 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Multi-Agent Reinforcement Learning Framework for Scalping Trading
Mar 31, 2019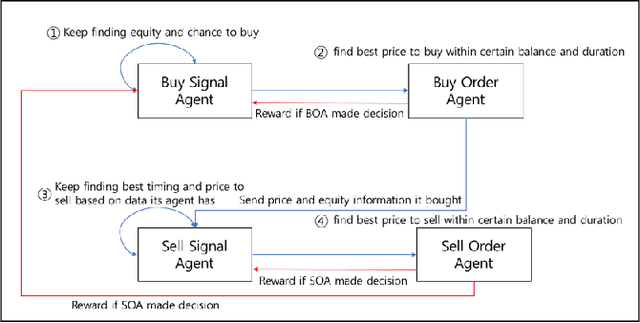


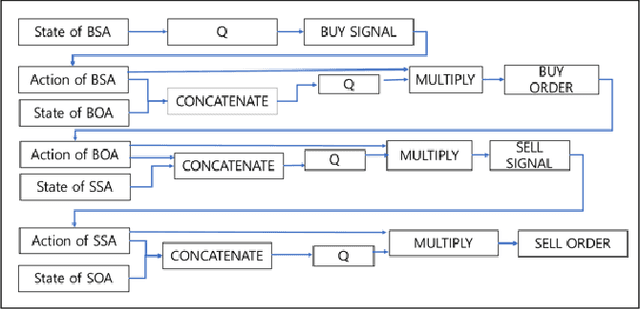
We explore deep Reinforcement Learning(RL) algorithms for scalping trading and knew that there is no appropriate trading gym and agent examples. Thus we propose gym and agent like Open AI gym in finance. Not only that, we introduce new RL framework based on our hybrid algorithm which leverages between supervised learning and RL algorithm and uses meaningful observations such order book and settlement data from experience watching scalpers trading. That is very crucial information for traders behavior to be decided. To feed these data into our model, we use spatio-temporal convolution layer, called Conv3D for order book data and temporal CNN, called Conv1D for settlement data. Those are preprocessed by episode filter we developed. Agent consists of four sub agents divided to clarify their own goal to make best decision. Also, we adopted value and policy based algorithm to our framework. With these features, we could make agent mimic scalpers as much as possible. In many fields, RL algorithm has already begun to transcend human capabilities in many domains. This approach could be a starting point to beat human in the financial stock market, too and be a good reference for anyone who wants to design RL algorithm in real world domain. Finally, weexperiment our framework and gave you experiment progress.
Clear the Fog: Combat Value Assessment in Incomplete Information Games with Convolutional Encoder-Decoders
Nov 30, 2018StarCraft, one of the most popular real-time strategy games, is a compelling environment for artificial intelligence research for both micro-level unit control and macro-level strategic decision making. In this study, we address an eminent problem concerning macro-level decision making, known as the 'fog-of-war', which rises naturally from the fact that information regarding the opponent's state is always provided in the incomplete form. For intelligent agents to play like human players, it is obvious that making accurate predictions of the opponent's status under incomplete information will increase its chance of winning. To reflect this fact, we propose a convolutional encoder-decoder architecture that predicts potential counts and locations of the opponent's units based on only partially visible and noisy information. To evaluate the performance of our proposed method, we train an additional classifier on the encoder-decoder output to predict the game outcome (win or lose). Finally, we designed an agent incorporating the proposed method and conducted simulation games against rule-based agents to demonstrate both effectiveness and practicality. All experiments were conducted on actual game replay data acquired from professional players.