 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchNet: Unsupervised Object Discovery based on Patch Embedding
Paper and Code
Jun 16, 2021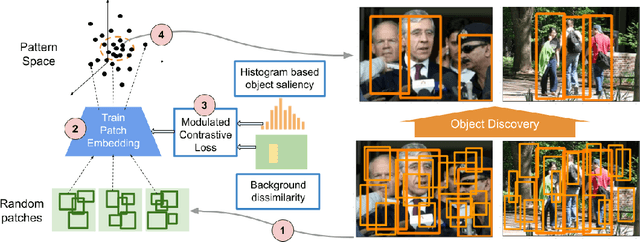
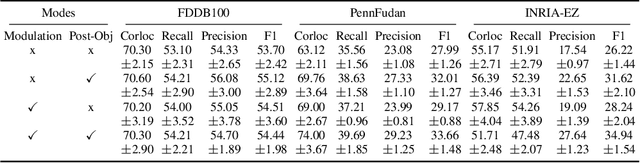
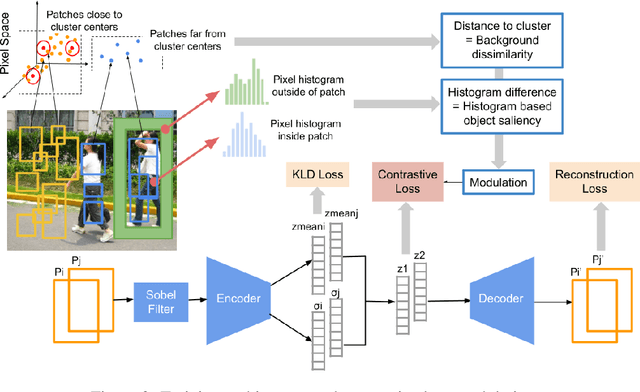
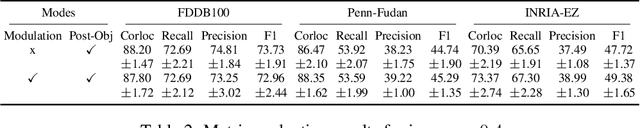
We demonstrate that frequently appearing objects can be discovered by training randomly sampled patches from a small number of images (100 to 200) by self-supervision. Key to this approach is the pattern space, a latent space of patterns that represents all possible sub-images of the given image data. The distance structure in the pattern space captures the co-occurrence of patterns due to the frequent objects. The pattern space embedding is learned by minimizing the contrastive loss between randomly generated adjacent patches. To prevent the embedding from learning the background, we modulate the contrastive loss by color-based object saliency and background dissimilarity. The learned distance structure serves as object memory, and the frequent objects are simply discovered by clustering the pattern vectors from the random patches sampled for inference. Our image representation based on image patches naturally handles the position and scale invariance property that is crucial to multi-object discovery. The method has been proven surprisingly effective, and successfully applied to finding multiple human faces and bodies from natural images.