 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynCPKL: Harnessing LLMs to Generate Synthetic Data for Commonsense Persona Knowledge Linking
Jul 21, 2024Understanding rich dialogues often requires NLP systems to access relevant commonsense persona knowledge, but retrieving this knowledge is challenging due to complex contexts and the implicit nature of commonsense. This paper presents our approach to the Commonsense Persona Knowledge Linking (CPKL) challenge, addressing the critical need for integrating persona and commonsense knowledge in open-domain dialogue systems. We introduce SynCPKL Pipeline, a pipeline that leverages Large Language Models to generate high-quality synthetic datasets for training commonsense persona knowledge linkers. To demonstrate the efficacy of our approach, we present SynCPKL, a new dataset specifically designed for this task. Our experiments validate the effectiveness of SynCPKL for training commonsense persona knowledge linkers. Additionally, our top-performing model, Derberta-SynCPKL, secured first place in the CPKL challenge by a 16% improvement in F1 score. We released both SynCPKL and Derberta-SynCPKL at https://github.com/irislin1006/CPKL.
Multi-step Joint-Modality Attention Network for Scene-Aware Dialogue System
Jan 17, 2020
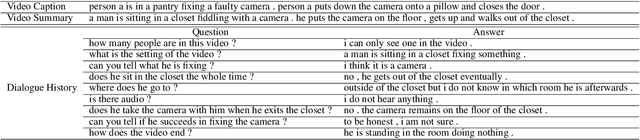

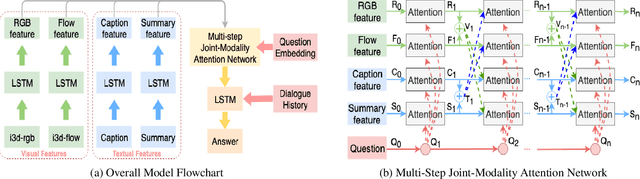
Understanding dynamic scenes and dialogue contexts in order to converse with users has been challenging for multimodal dialogue systems. The 8-th Dialog System Technology Challenge (DSTC8) proposed an Audio Visual Scene-Aware Dialog (AVSD) task, which contains multiple modalities including audio, vision, and language, to evaluate how dialogue systems understand different modalities and response to users. In this paper, we proposed a multi-step joint-modality attention network (JMAN) based on recurrent neural network (RNN) to reason on videos. Our model performs a multi-step attention mechanism and jointly considers both visual and textual representations in each reasoning process to better integrate information from the two different modalities. Compared to the baseline released by AVSD organizers, our model achieves a relative 12.1% and 22.4% improvement over the baseline on ROUGE-L score and CIDEr score.
Entropy-Enhanced Multimodal Attention Model for Scene-Aware Dialogue Generation
Aug 22, 2019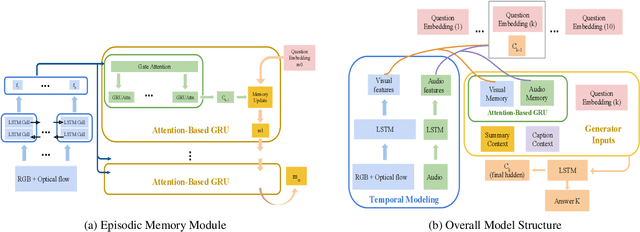
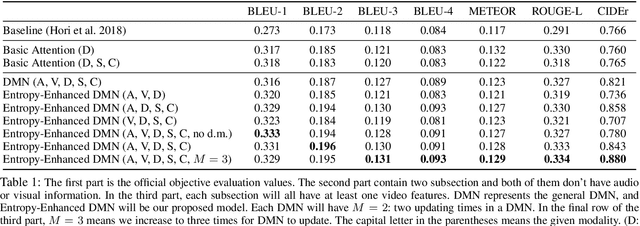

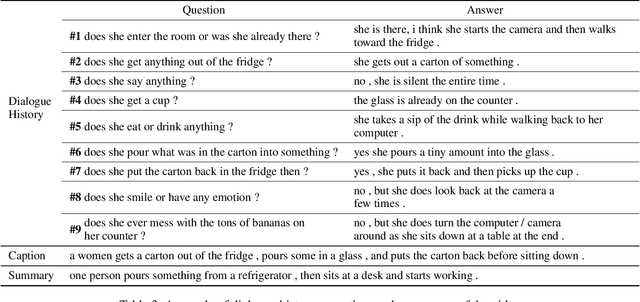
With increasing information from social media, there are more and more videos available. Therefore, the ability to reason on a video is important and deserves to be discussed. TheDialog System Technology Challenge (DSTC7) (Yoshino et al. 2018) proposed an Audio Visual Scene-aware Dialog (AVSD) task, which contains five modalities including video, dialogue history, summary, and caption, as a scene-aware environment. In this paper, we propose the entropy-enhanced dynamic memory network (DMN) to effectively model video modality. The attention-based GRU in the proposed model can improve the model's ability to comprehend and memorize sequential information. The entropy mechanism can control the attention distribution higher, so each to-be-answered question can focus more specifically on a small set of video segments. After the entropy-enhanced DMN secures the video context, we apply an attention model that in-corporates summary and caption to generate an accurate answer given the question about the video. In the official evaluation, our system can achieve improved performance against the released baseline model for both subjective and objective evaluation metrics.