 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Client Preference of LLM Fine-tuning in Federated Learning
Paper and Code
Jul 03, 2024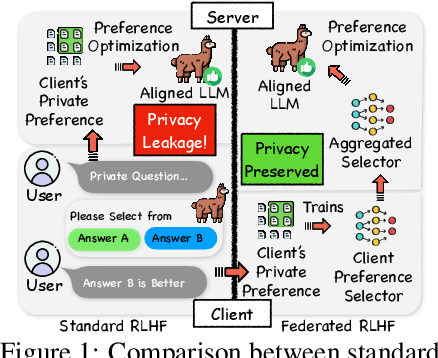
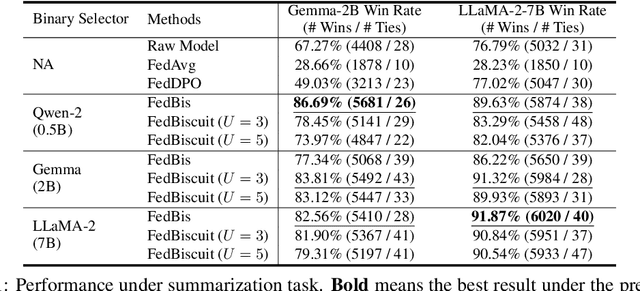
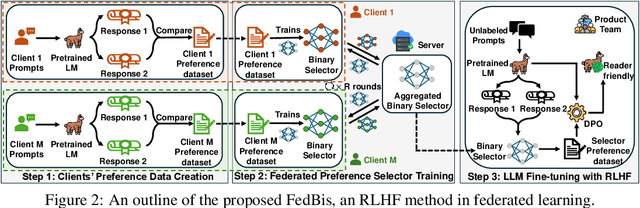
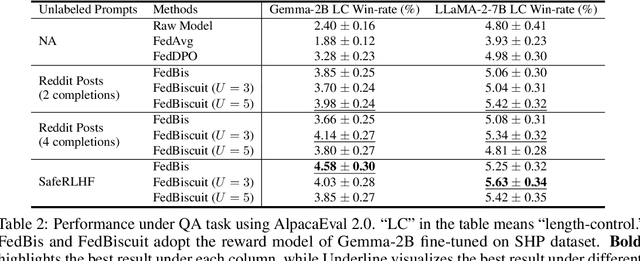
Reinforcement learning with human feedback (RLHF) fine-tunes a pretrained large language model (LLM) using preference datasets, enabling the LLM to generate outputs that align with human preferences. Given the sensitive nature of these preference datasets held by various clients, there is a need to implement RLHF within a federated learning (FL) framework, where clients are reluctant to share their data due to privacy concerns. To address this, we introduce a feasible framework in which clients collaboratively train a binary selector with their preference datasets using our proposed FedBis. With a well-trained selector, we can further enhance the LLM that generates human-preferred completions. Meanwhile, we propose a novel algorithm, FedBiscuit, that trains multiple selectors by organizing clients into balanced and disjoint clusters based on their preferences. Compared to the FedBis, FedBiscuit demonstrates superior performance in simulating human preferences for pairwise completions. Our extensive experiments on federated human preference datasets -- marking the first benchmark to address heterogeneous data partitioning among clients -- demonstrate that FedBiscuit outperforms FedBis and even surpasses traditional centralized training.