 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Uncertainty Prediction for Medical Second Opinions
Paper and Code
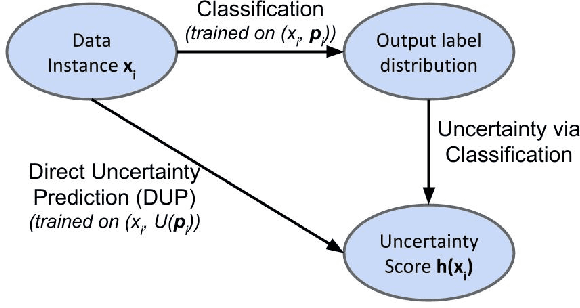

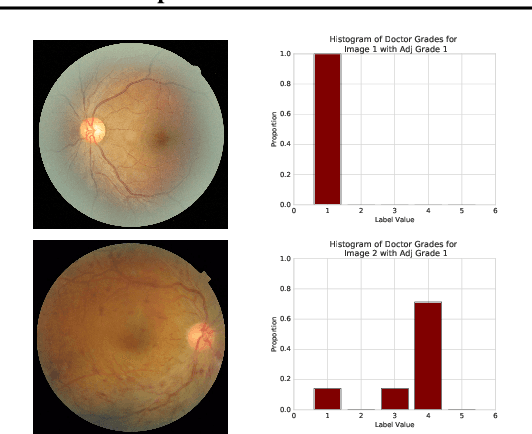

A persistent challenge in the practice of medicine (and machine learning) is the disagreement of highly trained human experts on data instances, such as patient image scans. We study the application of machine learning to predict which instances are likely to give rise to maximal expert disagreement. As necessitated by this, we develop predictors on datasets with noisy and scarce labels. Our central methodological finding is that direct prediction of a scalar uncertainty score performs better than the two-step process of (i) training a classifier (ii) using the classifier outputs to derive an uncertainty score. This is seen in both a synthetic setting whose parameters we can control, and a paradigmatic healthcare application involving multiple labels by medical domain experts. We evaluate these direct uncertainty models on a gold standard adjudicated set, where they accurately predict when an individual expert will disagree with an unknown ground truth. We explore the consequences for using these predictors to identify the need for a medical second opinion and a machine learning data curation application.