment the point cloud egocentrically to acquire centroids and eigenvalues of the segments. Then, we introduce a graph neural network to aggregate these features into an embedding representation. Extensive experiments conducted on the KITTI dataset show that DSC is robust to scene variants and outperforms existing methods.