 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Stream of Search: Learning to Better Search with Language Models via Optimal Path Guidance
Oct 03, 2024While language models have demonstrated impressive capabilities across a range of tasks, they still struggle with tasks that require complex planning and reasoning. Recent studies have proposed training language models on search processes rather than optimal solutions, resulting in better generalization performance even though search processes are noisy and even suboptimal. However, these studies overlook the value of optimal solutions, which can serve as step-by-step landmarks to guide more effective search. In this work, we explore how to leverage optimal solutions to enhance the search and planning abilities of language models. To this end, we propose guided stream of search (GSoS), which seamlessly incorporates optimal solutions into the self-generation process in a progressive manner, producing high-quality search trajectories. These trajectories are then distilled into the pre-trained model via supervised fine-tuning. Our approach significantly enhances the search and planning abilities of language models on Countdown, a simple yet challenging mathematical reasoning task. Notably, combining our method with RL fine-tuning yields further improvements, whereas previous supervised fine-tuning methods do not benefit from RL. Furthermore, our approach exhibits greater effectiveness than leveraging optimal solutions in the form of subgoal rewards.
Discovering Hierarchical Achievements in Reinforcement Learning via Contrastive Learning
Jul 07, 2023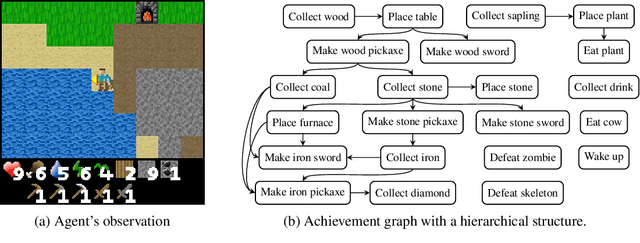
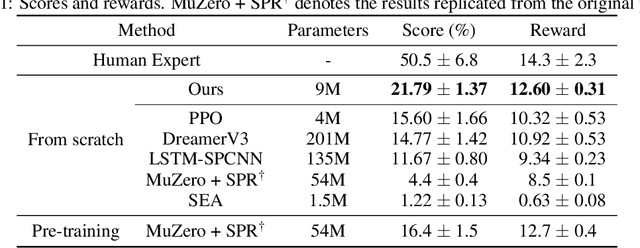
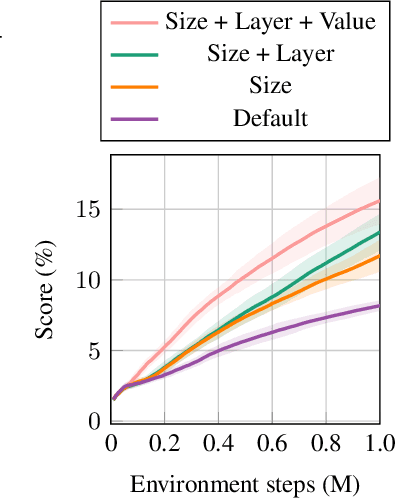
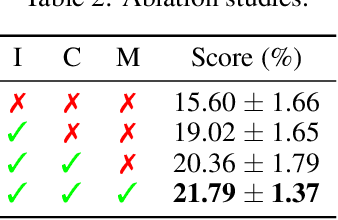
Discovering achievements with a hierarchical structure on procedurally generated environments poses a significant challenge. This requires agents to possess a broad range of abilities, including generalization and long-term reasoning. Many prior methods are built upon model-based or hierarchical approaches, with the belief that an explicit module for long-term planning would be beneficial for learning hierarchical achievements. However, these methods require an excessive amount of environment interactions or large model sizes, limiting their practicality. In this work, we identify that proximal policy optimization (PPO), a simple and versatile model-free algorithm, outperforms the prior methods with recent implementation practices. Moreover, we find that the PPO agent can predict the next achievement to be unlocked to some extent, though with low confidence. Based on this observation, we propose a novel contrastive learning method, called achievement distillation, that strengthens the agent's capability to predict the next achievement. Our method exhibits a strong capacity for discovering hierarchical achievements and shows state-of-the-art performance on the challenging Crafter environment using fewer model parameters in a sample-efficient regime.
Rethinking Value Function Learning for Generalization in Reinforcement Learning
Oct 18, 2022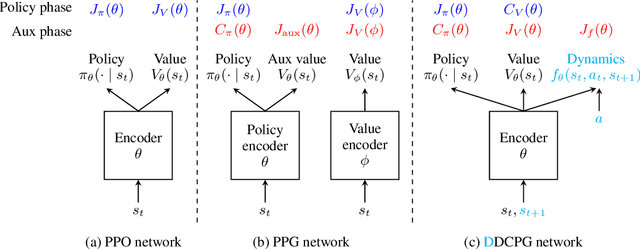
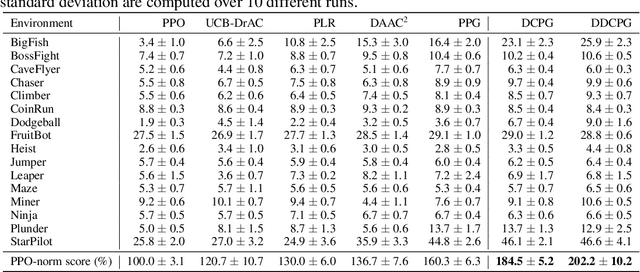
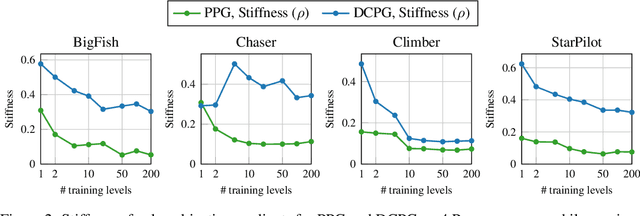

We focus on the problem of training RL agents on multiple training environments to improve observational generalization performance. In prior methods, policy and value networks are separately optimized using a disjoint network architecture to avoid interference and obtain a more accurate value function. We identify that the value network in the multiple-environment setting is more challenging to optimize and prone to overfitting training data than in the conventional single-environment setting. In addition, we find that appropriate regularization of the value network is required for better training and test performance. To this end, we propose Delayed-Critic Policy Gradient (DCPG), which implicitly penalizes the value estimates by optimizing the value network less frequently with more training data than the policy network, which can be implemented using a shared network architecture. Furthermore, we introduce a simple self-supervised task that learns the forward and inverse dynamics of environments using a single discriminator, which can be jointly optimized with the value network. Our proposed algorithms significantly improve observational generalization performance and sample efficiency in the Procgen Benchmark.
Query-Efficient and Scalable Black-Box Adversarial Attacks on Discrete Sequential Data via Bayesian Optimization
Jun 17, 2022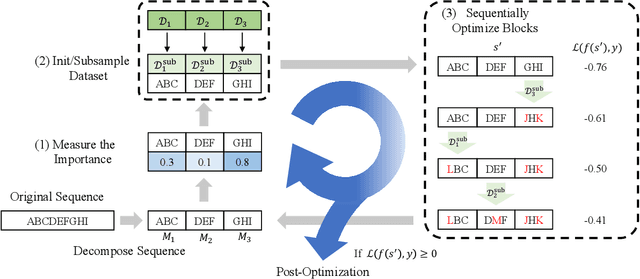
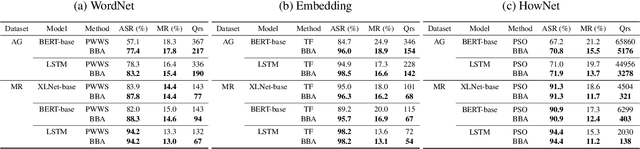
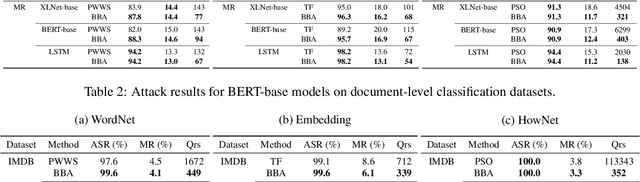
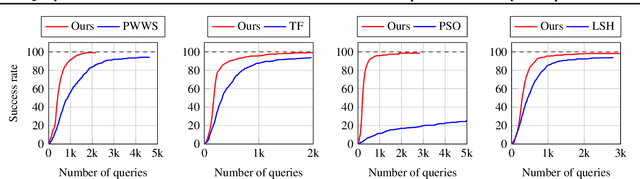
We focus on the problem of adversarial attacks against models on discrete sequential data in the black-box setting where the attacker aims to craft adversarial examples with limited query access to the victim model. Existing black-box attacks, mostly based on greedy algorithms, find adversarial examples using pre-computed key positions to perturb, which severely limits the search space and might result in suboptimal solutions. To this end, we propose a query-efficient black-box attack using Bayesian optimization, which dynamically computes important positions using an automatic relevance determination (ARD) categorical kernel. We introduce block decomposition and history subsampling techniques to improve the scalability of Bayesian optimization when an input sequence becomes long. Moreover, we develop a post-optimization algorithm that finds adversarial examples with smaller perturbation size. Experiments on natural language and protein classification tasks demonstrate that our method consistently achieves higher attack success rate with significant reduction in query count and modification rate compared to the previous state-of-the-art methods.
Preemptive Image Robustification for Protecting Users against Man-in-the-Middle Adversarial Attacks
Dec 10, 2021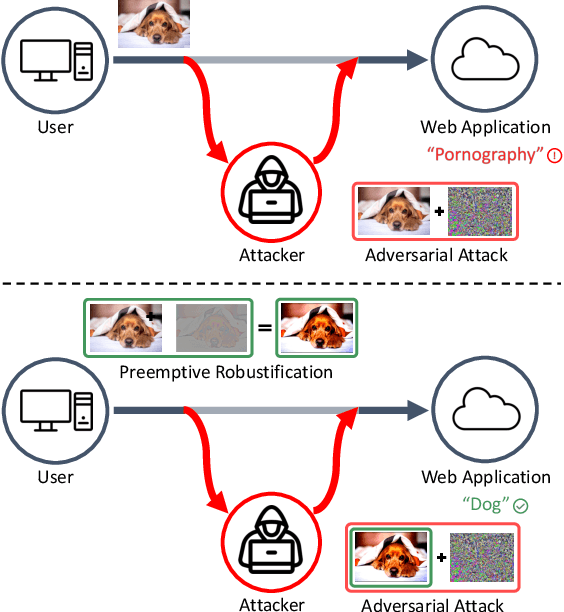
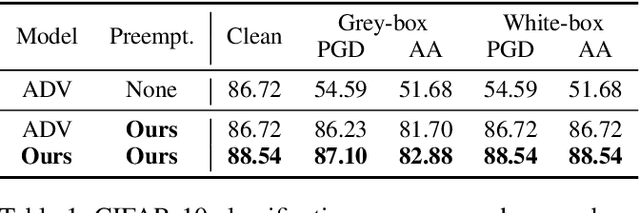
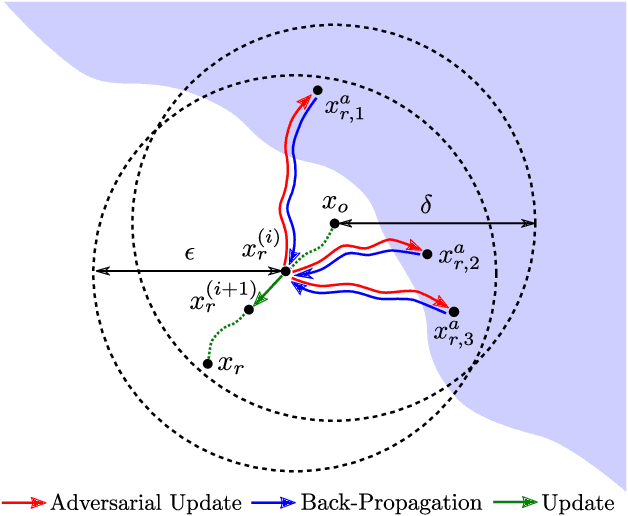
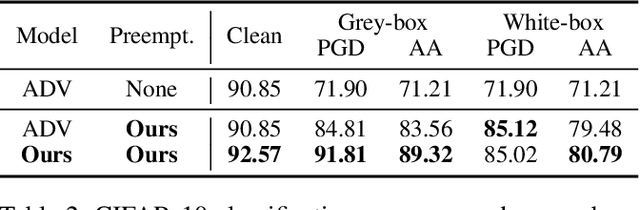
Deep neural networks have become the driving force of modern image recognition systems. However, the vulnerability of neural networks against adversarial attacks poses a serious threat to the people affected by these systems. In this paper, we focus on a real-world threat model where a Man-in-the-Middle adversary maliciously intercepts and perturbs images web users upload online. This type of attack can raise severe ethical concerns on top of simple performance degradation. To prevent this attack, we devise a novel bi-level optimization algorithm that finds points in the vicinity of natural images that are robust to adversarial perturbations. Experiments on CIFAR-10 and ImageNet show our method can effectively robustify natural images within the given modification budget. We also show the proposed method can improve robustness when jointly used with randomized smoothing.
Uncertainty-Based Offline Reinforcement Learning with Diversified Q-Ensemble
Oct 05, 2021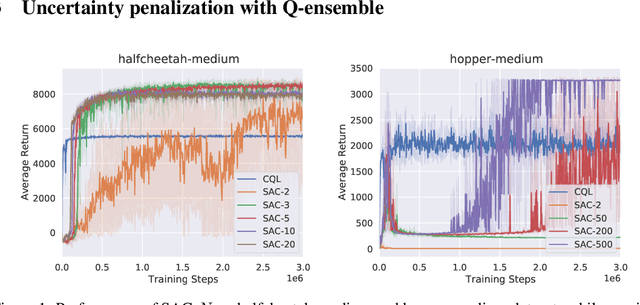
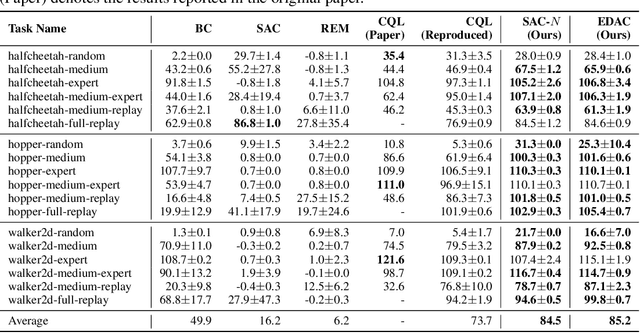
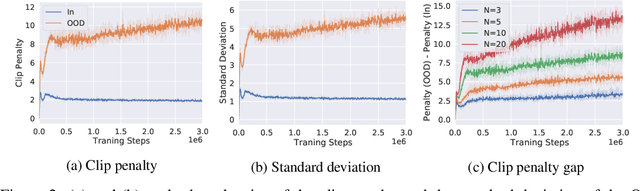
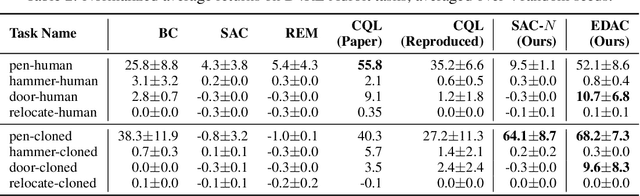
Offline reinforcement learning (offline RL), which aims to find an optimal policy from a previously collected static dataset, bears algorithmic difficulties due to function approximation errors from out-of-distribution (OOD) data points. To this end, offline RL algorithms adopt either a constraint or a penalty term that explicitly guides the policy to stay close to the given dataset. However, prior methods typically require accurate estimation of the behavior policy or sampling from OOD data points, which themselves can be a non-trivial problem. Moreover, these methods under-utilize the generalization ability of deep neural networks and often fall into suboptimal solutions too close to the given dataset. In this work, we propose an uncertainty-based offline RL method that takes into account the confidence of the Q-value prediction and does not require any estimation or sampling of the data distribution. We show that the clipped Q-learning, a technique widely used in online RL, can be leveraged to successfully penalize OOD data points with high prediction uncertainties. Surprisingly, we find that it is possible to substantially outperform existing offline RL methods on various tasks by simply increasing the number of Q-networks along with the clipped Q-learning. Based on this observation, we propose an ensemble-diversified actor-critic algorithm that reduces the number of required ensemble networks down to a tenth compared to the naive ensemble while achieving state-of-the-art performance on most of the D4RL benchmarks considered.
Parsimonious Black-Box Adversarial Attacks via Efficient Combinatorial Optimization
May 16, 2019
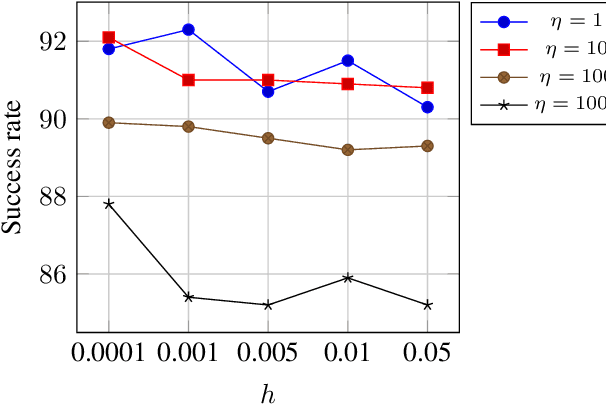

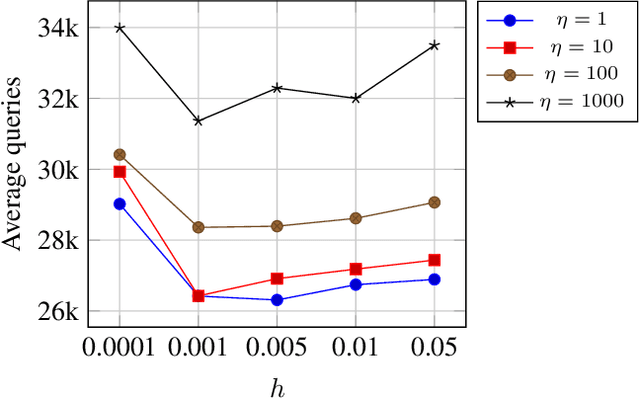
Solving for adversarial examples with projected gradient descent has been demonstrated to be highly effective in fooling the neural network based classifiers. However, in the black-box setting, the attacker is limited only to the query access to the network and solving for a successful adversarial example becomes much more difficult. To this end, recent methods aim at estimating the true gradient signal based on the input queries but at the cost of excessive queries. We propose an efficient discrete surrogate to the optimization problem which does not require estimating the gradient and consequently becomes free of the first order update hyperparameters to tune. Our experiments on Cifar-10 and ImageNet show the state of the art black-box attack performance with significant reduction in the required queries compared to a number of recently proposed methods. The source code is available at https://github.com/snu-mllab/parsimonious-blackbox-attack.