 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoNet: Motion-based Point Cloud Prediction Network
Paper and Code
Nov 21, 2020
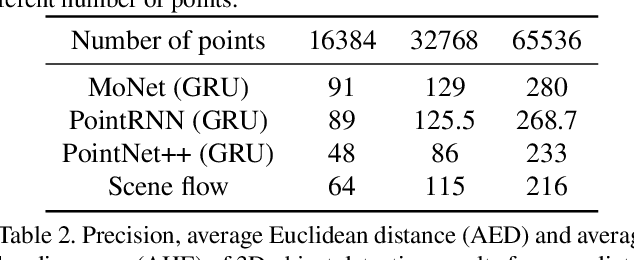
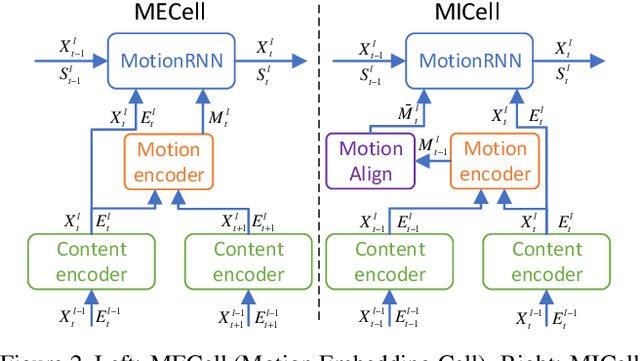
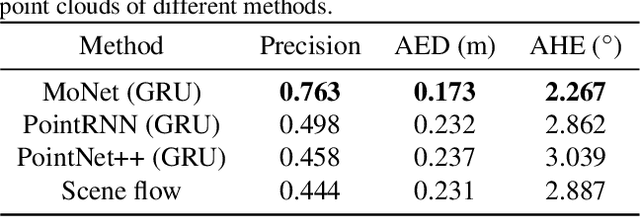
Predicting the future can significantly improve the safety of intelligent vehicles, which is a key component in autonomous driving. 3D point clouds accurately model 3D information of surrounding environment and are crucial for intelligent vehicles to perceive the scene. Therefore, prediction of 3D point clouds has great significance for intelligent vehicles, which can be utilized for numerous further applications. However, due to point clouds are unordered and unstructured, point cloud prediction is challenging and has not been deeply explored in current literature. In this paper, we propose a novel motion-based neural network named MoNet. The key idea of the proposed MoNet is to integrate motion features between two consecutive point clouds into the prediction pipeline. The introduction of motion features enables the model to more accurately capture the variations of motion information across frames and thus make better predictions for future motion. In addition, content features are introduced to model the spatial content of individual point clouds. A recurrent neural network named MotionRNN is proposed to capture the temporal correlations of both features. Besides, we propose an attention-based motion align module to address the problem of missing motion features in the inference pipeline. Extensive experiments on two large scale outdoor LiDAR datasets demonstrate the performance of the proposed MoNet. Moreover, we perform experiments on applications using the predicted point clouds and the results indicate the great application potential of the proposed method.