 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing a Cross-Task Grid of Linear Probes to Interpret CNN Model Predictions On Retinal Images
Paper and Code
Jul 23, 2021
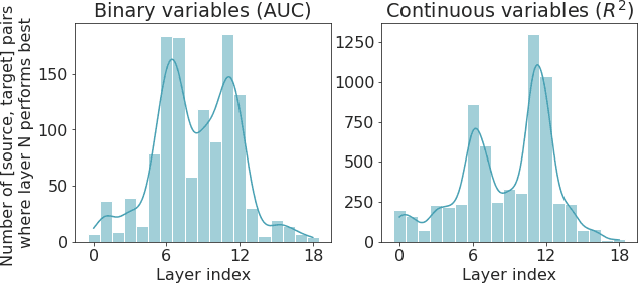


We analyze a dataset of retinal images using linear probes: linear regression models trained on some "target" task, using embeddings from a deep convolutional (CNN) model trained on some "source" task as input. We use this method across all possible pairings of 93 tasks in the UK Biobank dataset of retinal images, leading to ~164k different models. We analyze the performance of these linear probes by source and target task and by layer depth. We observe that representations from the middle layers of the network are more generalizable. We find that some target tasks are easily predicted irrespective of the source task, and that some other target tasks are more accurately predicted from correlated source tasks than from embeddings trained on the same task.