 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Box: Enhancing Remote Sensing Image Segmentation with Freehand Sketches
Mar 15, 2025This work advances zero-shot interactive segmentation for remote sensing imagery through three key contributions. First, we propose a novel sketch-based prompting method, enabling users to intuitively outline objects, surpassing traditional point or box prompts. Second, we introduce LTL-Sensing, the first dataset pairing human sketches with remote sensing imagery, setting a benchmark for future research. Third, we present LTL-Net, a model featuring a multi-input prompting transport module tailored for freehand sketches. Extensive experiments show our approach significantly improves segmentation accuracy and robustness over state-of-the-art methods like SAM, fostering more intuitive human-AI collaboration in remote sensing analysis and enhancing its applications.
Let Human Sketches Help: Empowering Challenging Image Segmentation Task with Freehand Sketches
Jan 31, 2025



Sketches, with their expressive potential, allow humans to convey the essence of an object through even a rough contour. For the first time, we harness this expressive potential to improve segmentation performance in challenging tasks like camouflaged object detection (COD). Our approach introduces an innovative sketch-guided interactive segmentation framework, allowing users to intuitively annotate objects with freehand sketches (drawing a rough contour of the object) instead of the traditional bounding boxes or points used in classic interactive segmentation models like SAM. We demonstrate that sketch input can significantly improve performance in existing iterative segmentation methods, outperforming text or bounding box annotations. Additionally, we introduce key modifications to network architectures and a novel sketch augmentation technique to fully harness the power of sketch input and further boost segmentation accuracy. Remarkably, our model' s output can be directly used to train other neural networks, achieving results comparable to pixel-by-pixel annotations--while reducing annotation time by up to 120 times, which shows great potential in democratizing the annotation process and enabling model training with less reliance on resource-intensive, laborious pixel-level annotations. We also present KOSCamo+, the first freehand sketch dataset for camouflaged object detection. The dataset, code, and the labeling tool will be open sourced.
Img2CAD: Conditioned 3D CAD Model Generation from Single Image with Structured Visual Geometry
Oct 04, 2024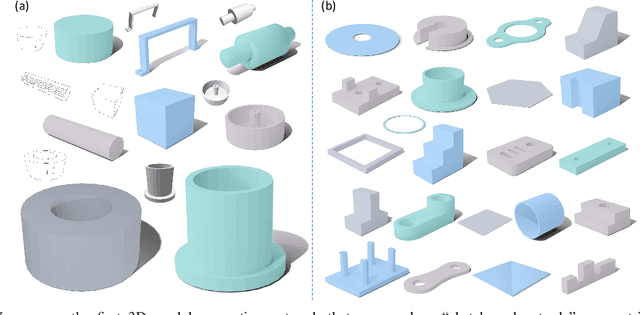
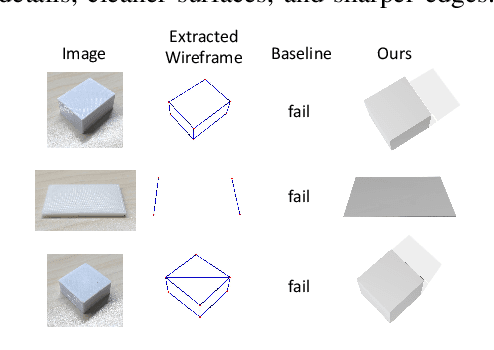


In this paper, we propose Img2CAD, the first approach to our knowledge that uses 2D image inputs to generate CAD models with editable parameters. Unlike existing AI methods for 3D model generation using text or image inputs often rely on mesh-based representations, which are incompatible with CAD tools and lack editability and fine control, Img2CAD enables seamless integration between AI-based 3D reconstruction and CAD software. We have identified an innovative intermediate representation called Structured Visual Geometry (SVG), characterized by vectorized wireframes extracted from objects. This representation significantly enhances the performance of generating conditioned CAD models. Additionally, we introduce two new datasets to further support research in this area: ABC-mono, the largest known dataset comprising over 200,000 3D CAD models with rendered images, and KOCAD, the first dataset featuring real-world captured objects alongside their ground truth CAD models, supporting further research in conditioned CAD model generation.
RESMatch: Referring Expression Segmentation in a Semi-Supervised Manner
Feb 11, 2024Referring expression segmentation (RES), a task that involves localizing specific instance-level objects based on free-form linguistic descriptions, has emerged as a crucial frontier in human-AI interaction. It demands an intricate understanding of both visual and textual contexts and often requires extensive training data. This paper introduces RESMatch, the first semi-supervised learning (SSL) approach for RES, aimed at reducing reliance on exhaustive data annotation. Extensive validation on multiple RES datasets demonstrates that RESMatch significantly outperforms baseline approaches, establishing a new state-of-the-art. Although existing SSL techniques are effective in image segmentation, we find that they fall short in RES. Facing the challenges including the comprehension of free-form linguistic descriptions and the variability in object attributes, RESMatch introduces a trifecta of adaptations: revised strong perturbation, text augmentation, and adjustments for pseudo-label quality and strong-weak supervision. This pioneering work lays the groundwork for future research in semi-supervised learning for referring expression segmentation.
SAM Fails to Segment Anything? -- SAM-Adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shadow, Medical Image Segmentation, and More
May 02, 2023The emergence of large models, also known as foundation models, has brought significant advancements to AI research. One such model is Segment Anything (SAM), which is designed for image segmentation tasks. However, as with other foundation models, our experimental findings suggest that SAM may fail or perform poorly in certain segmentation tasks, such as shadow detection and camouflaged object detection (concealed object detection). This study first paves the way for applying the large pre-trained image segmentation model SAM to these downstream tasks, even in situations where SAM performs poorly. Rather than fine-tuning the SAM network, we propose \textbf{SAM-Adapter}, which incorporates domain-specific information or visual prompts into the segmentation network by using simple yet effective adapters. By integrating task-specific knowledge with general knowledge learnt by the large model, SAM-Adapter can significantly elevate the performance of SAM in challenging tasks as shown in extensive experiments. We can even outperform task-specific network models and achieve state-of-the-art performance in the task we tested: camouflaged object detection, shadow detection. We also tested polyp segmentation (medical image segmentation) and achieves better results. We believe our work opens up opportunities for utilizing SAM in downstream tasks, with potential applications in various fields, including medical image processing, agriculture, remote sensing, and more.