 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHGL: Hierarchical Geometry Learning for Test-time Adaptation in 3D Point Cloud Segmentation
Jul 17, 2024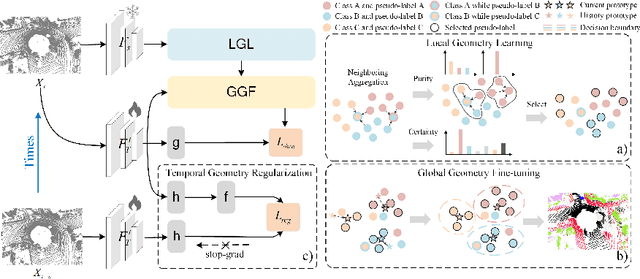
3D point cloud segmentation has received significant interest for its growing applications. However, the generalization ability of models suffers in dynamic scenarios due to the distribution shift between test and training data. To promote robustness and adaptability across diverse scenarios, test-time adaptation (TTA) has recently been introduced. Nevertheless, most existing TTA methods are developed for images, and limited approaches applicable to point clouds ignore the inherent hierarchical geometric structures in point cloud streams, i.e., local (point-level), global (object-level), and temporal (frame-level) structures. In this paper, we delve into TTA in 3D point cloud segmentation and propose a novel Hierarchical Geometry Learning (HGL) framework. HGL comprises three complementary modules from local, global to temporal learning in a bottom-up manner.Technically, we first construct a local geometry learning module for pseudo-label generation. Next, we build prototypes from the global geometry perspective for pseudo-label fine-tuning. Furthermore, we introduce a temporal consistency regularization module to mitigate negative transfer. Extensive experiments on four datasets demonstrate the effectiveness and superiority of our HGL. Remarkably, on the SynLiDAR to SemanticKITTI task, HGL achieves an overall mIoU of 46.91\%, improving GIPSO by 3.0\% and significantly reducing the required adaptation time by 80\%. The code is available at https://github.com/tpzou/HGL.
GLC++: Source-Free Universal Domain Adaptation through Global-Local Clustering and Contrastive Affinity Learning
Mar 21, 2024



Deep neural networks often exhibit sub-optimal performance under covariate and category shifts. Source-Free Domain Adaptation (SFDA) presents a promising solution to this dilemma, yet most SFDA approaches are restricted to closed-set scenarios. In this paper, we explore Source-Free Universal Domain Adaptation (SF-UniDA) aiming to accurately classify "known" data belonging to common categories and segregate them from target-private "unknown" data. We propose a novel Global and Local Clustering (GLC) technique, which comprises an adaptive one-vs-all global clustering algorithm to discern between target classes, complemented by a local k-NN clustering strategy to mitigate negative transfer. Despite the effectiveness, the inherent closed-set source architecture leads to uniform treatment of "unknown" data, impeding the identification of distinct "unknown" categories. To address this, we evolve GLC to GLC++, integrating a contrastive affinity learning strategy. We examine the superiority of GLC and GLC++ across multiple benchmarks and category shift scenarios. Remarkably, in the most challenging open-partial-set scenarios, GLC and GLC++ surpass GATE by 16.7% and 18.6% in H-score on VisDA, respectively. GLC++ enhances the novel category clustering accuracy of GLC by 4.3% in open-set scenarios on Office-Home. Furthermore, the introduced contrastive learning strategy not only enhances GLC but also significantly facilitates existing methodologies.
MAP: MAsk-Pruning for Source-Free Model Intellectual Property Protection
Mar 07, 2024Deep learning has achieved remarkable progress in various applications, heightening the importance of safeguarding the intellectual property (IP) of well-trained models. It entails not only authorizing usage but also ensuring the deployment of models in authorized data domains, i.e., making models exclusive to certain target domains. Previous methods necessitate concurrent access to source training data and target unauthorized data when performing IP protection, making them risky and inefficient for decentralized private data. In this paper, we target a practical setting where only a well-trained source model is available and investigate how we can realize IP protection. To achieve this, we propose a novel MAsk Pruning (MAP) framework. MAP stems from an intuitive hypothesis, i.e., there are target-related parameters in a well-trained model, locating and pruning them is the key to IP protection. Technically, MAP freezes the source model and learns a target-specific binary mask to prevent unauthorized data usage while minimizing performance degradation on authorized data. Moreover, we introduce a new metric aimed at achieving a better balance between source and target performance degradation. To verify the effectiveness and versatility, we have evaluated MAP in a variety of scenarios, including vanilla source-available, practical source-free, and challenging data-free. Extensive experiments indicate that MAP yields new state-of-the-art performance.
LEAD: Learning Decomposition for Source-free Universal Domain Adaptation
Mar 06, 2024
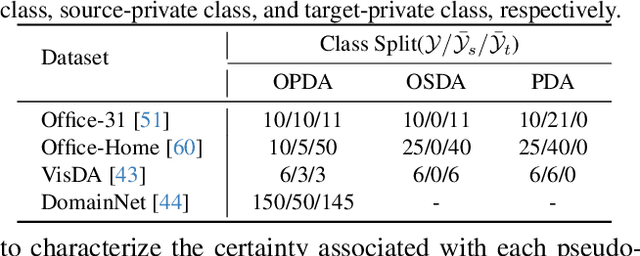
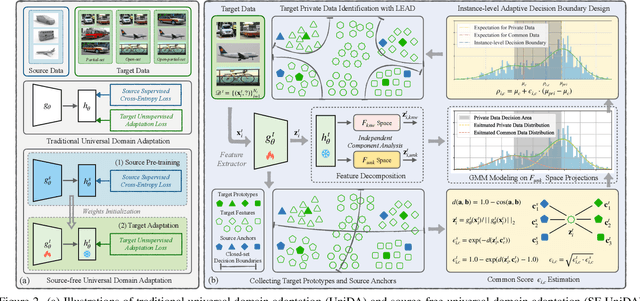
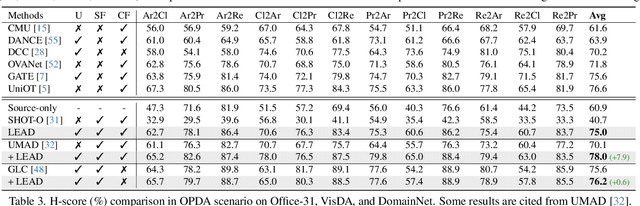
Universal Domain Adaptation (UniDA) targets knowledge transfer in the presence of both covariate and label shifts. Recently, Source-free Universal Domain Adaptation (SF-UniDA) has emerged to achieve UniDA without access to source data, which tends to be more practical due to data protection policies. The main challenge lies in determining whether covariate-shifted samples belong to target-private unknown categories. Existing methods tackle this either through hand-crafted thresholding or by developing time-consuming iterative clustering strategies. In this paper, we propose a new idea of LEArning Decomposition (LEAD), which decouples features into source-known and -unknown components to identify target-private data. Technically, LEAD initially leverages the orthogonal decomposition analysis for feature decomposition. Then, LEAD builds instance-level decision boundaries to adaptively identify target-private data. Extensive experiments across various UniDA scenarios have demonstrated the effectiveness and superiority of LEAD. Notably, in the OPDA scenario on VisDA dataset, LEAD outperforms GLC by 3.5% overall H-score and reduces 75% time to derive pseudo-labeling decision boundaries. Besides, LEAD is also appealing in that it is complementary to most existing methods. The code is available at https://github.com/ispc-lab/LEAD.
Upcycling Models under Domain and Category Shift
Mar 13, 2023



Deep neural networks (DNNs) often perform poorly in the presence of domain shift and category shift. How to upcycle DNNs and adapt them to the target task remains an important open problem. Unsupervised Domain Adaptation (UDA), especially recently proposed Source-free Domain Adaptation (SFDA), has become a promising technology to address this issue. Nevertheless, existing SFDA methods require that the source domain and target domain share the same label space, consequently being only applicable to the vanilla closed-set setting. In this paper, we take one step further and explore the Source-free Universal Domain Adaptation (SF-UniDA). The goal is to identify "known" data samples under both domain and category shift, and reject those "unknown" data samples (not present in source classes), with only the knowledge from standard pre-trained source model. To this end, we introduce an innovative global and local clustering learning technique (GLC). Specifically, we design a novel, adaptive one-vs-all global clustering algorithm to achieve the distinction across different target classes and introduce a local k-NN clustering strategy to alleviate negative transfer. We examine the superiority of our GLC on multiple benchmarks with different category shift scenarios, including partial-set, open-set, and open-partial-set DA. Remarkably, in the most challenging open-partial-set DA scenario, GLC outperforms UMAD by 14.8\% on the VisDA benchmark. The code is available at https://github.com/ispc-lab/GLC.
MoNet: Motion-based Point Cloud Prediction Network
Nov 21, 2020
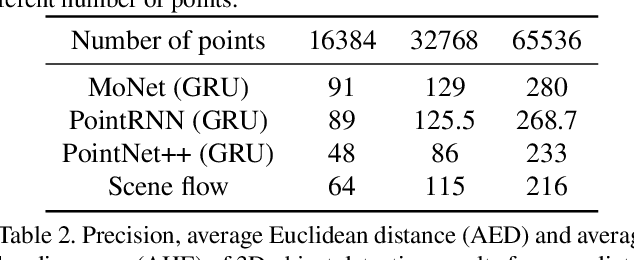
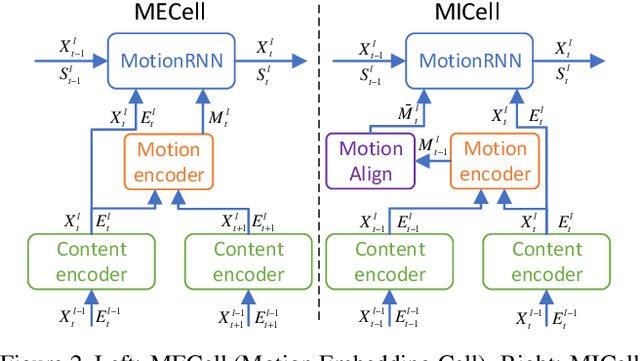
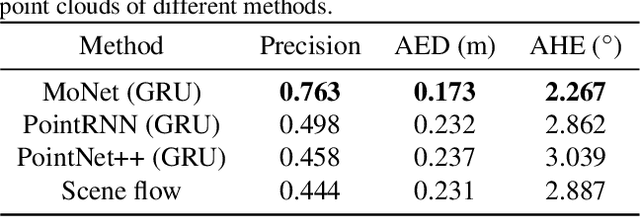
Predicting the future can significantly improve the safety of intelligent vehicles, which is a key component in autonomous driving. 3D point clouds accurately model 3D information of surrounding environment and are crucial for intelligent vehicles to perceive the scene. Therefore, prediction of 3D point clouds has great significance for intelligent vehicles, which can be utilized for numerous further applications. However, due to point clouds are unordered and unstructured, point cloud prediction is challenging and has not been deeply explored in current literature. In this paper, we propose a novel motion-based neural network named MoNet. The key idea of the proposed MoNet is to integrate motion features between two consecutive point clouds into the prediction pipeline. The introduction of motion features enables the model to more accurately capture the variations of motion information across frames and thus make better predictions for future motion. In addition, content features are introduced to model the spatial content of individual point clouds. A recurrent neural network named MotionRNN is proposed to capture the temporal correlations of both features. Besides, we propose an attention-based motion align module to address the problem of missing motion features in the inference pipeline. Extensive experiments on two large scale outdoor LiDAR datasets demonstrate the performance of the proposed MoNet. Moreover, we perform experiments on applications using the predicted point clouds and the results indicate the great application potential of the proposed method.