 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-step Joint-Modality Attention Network for Scene-Aware Dialogue System
Paper and Code
Jan 17, 2020
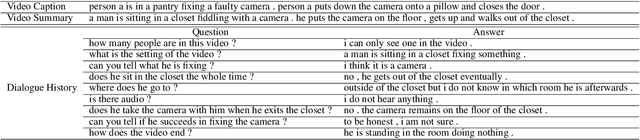

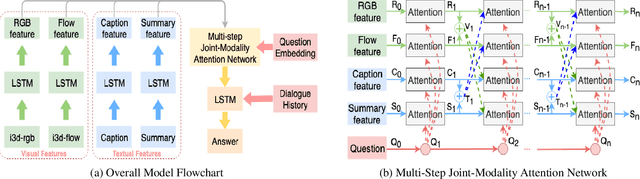
Understanding dynamic scenes and dialogue contexts in order to converse with users has been challenging for multimodal dialogue systems. The 8-th Dialog System Technology Challenge (DSTC8) proposed an Audio Visual Scene-Aware Dialog (AVSD) task, which contains multiple modalities including audio, vision, and language, to evaluate how dialogue systems understand different modalities and response to users. In this paper, we proposed a multi-step joint-modality attention network (JMAN) based on recurrent neural network (RNN) to reason on videos. Our model performs a multi-step attention mechanism and jointly considers both visual and textual representations in each reasoning process to better integrate information from the two different modalities. Compared to the baseline released by AVSD organizers, our model achieves a relative 12.1% and 22.4% improvement over the baseline on ROUGE-L score and CIDEr score.