 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Efficient Black-Box Red Teaming via Bayesian Optimization
May 27, 2023



The deployment of large-scale generative models is often restricted by their potential risk of causing harm to users in unpredictable ways. We focus on the problem of black-box red teaming, where a red team generates test cases and interacts with the victim model to discover a diverse set of failures with limited query access. Existing red teaming methods construct test cases based on human supervision or language model (LM) and query all test cases in a brute-force manner without incorporating any information from past evaluations, resulting in a prohibitively large number of queries. To this end, we propose Bayesian red teaming (BRT), novel query-efficient black-box red teaming methods based on Bayesian optimization, which iteratively identify diverse positive test cases leading to model failures by utilizing the pre-defined user input pool and the past evaluations. Experimental results on various user input pools demonstrate that our method consistently finds a significantly larger number of diverse positive test cases under the limited query budget than the baseline methods. The source code is available at https://github.com/snu-mllab/Bayesian-Red-Teaming.
Rethinking Value Function Learning for Generalization in Reinforcement Learning
Oct 18, 2022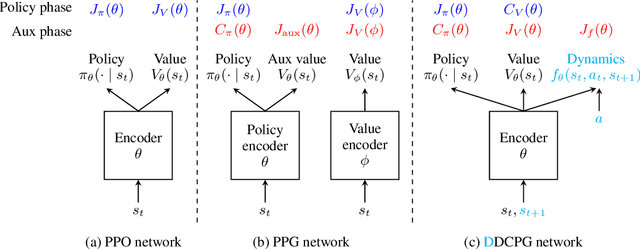
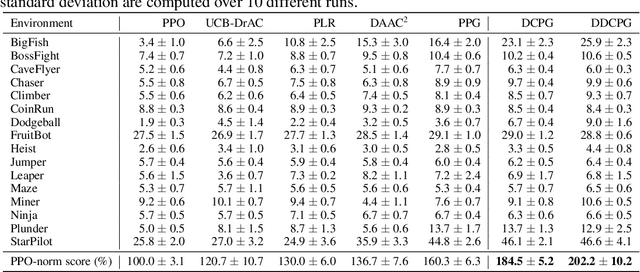
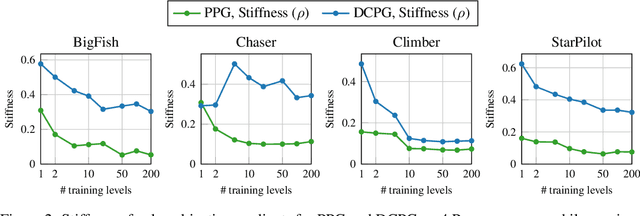

We focus on the problem of training RL agents on multiple training environments to improve observational generalization performance. In prior methods, policy and value networks are separately optimized using a disjoint network architecture to avoid interference and obtain a more accurate value function. We identify that the value network in the multiple-environment setting is more challenging to optimize and prone to overfitting training data than in the conventional single-environment setting. In addition, we find that appropriate regularization of the value network is required for better training and test performance. To this end, we propose Delayed-Critic Policy Gradient (DCPG), which implicitly penalizes the value estimates by optimizing the value network less frequently with more training data than the policy network, which can be implemented using a shared network architecture. Furthermore, we introduce a simple self-supervised task that learns the forward and inverse dynamics of environments using a single discriminator, which can be jointly optimized with the value network. Our proposed algorithms significantly improve observational generalization performance and sample efficiency in the Procgen Benchmark.