Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Completeness of Theories
Oct 15, 2019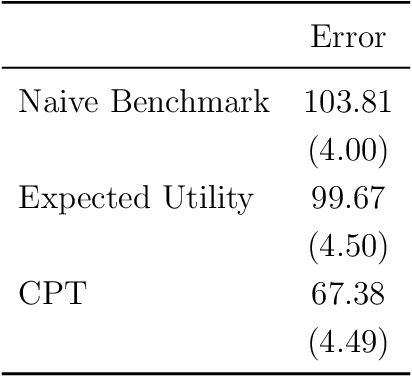
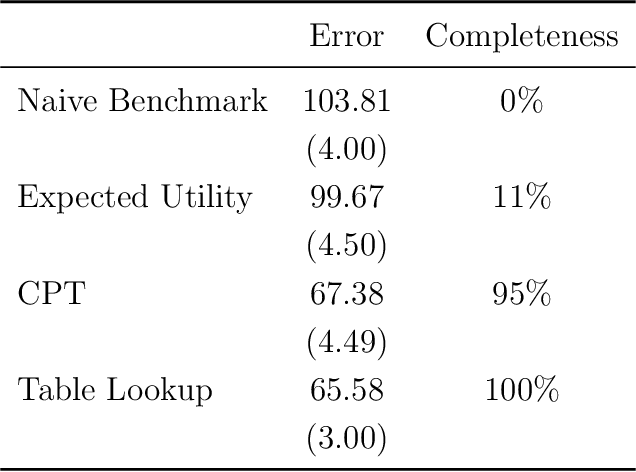

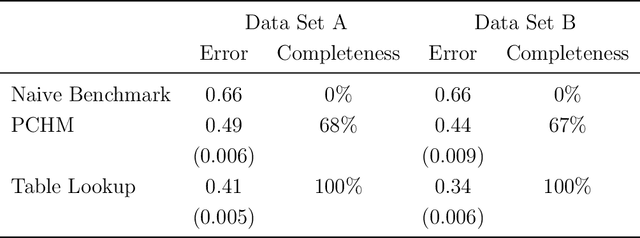
We use machine learning to provide a tractable measure of the amount of predictable variation in the data that a theory captures, which we call its "completeness." We apply this measure to three problems: assigning certain equivalents to lotteries, initial play in games, and human generation of random sequences. We discover considerable variation in the completeness of existing models, which sheds light on whether to focus on developing better models with the same features or instead to look for new features that will improve predictions. We also illustrate how and why completeness varies with the experiments considered, which highlights the role played in choosing which experiments to run.
Via