 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Wrapper Subsampling for Deep Modulation Classification
May 10, 2020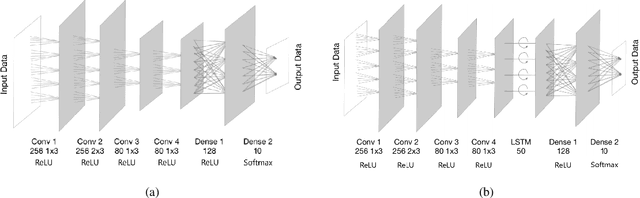
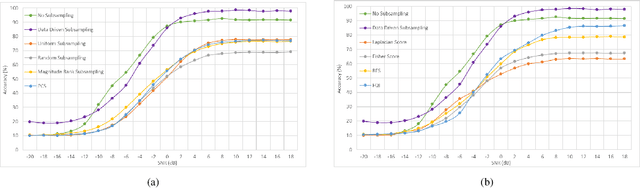
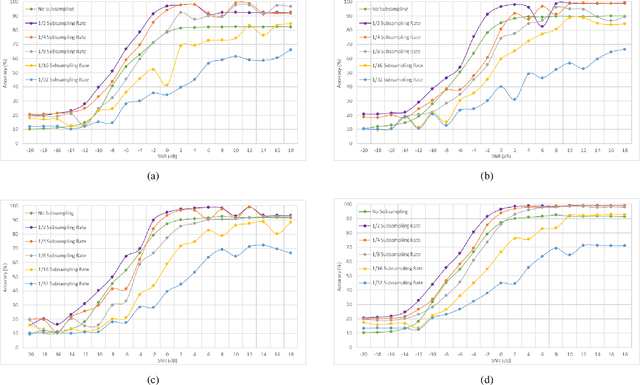
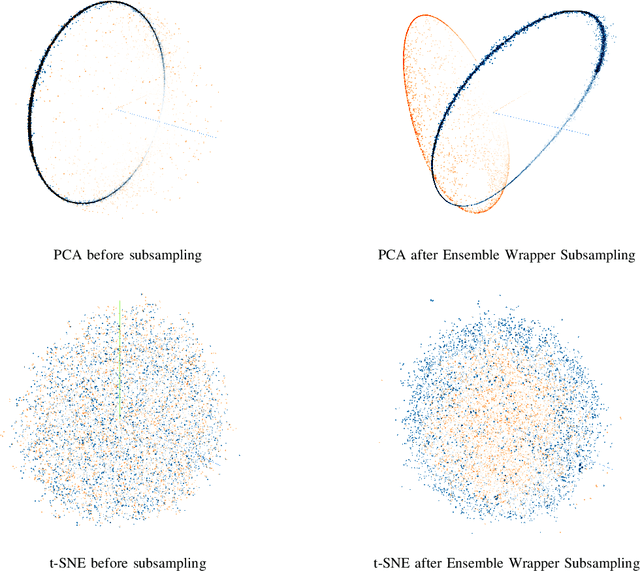
Subsampling of received wireless signals is important for relaxing hardware requirements as well as the computational cost of signal processing algorithms that rely on the output samples. We propose a subsampling technique to facilitate the use of deep learning for automatic modulation classification in wireless communication systems. Unlike traditional approaches that rely on pre-designed strategies that are solely based on expert knowledge, the proposed data-driven subsampling strategy employs deep neural network architectures to simulate the effect of removing candidate combinations of samples from each training input vector, in a manner inspired by how wrapper feature selection models work. The subsampled data is then processed by another deep learning classifier that recognizes each of the considered 10 modulation types. We show that the proposed subsampling strategy not only introduces drastic reduction in the classifier training time, but can also improve the classification accuracy to higher levels than those reached before for the considered dataset. An important feature herein is exploiting the transferability property of deep neural networks to avoid retraining the wrapper models and obtain superior performance through an ensemble of wrappers over that possible through solely relying on any of them.
Efficient Training of Deep Classifiers for Wireless Source Identification using Test SNR Estimates
Dec 26, 2019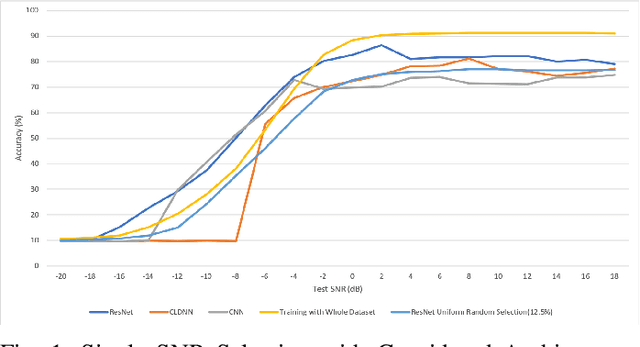
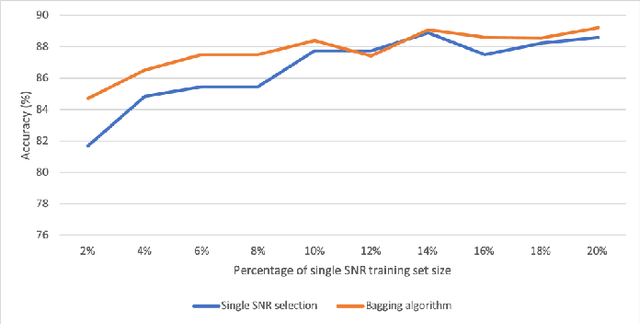

We investigate the potential of training time reduction for deep learning algorithms that process received wireless signals, if an accurate test Signal to Noise Ratio (SNR) estimate is available. Our focus is on two tasks that facilitate source identification: 1- Identifying the modulation type, 2- Identifying the wireless technology and channel index in the 2.4 GHZ ISM band. For benchmarking, we rely on a fast growing recent literature on testing deep learning algorithms against two well-known synthetic datasets. We first demonstrate that using training data corresponding only to the test SNR value leads to dramatic reductions in training time - that can reach up to 35x - while incurring a small loss in average test accuracy, as it improves the accuracy for low test SNR values. Further, we show that an erroneous test SNR estimate with a small positive offset is better for training than another having the same error magnitude with a negative offset. Secondly, we introduce a greedy training SNR Boosting algorithm that leads to uniform improvement in test accuracy across all tested SNR values, while using only a small subset of training SNR values at each test SNR. Finally, we discuss, with empirical evidence, the potential of bootstrap aggregating (Bagging) based on training SNR values to improve generalization at low test SNR
Efficient Wrapper Feature Selection using Autoencoder and Model Based Elimination
May 28, 2019
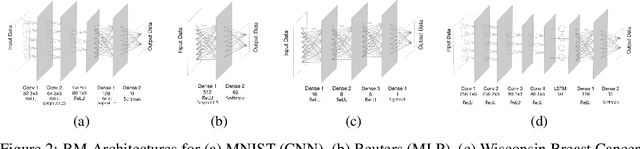
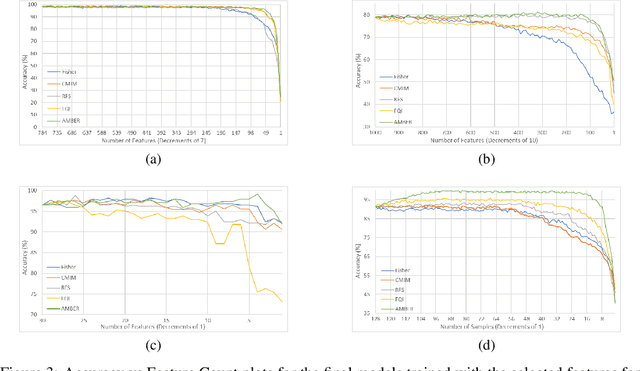

We propose a computationally efficient wrapper feature selection method - called Autoencoder and Model Based Elimination of features using Relevance and Redundancy scores (AMBER) - that uses a single ranker model along with autoencoders to perform greedy backward elimination of features. The ranker model is used to prioritize the removal of features that are not critical to the classification task, while the autoencoders are used to prioritize the elimination of correlated features. We demonstrate the superior feature selection ability of AMBER on 4 well known datasets corresponding to different domain applications via comparing the classification accuracies with other computationally efficient state-of-the-art feature selection techniques. Interestingly, we find that the ranker model that is used for feature selection does not necessarily have to be the same as the final classifier that is trained on the selected features. Finally, we note how a smaller number of features can lead to higher accuracies on some datasets, and hypothesize that overfitting the ranker model on the training set facilitates the selection of more salient features.
Deep Learning for Interference Identification: Band, Training SNR, and Sample Selection
May 16, 2019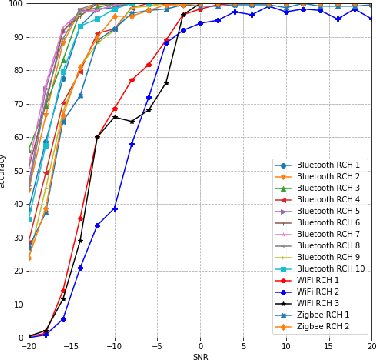
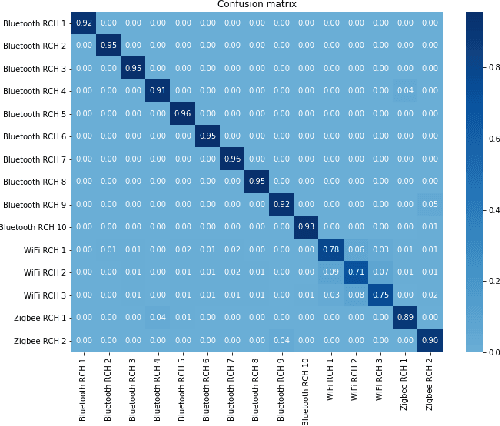
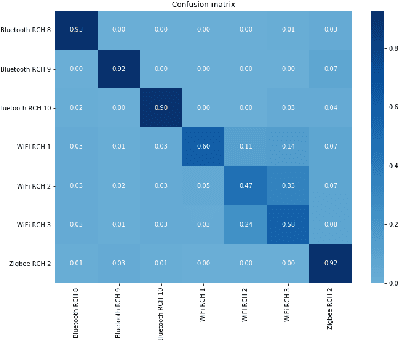
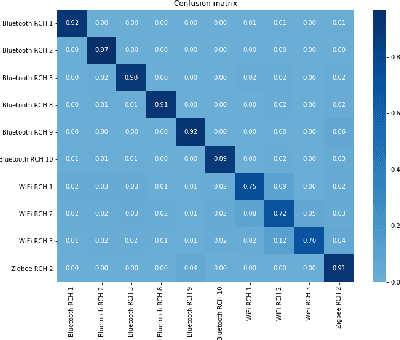
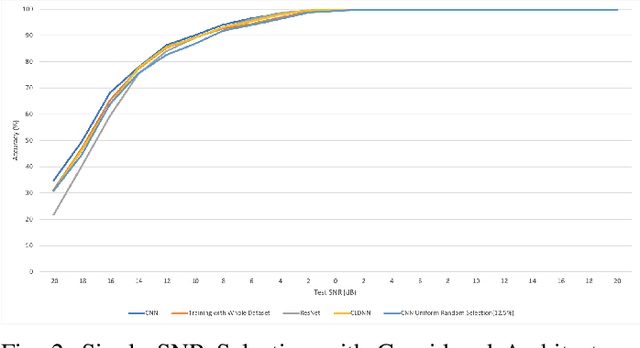
We study the problem of interference source identification, through the lens of recognizing one of 15 different channels that belong to 3 different wireless technologies: Bluetooth, Zigbee, and WiFi. We employ deep learning algorithms trained on received samples taken from a 10 MHz band in the 2.4 GHz ISM Band. We obtain a classification accuracy of around 89.5% using any of four different deep neural network architectures: CNN, ResNet, CLDNN, and LSTM, which demonstrate the generality of the effectiveness of deep learning at the considered task. Interestingly, our proposed CNN architecture requires approximately 60% of the training time required by the state of the art while achieving slightly larger classification accuracy. We then focus on the CNN architecture and further optimize its training time while incurring minimal loss in classification accuracy using three different approaches: 1- Band Selection, where we only use samples belonging to the lower and uppermost 2 MHz bands, 2- SNR Selection, where we only use training samples belonging to a single SNR value, and 3- Sample Selection, where we try various sub-Nyquist sampling methods to select the subset of samples most relevant to the classification task. Our results confirm the feasibility of fast deep learning for wireless interference identification, by showing that the training time can be reduced by as much as 30x with minimal loss in accuracy.
Fast Deep Learning for Automatic Modulation Classification
Jan 16, 2019
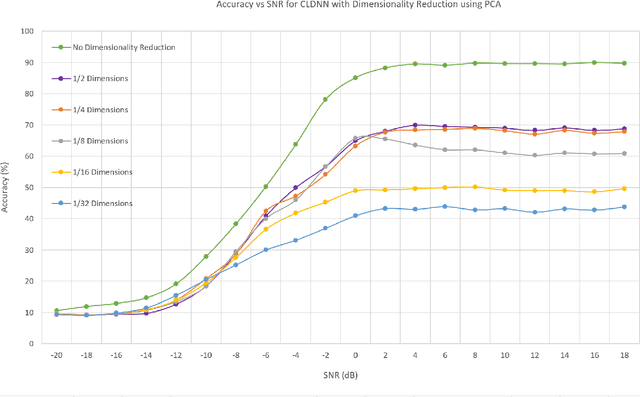
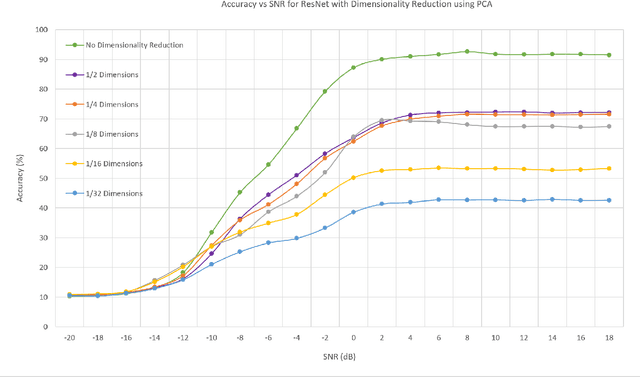
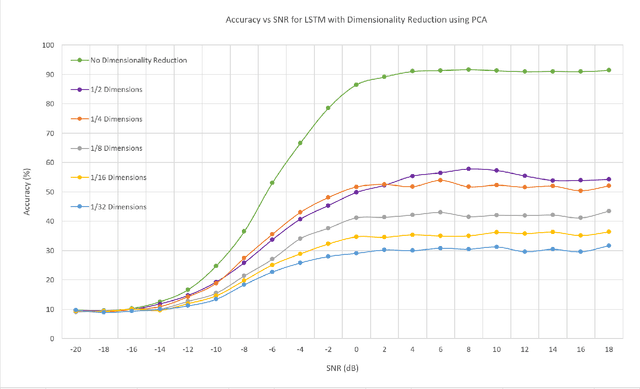
In this work, we investigate the feasibility and effectiveness of employing deep learning algorithms for automatic recognition of the modulation type of received wireless communication signals from subsampled data. Recent work considered a GNU radio-based data set that mimics the imperfections in a real wireless channel and uses 10 different modulation types. A Convolutional Neural Network (CNN) architecture was then developed and shown to achieve performance that exceeds that of expert-based approaches. Here, we continue this line of work and investigate deep neural network architectures that deliver high classification accuracy. We identify three architectures - namely, a Convolutional Long Short-term Deep Neural Network (CLDNN), a Long Short-Term Memory neural network (LSTM), and a deep Residual Network (ResNet) - that lead to typical classification accuracy values around 90% at high SNR. We then study algorithms to reduce the training time by minimizing the size of the training data set, while incurring a minimal loss in classification accuracy. To this end, we demonstrate the performance of Principal Component Analysis in significantly reducing the training time, while maintaining good performance at low SNR. We also investigate subsampling techniques that further reduce the training time, and pave the way for online classification at high SNR. Finally, we identify representative SNR values for training each of the candidate architectures, and consequently, realize drastic reductions of the training time, with negligible loss in classification accuracy.