 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Prioritized Experience Replay: A Value Perspective
Paper and Code
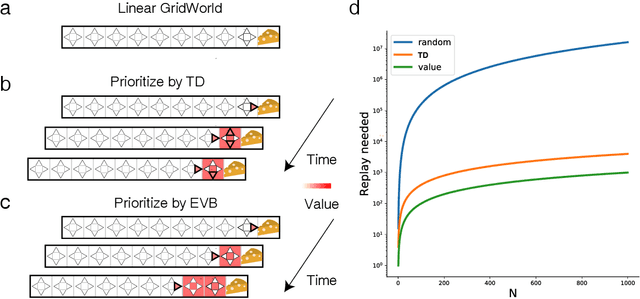
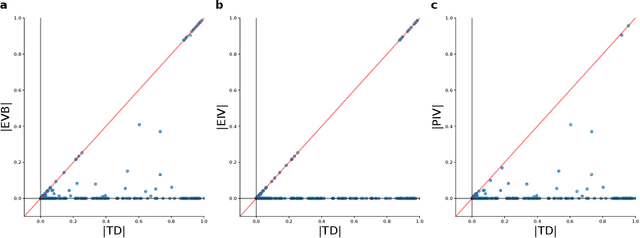
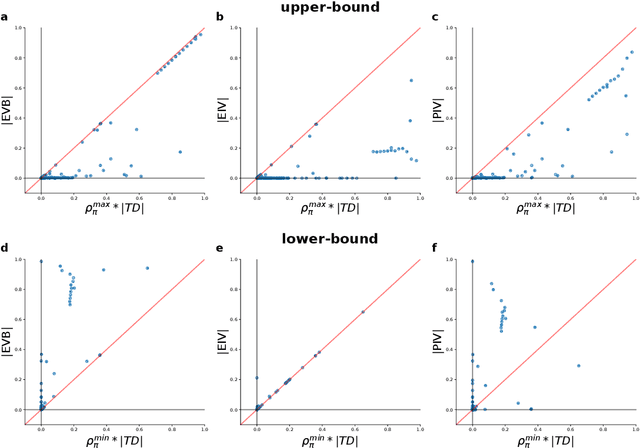
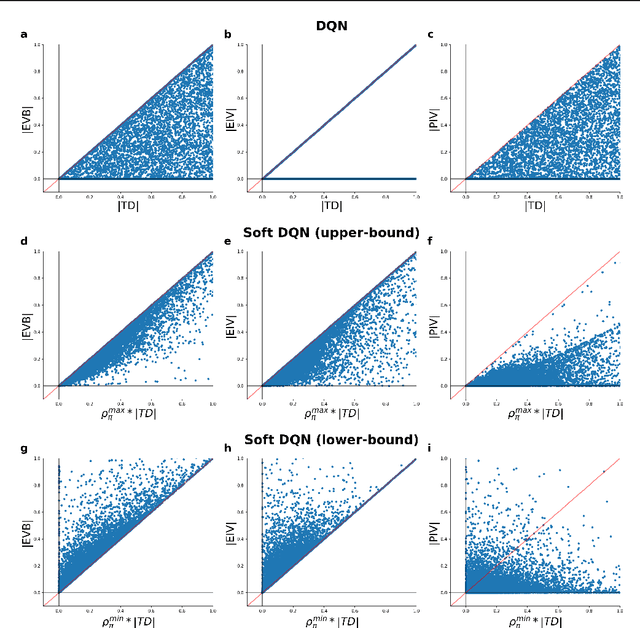
Experience replay enables off-policy reinforcement learning (RL) agents to utilize past experiences to maximize the cumulative reward. Prioritized experience replay that weighs experiences by the magnitude of their temporal-difference error ($|\text{TD}|$) significantly improves the learning efficiency. But how $|\text{TD}|$ is related to the importance of experience is not well understood. We address this problem from an economic perspective, by linking $|\text{TD}|$ to value of experience, which is defined as the value added to the cumulative reward by accessing the experience. We theoretically show the value metrics of experience are upper-bounded by $|\text{TD}|$ for Q-learning. Furthermore, we successfully extend our theoretical framework to maximum-entropy RL by deriving the lower and upper bounds of these value metrics for soft Q-learning, which turn out to be the product of $|\text{TD}|$ and "on-policyness" of the experiences. Our framework links two important quantities in RL: $|\text{TD}|$ and value of experience. We empirically show that the bounds hold in practice, and experience replay using the upper bound as priority improves maximum-entropy RL in Atari games.