 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Privacy-Preserving and Heterogeneity-aware Split Federated Learning via Probabilistic Masking
Sep 18, 2025Split Federated Learning (SFL) has emerged as an efficient alternative to traditional Federated Learning (FL) by reducing client-side computation through model partitioning. However, exchanging of intermediate activations and model updates introduces significant privacy risks, especially from data reconstruction attacks that recover original inputs from intermediate representations. Existing defenses using noise injection often degrade model performance. To overcome these challenges, we present PM-SFL, a scalable and privacy-preserving SFL framework that incorporates Probabilistic Mask training to add structured randomness without relying on explicit noise. This mitigates data reconstruction risks while maintaining model utility. To address data heterogeneity, PM-SFL employs personalized mask learning that tailors submodel structures to each client's local data. For system heterogeneity, we introduce a layer-wise knowledge compensation mechanism, enabling clients with varying resources to participate effectively under adaptive model splitting. Theoretical analysis confirms its privacy protection, and experiments on image and wireless sensing tasks demonstrate that PM-SFL consistently improves accuracy, communication efficiency, and robustness to privacy attacks, with particularly strong performance under data and system heterogeneity.
FIARSE: Model-Heterogeneous Federated Learning via Importance-Aware Submodel Extraction
Jul 28, 2024
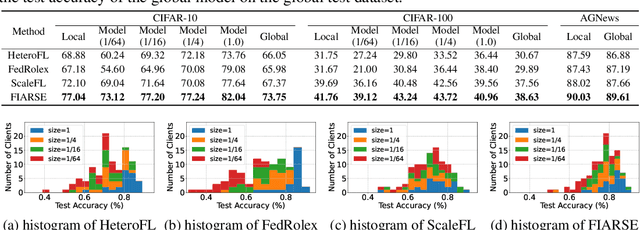
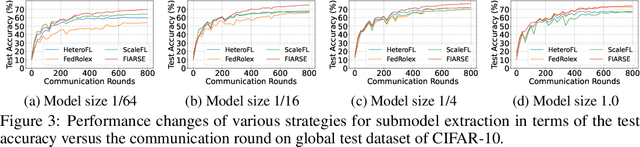

In federated learning (FL), accommodating clients' varied computational capacities poses a challenge, often limiting the participation of those with constrained resources in global model training. To address this issue, the concept of model heterogeneity through submodel extraction has emerged, offering a tailored solution that aligns the model's complexity with each client's computational capacity. In this work, we propose Federated Importance-Aware Submodel Extraction (FIARSE), a novel approach that dynamically adjusts submodels based on the importance of model parameters, thereby overcoming the limitations of previous static and dynamic submodel extraction methods. Compared to existing works, the proposed method offers a theoretical foundation for the submodel extraction and eliminates the need for additional information beyond the model parameters themselves to determine parameter importance, significantly reducing the overhead on clients. Extensive experiments are conducted on various datasets to showcase superior performance of the proposed FIARSE.
On the Client Preference of LLM Fine-tuning in Federated Learning
Jul 03, 2024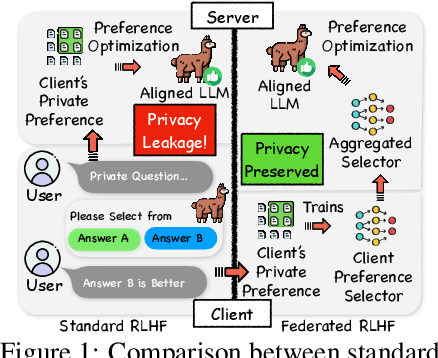
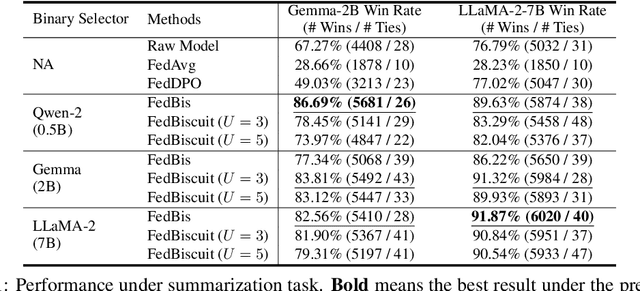
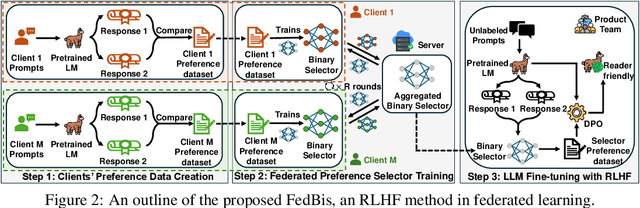
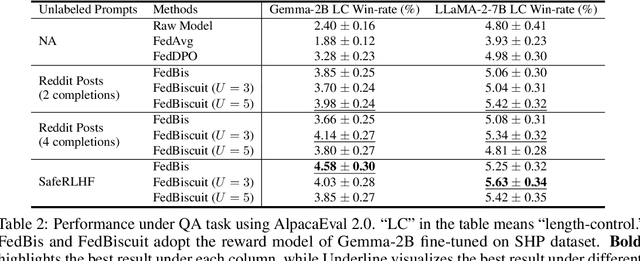
Reinforcement learning with human feedback (RLHF) fine-tunes a pretrained large language model (LLM) using preference datasets, enabling the LLM to generate outputs that align with human preferences. Given the sensitive nature of these preference datasets held by various clients, there is a need to implement RLHF within a federated learning (FL) framework, where clients are reluctant to share their data due to privacy concerns. To address this, we introduce a feasible framework in which clients collaboratively train a binary selector with their preference datasets using our proposed FedBis. With a well-trained selector, we can further enhance the LLM that generates human-preferred completions. Meanwhile, we propose a novel algorithm, FedBiscuit, that trains multiple selectors by organizing clients into balanced and disjoint clusters based on their preferences. Compared to the FedBis, FedBiscuit demonstrates superior performance in simulating human preferences for pairwise completions. Our extensive experiments on federated human preference datasets -- marking the first benchmark to address heterogeneous data partitioning among clients -- demonstrate that FedBiscuit outperforms FedBis and even surpasses traditional centralized training.
MoMa-Pos: Where Should Mobile Manipulators Stand in Cluttered Environment Before Task Execution?
Mar 29, 2024



Mobile manipulators always need to determine feasible base positions prior to carrying out navigation-manipulation tasks. Real-world environments are often cluttered with various furniture, obstacles, and dozens of other objects. Efficiently computing base positions poses a challenge. In this work, we introduce a framework named MoMa-Pos to address this issue. MoMa-Pos first learns to predict a small set of objects that, taken together, would be sufficient for finding base positions using a graph embedding architecture. MoMa-Pos then calculates standing positions by considering furniture structures, robot models, and obstacles comprehensively. We have extensively evaluated the proposed MoMa-Pos across different settings (e.g., environment and algorithm parameters) and with various mobile manipulators. Our empirical results show that MoMa-Pos demonstrates remarkable effectiveness and efficiency in its performance, surpassing the methods in the literature. %, but also is adaptable to cluttered environments and different robot models. Supplementary material can be found at \url{https://yding25.com/MoMa-Pos}.
Efficient Training of Deep Classifiers for Wireless Source Identification using Test SNR Estimates
Dec 26, 2019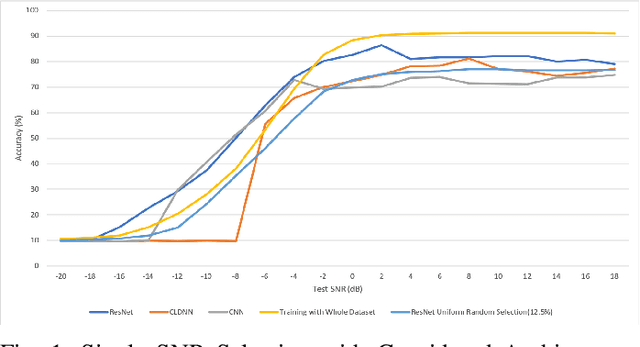
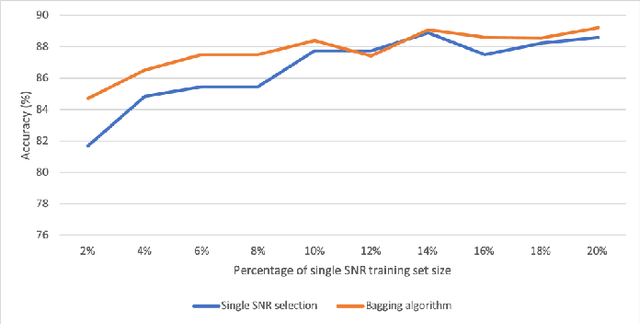
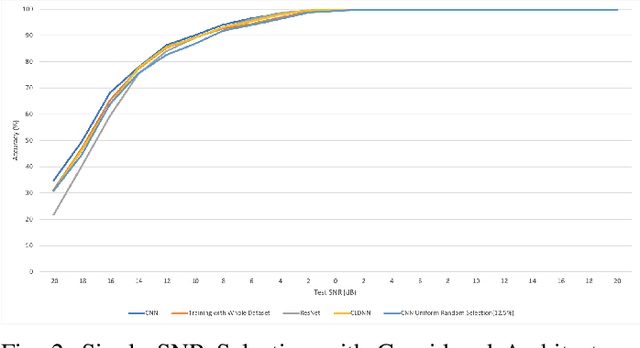

We investigate the potential of training time reduction for deep learning algorithms that process received wireless signals, if an accurate test Signal to Noise Ratio (SNR) estimate is available. Our focus is on two tasks that facilitate source identification: 1- Identifying the modulation type, 2- Identifying the wireless technology and channel index in the 2.4 GHZ ISM band. For benchmarking, we rely on a fast growing recent literature on testing deep learning algorithms against two well-known synthetic datasets. We first demonstrate that using training data corresponding only to the test SNR value leads to dramatic reductions in training time - that can reach up to 35x - while incurring a small loss in average test accuracy, as it improves the accuracy for low test SNR values. Further, we show that an erroneous test SNR estimate with a small positive offset is better for training than another having the same error magnitude with a negative offset. Secondly, we introduce a greedy training SNR Boosting algorithm that leads to uniform improvement in test accuracy across all tested SNR values, while using only a small subset of training SNR values at each test SNR. Finally, we discuss, with empirical evidence, the potential of bootstrap aggregating (Bagging) based on training SNR values to improve generalization at low test SNR