 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast KVzip: Efficient and Accurate LLM Inference with Gated KV Eviction
Jan 25, 2026Efficient key-value (KV) cache management is crucial for the practical deployment of large language models (LLMs), yet existing compression techniques often incur a trade-off between performance degradation and computational overhead. We propose a novel gating-based KV cache eviction method for frozen-weight LLMs that achieves high compression ratios with negligible computational cost. Our approach introduces lightweight sink-attention gating modules to identify and retain critical KV pairs, and integrates seamlessly into both the prefill and decoding stages. The proposed gate training algorithm relies on forward passes of an LLM, avoiding expensive backpropagation, while achieving strong task generalization through a task-agnostic reconstruction objective. Extensive experiments across the Qwen2.5-1M, Qwen3, and Gemma3 families show that our method maintains near-lossless performance while evicting up to 70% of the KV cache. The results are consistent across a wide range of tasks, including long-context understanding, code comprehension, and mathematical reasoning, demonstrating the generality of our approach.
KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction
May 29, 2025Transformer-based large language models (LLMs) cache context as key-value (KV) pairs during inference. As context length grows, KV cache sizes expand, leading to substantial memory overhead and increased attention latency. This paper introduces KVzip, a query-agnostic KV cache eviction method enabling effective reuse of compressed KV caches across diverse queries. KVzip quantifies the importance of a KV pair using the underlying LLM to reconstruct original contexts from cached KV pairs, subsequently evicting pairs with lower importance. Extensive empirical evaluations demonstrate that KVzip reduces KV cache size by 3-4$\times$ and FlashAttention decoding latency by approximately 2$\times$, with negligible performance loss in question-answering, retrieval, reasoning, and code comprehension tasks. Evaluations include various models such as LLaMA3.1-8B, Qwen2.5-14B, and Gemma3-12B, with context lengths reaching up to 170K tokens. KVzip significantly outperforms existing query-aware KV eviction methods, which suffer from performance degradation even at a 90% cache budget ratio under multi-query scenarios.
Targeted Cause Discovery with Data-Driven Learning
Aug 29, 2024



We propose a novel machine learning approach for inferring causal variables of a target variable from observations. Our goal is to identify both direct and indirect causes within a system, thereby efficiently regulating the target variable when the difficulty and cost of intervening on each causal variable vary. Our method employs a neural network trained to identify causality through supervised learning on simulated data. By implementing a local-inference strategy, we achieve linear complexity with respect to the number of variables, efficiently scaling up to thousands of variables. Empirical results demonstrate the effectiveness of our method in identifying causal relationships within large-scale gene regulatory networks, outperforming existing causal discovery methods that primarily focus on direct causality. We validate our model's generalization capability across novel graph structures and generating mechanisms, including gene regulatory networks of E. coli and the human K562 cell line. Implementation codes are available at https://github.com/snu-mllab/Targeted-Cause-Discovery.
Compressed Context Memory For Online Language Model Interaction
Dec 06, 2023This paper presents a novel context compression method for Transformer language models in online scenarios such as ChatGPT, where the context continually expands. As the context lengthens, the attention process requires more memory and computational resources, which in turn reduces the throughput of the language model. To this end, we propose a compressed context memory system that continually compresses the growing context into a compact memory space. The compression process simply involves integrating a lightweight conditional LoRA into the language model's forward pass during inference. Based on the compressed context memory, the language model can perform inference with reduced memory and attention operations. Through evaluations on conversation, personalization, and multi-task learning, we demonstrate that our approach achieves the performance level of a full context model with $5\times$ smaller context memory space. Codes are available at https://github.com/snu-mllab/context-memory.
Neural Relation Graph for Identifying Problematic Data
Jan 29, 2023Diagnosing and cleaning datasets are crucial for building robust machine learning systems. However, identifying problems within large-scale datasets with real-world distributions is difficult due to the presence of complex issues, such as label errors or under-representation of certain types. In this paper, we propose a novel approach for identifying problematic data by utilizing a largely ignored source of information: a relational structure of data in the feature-embedded space. We develop an efficient algorithm for detecting label errors and outlier data points based on the relational graph structure of the dataset. We further introduce a visualization tool for contextualizing data points, which can serve as an effective tool for interactively diagnosing datasets. We evaluate label error and out-of-distribution detection performances on large-scale image and language domain tasks, including ImageNet and GLUE benchmarks, and demonstrate the effectiveness of our approach for debugging datasets and building robust machine learning systems.
Dataset Condensation via Efficient Synthetic-Data Parameterization
Jun 02, 2022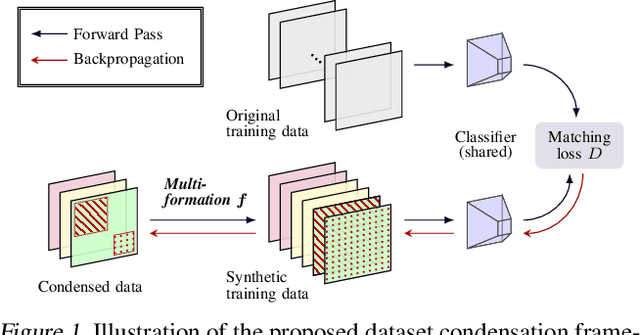
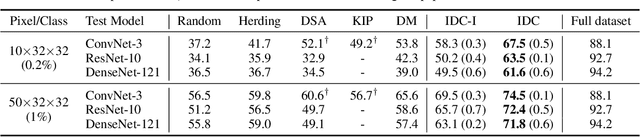
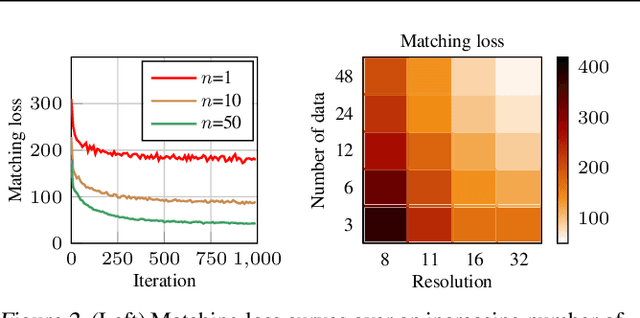
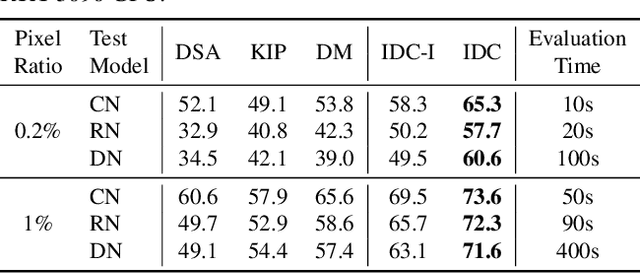
The great success of machine learning with massive amounts of data comes at a price of huge computation costs and storage for training and tuning. Recent studies on dataset condensation attempt to reduce the dependence on such massive data by synthesizing a compact training dataset. However, the existing approaches have fundamental limitations in optimization due to the limited representability of synthetic datasets without considering any data regularity characteristics. To this end, we propose a novel condensation framework that generates multiple synthetic data with a limited storage budget via efficient parameterization considering data regularity. We further analyze the shortcomings of the existing gradient matching-based condensation methods and develop an effective optimization technique for improving the condensation of training data information. We propose a unified algorithm that drastically improves the quality of condensed data against the current state-of-the-art on CIFAR-10, ImageNet, and Speech Commands.
Uncertainty-Based Offline Reinforcement Learning with Diversified Q-Ensemble
Oct 05, 2021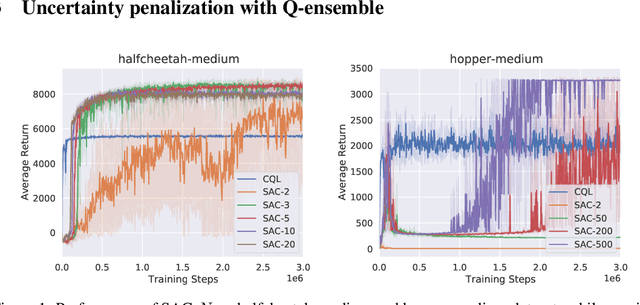
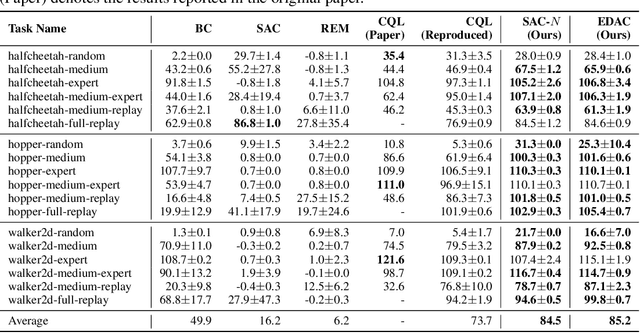
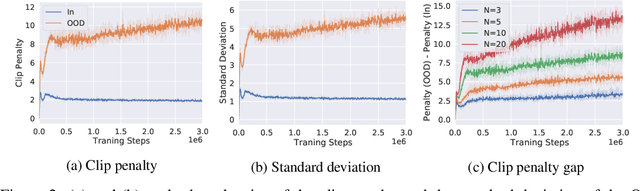
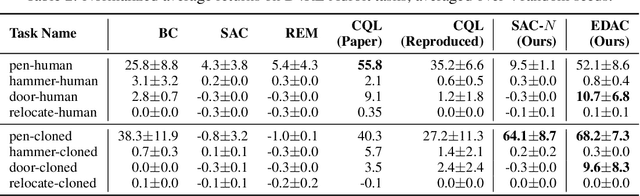
Offline reinforcement learning (offline RL), which aims to find an optimal policy from a previously collected static dataset, bears algorithmic difficulties due to function approximation errors from out-of-distribution (OOD) data points. To this end, offline RL algorithms adopt either a constraint or a penalty term that explicitly guides the policy to stay close to the given dataset. However, prior methods typically require accurate estimation of the behavior policy or sampling from OOD data points, which themselves can be a non-trivial problem. Moreover, these methods under-utilize the generalization ability of deep neural networks and often fall into suboptimal solutions too close to the given dataset. In this work, we propose an uncertainty-based offline RL method that takes into account the confidence of the Q-value prediction and does not require any estimation or sampling of the data distribution. We show that the clipped Q-learning, a technique widely used in online RL, can be leveraged to successfully penalize OOD data points with high prediction uncertainties. Surprisingly, we find that it is possible to substantially outperform existing offline RL methods on various tasks by simply increasing the number of Q-networks along with the clipped Q-learning. Based on this observation, we propose an ensemble-diversified actor-critic algorithm that reduces the number of required ensemble networks down to a tenth compared to the naive ensemble while achieving state-of-the-art performance on most of the D4RL benchmarks considered.
Co-Mixup: Saliency Guided Joint Mixup with Supermodular Diversity
Feb 05, 2021
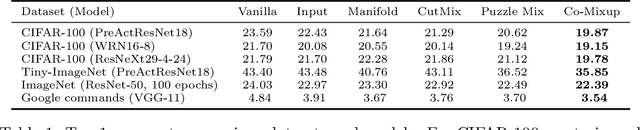
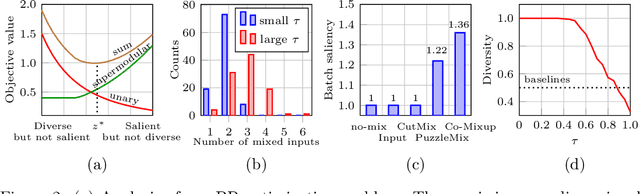

While deep neural networks show great performance on fitting to the training distribution, improving the networks' generalization performance to the test distribution and robustness to the sensitivity to input perturbations still remain as a challenge. Although a number of mixup based augmentation strategies have been proposed to partially address them, it remains unclear as to how to best utilize the supervisory signal within each input data for mixup from the optimization perspective. We propose a new perspective on batch mixup and formulate the optimal construction of a batch of mixup data maximizing the data saliency measure of each individual mixup data and encouraging the supermodular diversity among the constructed mixup data. This leads to a novel discrete optimization problem minimizing the difference between submodular functions. We also propose an efficient modular approximation based iterative submodular minimization algorithm for efficient mixup computation per each minibatch suitable for minibatch based neural network training. Our experiments show the proposed method achieves the state of the art generalization, calibration, and weakly supervised localization results compared to other mixup methods. The source code is available at https://github.com/snu-mllab/Co-Mixup.
Puzzle Mix: Exploiting Saliency and Local Statistics for Optimal Mixup
Sep 15, 2020

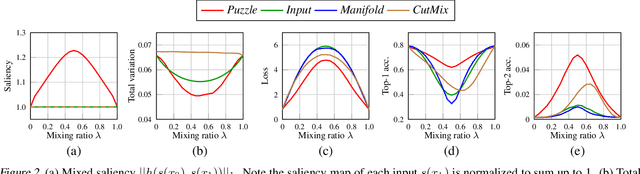
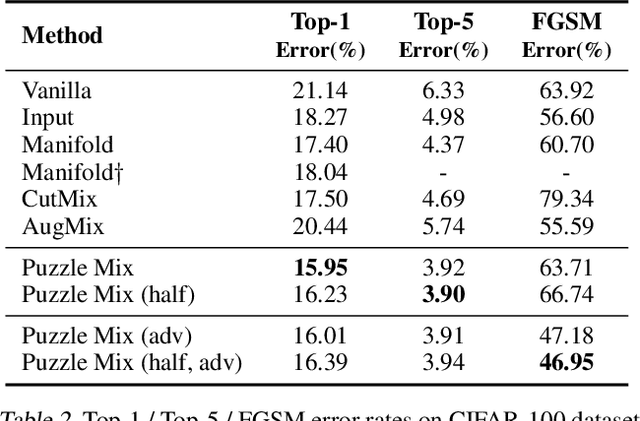
While deep neural networks achieve great performance on fitting the training distribution, the learned networks are prone to overfitting and are susceptible to adversarial attacks. In this regard, a number of mixup based augmentation methods have been recently proposed. However, these approaches mainly focus on creating previously unseen virtual examples and can sometimes provide misleading supervisory signal to the network. To this end, we propose Puzzle Mix, a mixup method for explicitly utilizing the saliency information and the underlying statistics of the natural examples. This leads to an interesting optimization problem alternating between the multi-label objective for optimal mixing mask and saliency discounted optimal transport objective. Our experiments show Puzzle Mix achieves the state of the art generalization and the adversarial robustness results compared to other mixup methods on CIFAR-100, Tiny-ImageNet, and ImageNet datasets. The source code is available at https://github.com/snu-mllab/PuzzleMix.
Spherical Principal Curves
Mar 05, 2020
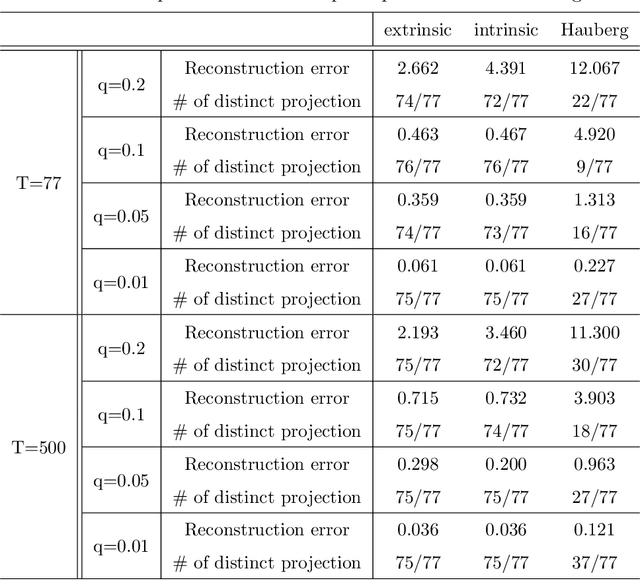
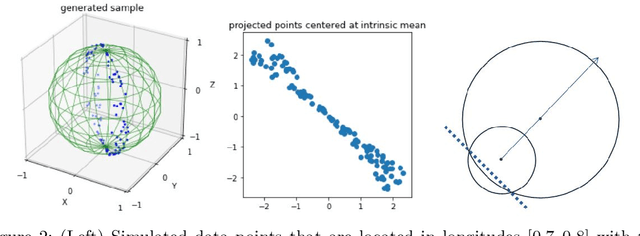
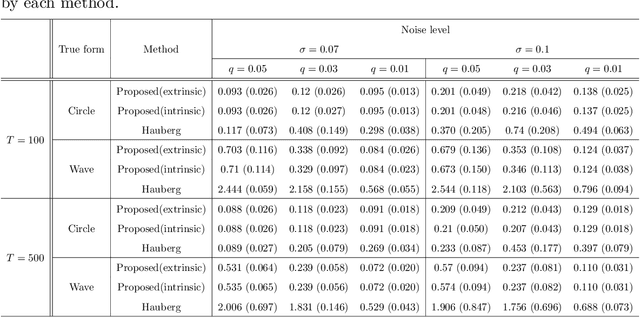
This paper presents a new approach for dimension reduction of data observed in a sphere. Several dimension reduction techniques have recently developed for the analysis of non-Euclidean data. As a pioneer work, Hauberg (2016) attempted to implement principal curves on Riemannian manifolds. However, this approach uses approximations to deal with data on Riemannian manifolds, which causes distorted results. In this study, we propose a new approach to construct principal curves on a sphere by a projection of the data onto a continuous curve. Our approach lies in the same line of Hastie and Stuetzle (1989) that proposed principal curves for Euclidean space data. We further investigate the stationarity of the proposed principal curves that satisfy the self-consistency on a sphere. Results from real data analysis with earthquake data and simulation examples demonstrate the promising empirical properties of the proposed approach.