 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrban Architect: Steerable 3D Urban Scene Generation with Layout Prior
Paper and Code

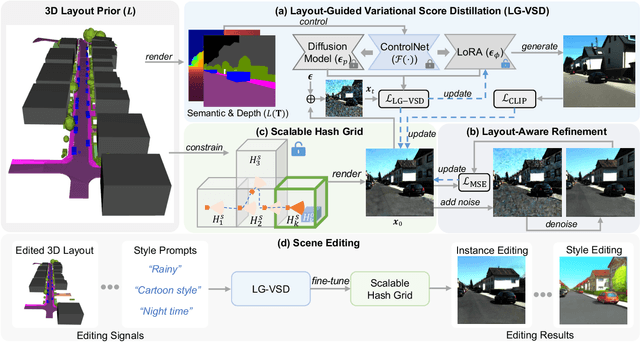
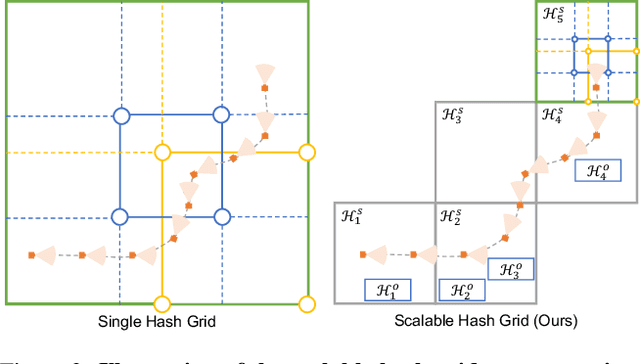

Text-to-3D generation has achieved remarkable success via large-scale text-to-image diffusion models. Nevertheless, there is no paradigm for scaling up the methodology to urban scale. Urban scenes, characterized by numerous elements, intricate arrangement relationships, and vast scale, present a formidable barrier to the interpretability of ambiguous textual descriptions for effective model optimization. In this work, we surmount the limitations by introducing a compositional 3D layout representation into text-to-3D paradigm, serving as an additional prior. It comprises a set of semantic primitives with simple geometric structures and explicit arrangement relationships, complementing textual descriptions and enabling steerable generation. Upon this, we propose two modifications -- (1) We introduce Layout-Guided Variational Score Distillation to address model optimization inadequacies. It conditions the score distillation sampling process with geometric and semantic constraints of 3D layouts. (2) To handle the unbounded nature of urban scenes, we represent 3D scene with a Scalable Hash Grid structure, incrementally adapting to the growing scale of urban scenes. Extensive experiments substantiate the capability of our framework to scale text-to-3D generation to large-scale urban scenes that cover over 1000m driving distance for the first time. We also present various scene editing demonstrations, showing the powers of steerable urban scene generation. Website: https://urbanarchitect.github.io.