 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Wrapper Feature Selection using Autoencoder and Model Based Elimination
Paper and Code

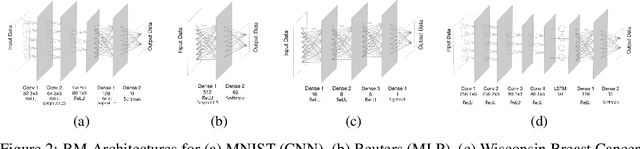
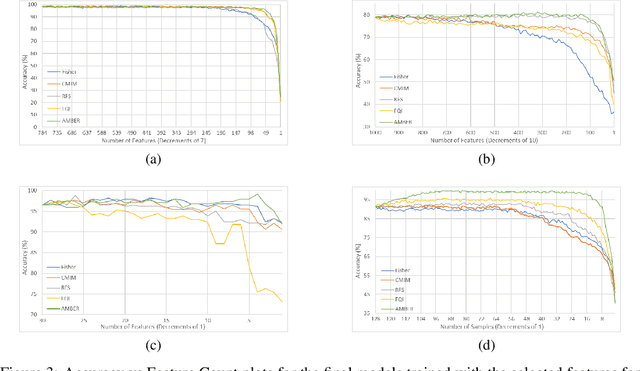

We propose a computationally efficient wrapper feature selection method - called Autoencoder and Model Based Elimination of features using Relevance and Redundancy scores (AMBER) - that uses a single ranker model along with autoencoders to perform greedy backward elimination of features. The ranker model is used to prioritize the removal of features that are not critical to the classification task, while the autoencoders are used to prioritize the elimination of correlated features. We demonstrate the superior feature selection ability of AMBER on 4 well known datasets corresponding to different domain applications via comparing the classification accuracies with other computationally efficient state-of-the-art feature selection techniques. Interestingly, we find that the ranker model that is used for feature selection does not necessarily have to be the same as the final classifier that is trained on the selected features. Finally, we note how a smaller number of features can lead to higher accuracies on some datasets, and hypothesize that overfitting the ranker model on the training set facilitates the selection of more salient features.