 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Privacy-Preserving and Heterogeneity-aware Split Federated Learning via Probabilistic Masking
Sep 18, 2025Split Federated Learning (SFL) has emerged as an efficient alternative to traditional Federated Learning (FL) by reducing client-side computation through model partitioning. However, exchanging of intermediate activations and model updates introduces significant privacy risks, especially from data reconstruction attacks that recover original inputs from intermediate representations. Existing defenses using noise injection often degrade model performance. To overcome these challenges, we present PM-SFL, a scalable and privacy-preserving SFL framework that incorporates Probabilistic Mask training to add structured randomness without relying on explicit noise. This mitigates data reconstruction risks while maintaining model utility. To address data heterogeneity, PM-SFL employs personalized mask learning that tailors submodel structures to each client's local data. For system heterogeneity, we introduce a layer-wise knowledge compensation mechanism, enabling clients with varying resources to participate effectively under adaptive model splitting. Theoretical analysis confirms its privacy protection, and experiments on image and wireless sensing tasks demonstrate that PM-SFL consistently improves accuracy, communication efficiency, and robustness to privacy attacks, with particularly strong performance under data and system heterogeneity.
Revisiting Prioritized Experience Replay: A Value Perspective
Feb 05, 2021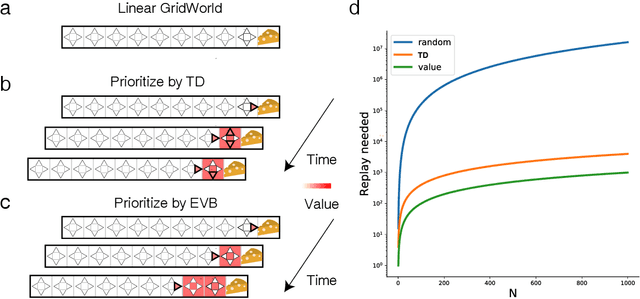
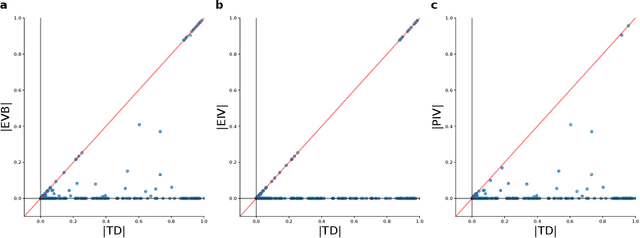
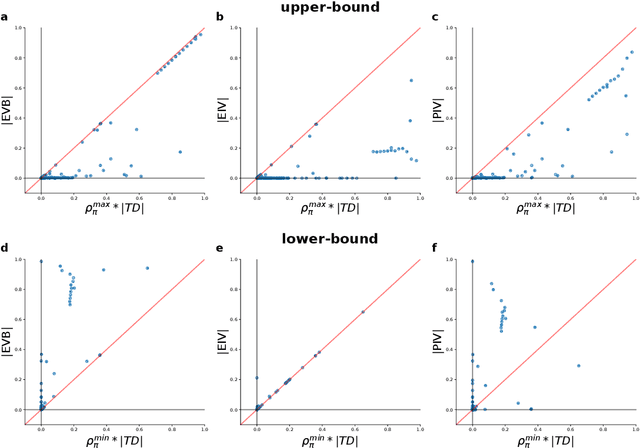
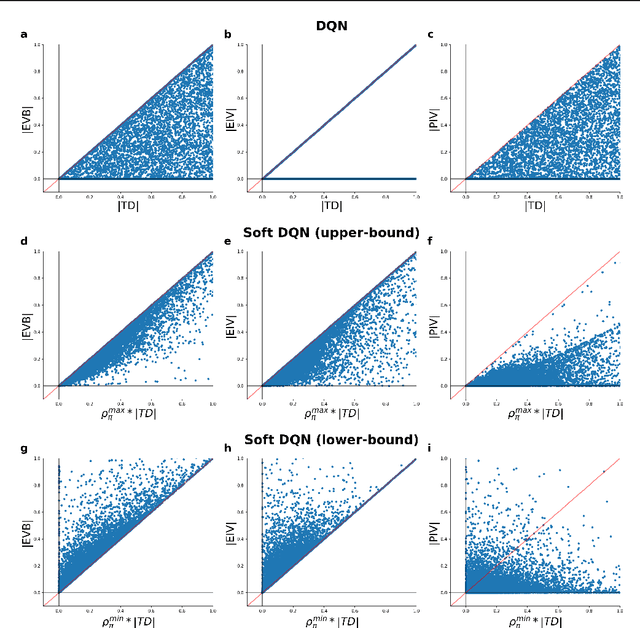
Experience replay enables off-policy reinforcement learning (RL) agents to utilize past experiences to maximize the cumulative reward. Prioritized experience replay that weighs experiences by the magnitude of their temporal-difference error ($|\text{TD}|$) significantly improves the learning efficiency. But how $|\text{TD}|$ is related to the importance of experience is not well understood. We address this problem from an economic perspective, by linking $|\text{TD}|$ to value of experience, which is defined as the value added to the cumulative reward by accessing the experience. We theoretically show the value metrics of experience are upper-bounded by $|\text{TD}|$ for Q-learning. Furthermore, we successfully extend our theoretical framework to maximum-entropy RL by deriving the lower and upper bounds of these value metrics for soft Q-learning, which turn out to be the product of $|\text{TD}|$ and "on-policyness" of the experiences. Our framework links two important quantities in RL: $|\text{TD}|$ and value of experience. We empirically show that the bounds hold in practice, and experience replay using the upper bound as priority improves maximum-entropy RL in Atari games.
Towards Data Poisoning Attack against Knowledge Graph Embedding
Apr 26, 2019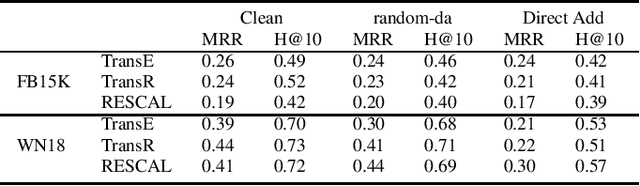
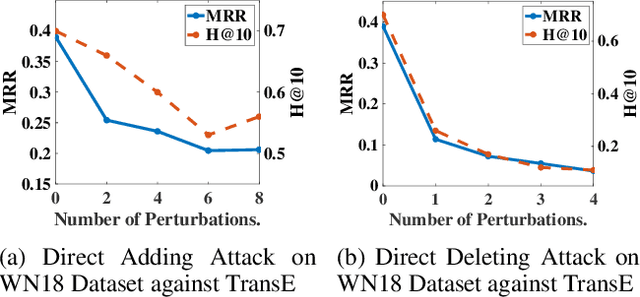
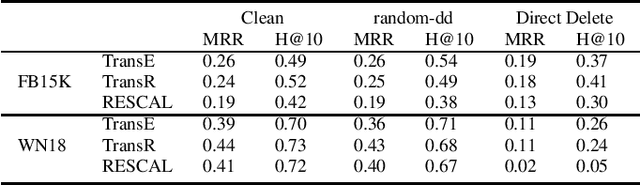
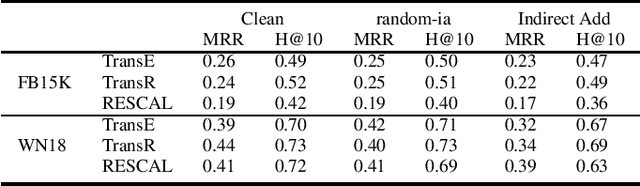
Knowledge graph embedding (KGE) is a technique for learning continuous embeddings for entities and relations in the knowledge graph.Due to its benefit to a variety of downstream tasks such as knowledge graph completion, question answering and recommendation, KGE has gained significant attention recently. Despite its effectiveness in a benign environment, KGE' robustness to adversarial attacks is not well-studied. Existing attack methods on graph data cannot be directly applied to attack the embeddings of knowledge graph due to its heterogeneity. To fill this gap, we propose a collection of data poisoning attack strategies, which can effectively manipulate the plausibility of arbitrary targeted facts in a knowledge graph by adding or deleting facts on the graph. The effectiveness and efficiency of the proposed attack strategies are verified by extensive evaluations on two widely-used benchmarks.
Towards Differentially Private Truth Discovery for Crowd Sensing Systems
Oct 10, 2018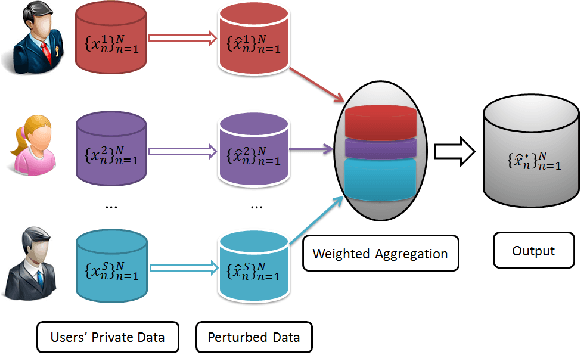
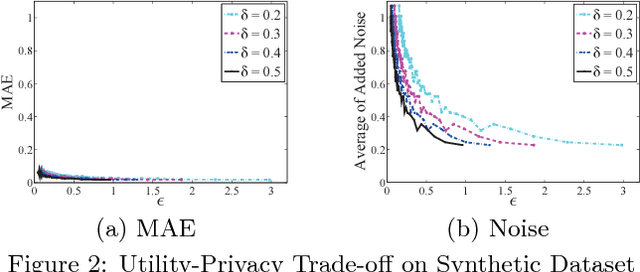
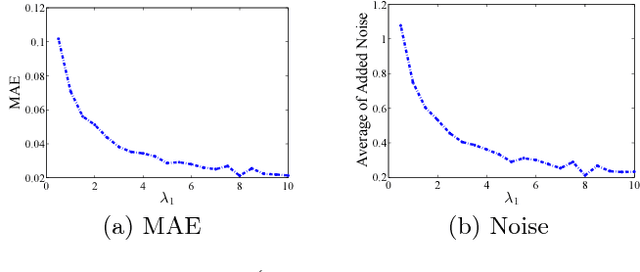
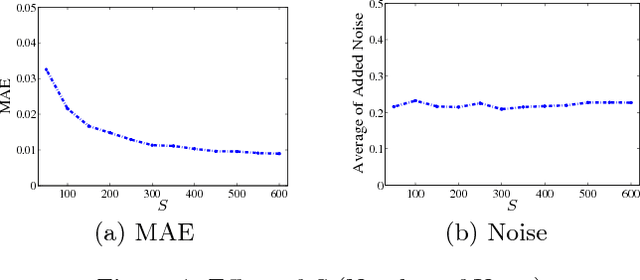
Nowadays, crowd sensing becomes increasingly more popular due to the ubiquitous usage of mobile devices. However, the quality of such human-generated sensory data varies significantly among different users. To better utilize sensory data, the problem of truth discovery, whose goal is to estimate user quality and infer reliable aggregated results through quality-aware data aggregation, has emerged as a hot topic. Although the existing truth discovery approaches can provide reliable aggregated results, they fail to protect the private information of individual users. Moreover, crowd sensing systems typically involve a large number of participants, making encryption or secure multi-party computation based solutions difficult to deploy. To address these challenges, in this paper, we propose an efficient privacy-preserving truth discovery mechanism with theoretical guarantees of both utility and privacy. The key idea of the proposed mechanism is to perturb data from each user independently and then conduct weighted aggregation among users' perturbed data. The proposed approach is able to assign user weights based on information quality, and thus the aggregated results will not deviate much from the true results even when large noise is added. We adapt local differential privacy definition to this privacy-preserving task and demonstrate the proposed mechanism can satisfy local differential privacy while preserving high aggregation accuracy. We formally quantify utility and privacy trade-off and further verify the claim by experiments on both synthetic data and a real-world crowd sensing system.